






Nunchaku Qwen Image 다중 이미지 편집 및 ComfyUI용 합성#
Nunchaku Qwen Image는 ComfyUI를 위한 프롬프트 기반의 다중 이미지 편집 및 합성 워크플로우입니다. 최대 세 개의 참조 이미지를 받아들이고, 이들이 어떻게 혼합되거나 변형되어야 하는지를 지정할 수 있으며, 자연 언어에 의해 안내되는 일관된 결과를 생성합니다. 일반적인 사용 사례로는 주제 병합, 배경 교체, 스타일 및 디테일 전환 등이 포함됩니다.
Qwen 이미지 패밀리를 중심으로 구축된 이 워크플로우는 아티스트, 디자이너 및 창작자에게 정밀한 제어를 제공하면서 빠르고 예측 가능한 결과를 유지합니다. 또한 단일 이미지 편집 경로와 순수 텍스트-이미지 경로를 포함하여 하나의 Nunchaku Qwen Image 파이프라인 내에서 생성, 정제 및 합성을 수행할 수 있습니다.
참고: 중형에서 2XLarge 범위의 머신 유형을 선택하십시오. 2XLarge Plus 또는 3XLarge 머신 유형을 사용하는 것은 지원되지 않으며 실행 실패를 초래합니다.
Comfyui Nunchaku Qwen Image 워크플로우의 주요 모델#
- Nunchaku Qwen Image Edit 2509. 프롬프트 가이드 이미지 편집 및 속성 전환에 최적화된 Edit 조정된 확산/DiT 가중치. 국부적 편집, 객체 교체 및 배경 변경에 강력합니다. 모델 카드
- Nunchaku Qwen Image (base). 소스 사진 없이 창의적 합성을 위한 텍스트-이미지 분기에서 사용되는 기본 생성기. 모델 카드
- Qwen2.5‑VL 7B 텍스트 인코더. 편집 및 생성에 대한 프롬프트를 해석하고 시각적 특징과 정렬하는 멀티모달 언어 모델. 모델 페이지
- Qwen Image VAE. 소스 이미지를 잠재 공간으로 인코딩하고 충실한 색상 및 디테일로 최종 결과를 디코딩하는 변량 오토인코더. 자산
Comfyui Nunchaku Qwen Image 워크플로우 사용 방법#
이 그래프는 동일한 시각적 언어와 샘플링 논리를 공유하는 세 개의 독립적인 경로를 포함하고 있습니다. 여러 이미지를 편집할지, 단일 이미지를 정제할지, 텍스트에서 생성할지에 따라 한 분기씩 사용하십시오.
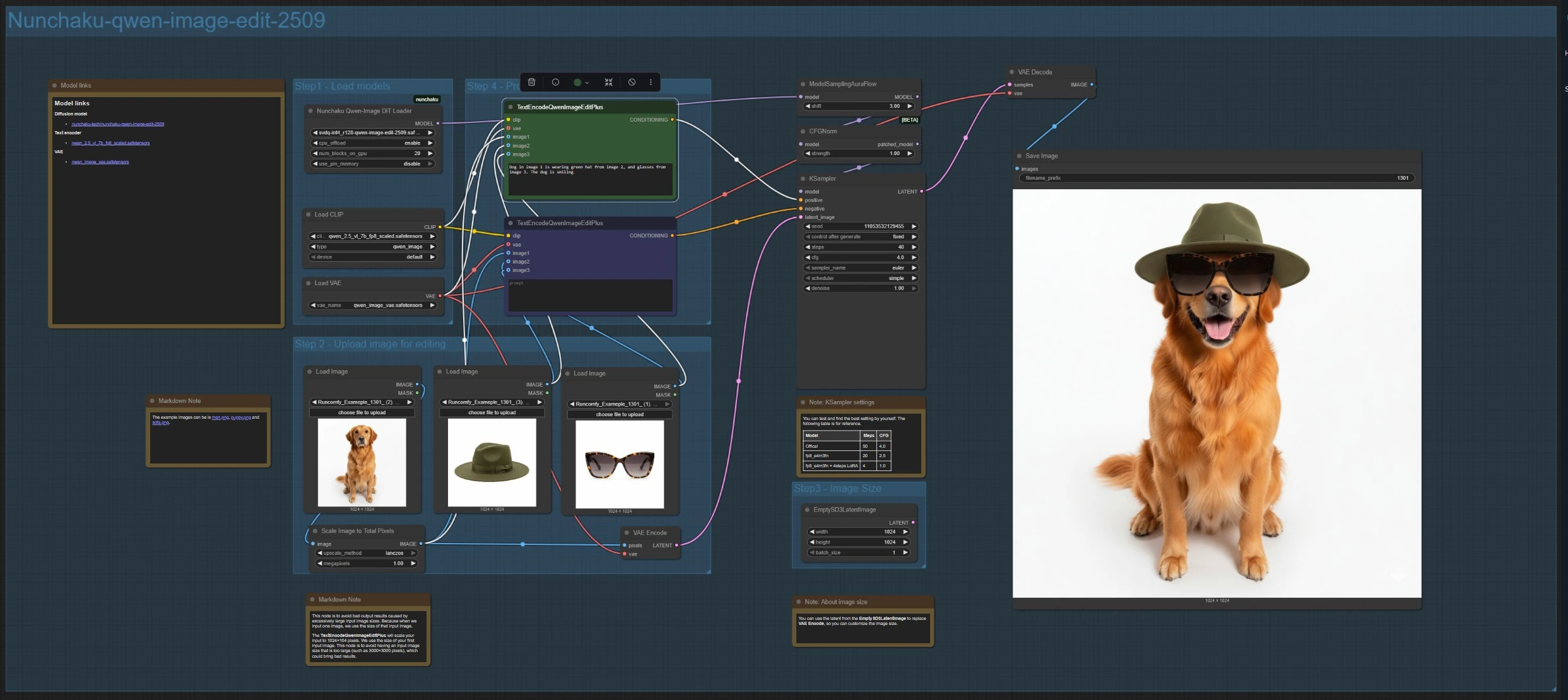
Nunchaku‑qwen‑image‑edit‑2509 (다중 이미지 편집 및 합성)#
이 분기는 NunchakuQwenImageDiTLoader (#115)로 편집 모델을 로드하고, ModelSamplingAuraFlow (#66) 및 CFGNorm (#75)를 통해 라우팅한 다음 KSampler (#3)로 합성합니다. LoadImage (#78, #106, #108)를 사용하여 최대 세 개의 이미지를 업로드하세요. 주요 참조는 VAEEncode (#88)로 인코딩되어 캔버스를 설정하고, ImageScaleToTotalPixels (#93)는 입력을 안정적인 크기 범위로 유지합니다.
TextEncodeQwenImageEditPlus (#111)에 지시사항을 작성하고, 필요하면 페어링된 TextEncodeQwenImageEditPlus (#110)에 제거 또는 제약을 배치하십시오. 예를 들어: “이미지 1의 개는 이미지 2의 녹색 모자와 이미지 3의 안경을 착용합니다.” 커스텀 출력 크기를 원할 경우 EmptySD3LatentImage (#112)로 인코딩된 잠재 공간을 대체할 수 있습니다. 결과는 VAEDecode (#8)로 디코딩되고 SaveImage (#60)로 저장됩니다.
Nunchaku‑qwen‑image‑edit (단일 이미지 정제)#
하나의 이미지에 대해 목표로 한 정리, 배경 변경 또는 스타일 조정을 원할 때 이 옵션을 선택하십시오. 모델은 NunchakuQwenImageDiTLoader (#120)에 의해 로드되고, ModelSamplingAuraFlow (#125) 및 CFGNorm (#123)로 조정되며, KSampler (#127)로 샘플링됩니다. LoadImage (#129)로 사진을 가져오면 ImageScaleToTotalPixels (#130)로 정규화되고 VAEEncode (#131)로 인코딩됩니다.
TextEncodeQwenImageEdit (#121)에 지시사항을 제공하고, TextEncodeQwenImageEdit (#122)에 선택적 반대 지침을 제공하여 요소를 유지하거나 제거하십시오. 이 분기는 VAEDecode (#124)로 디코딩되고 SaveImage (#128)로 파일을 작성합니다.
Nunchaku‑qwen‑image (텍스트-이미지)#
기본 모델로 처음부터 새로운 이미지를 생성하려면 이 분기를 사용하십시오. NunchakuQwenImageDiTLoader (#146)는 ModelSamplingAuraFlow (#138)에 피드합니다. 긍정적 및 부정적 프롬프트를 CLIPTextEncode (#143) 및 CLIPTextEncode (#137)에 입력하십시오. EmptySD3LatentImage (#136)로 캔버스를 설정한 다음 KSampler (#141)로 생성하고, VAEDecode (#142)로 디코딩하며, SaveImage (#147)로 저장합니다.
Comfyui Nunchaku Qwen Image 워크플로우의 주요 노드#
NunchakuQwenImageDiTLoader (#115) 분기에서 사용되는 Qwen 이미지 가중치 및 변형을 로드합니다. 사진 가이드 편집을 위한 편집 모델이나 텍스트-이미지를 위한 기본 모델을 선택하십시오. VRAM이 허용하는 경우, 더 높은 정밀도나 해상도의 변형이 더 많은 디테일을 제공할 수 있으며, 가벼운 변형은 속도를 우선시합니다.
TextEncodeQwenImageEditPlus (#111) 귀하의 지시사항을 해석하고 최대 세 개의 참조에 바인딩하여 다중 이미지 편집을 주도합니다. 어떤 이미지가 어떤 속성을 제공하는지에 대해 명확히 지시하십시오. 명료한 표현을 사용하고 대립되는 목표를 피하여 편집을 집중시키십시오.
TextEncodeQwenImageEditPlus (#110) 다중 이미지 브랜치의 페어링된 부정 또는 제약 인코더로 작동합니다. 나타나지 않기를 원하는 객체, 스타일 또는 아티팩트를 제외하는 데 사용하십시오. 이는 UI 오버레이나 원치 않는 소품을 제거하면서 구성을 보존하는 데 자주 도움이 됩니다.
TextEncodeQwenImageEdit (#121) 단일 이미지 편집 분기의 긍정적 지시 사항입니다. 원하는 결과, 표면 품질 및 구성을 명확한 용어로 설명하십시오. 장면 및 변경 사항을 지정하는 한 세 문장 내외로 목표하십시오.
TextEncodeQwenImageEdit (#122) 단일 이미지 편집 분기의 부정적 또는 제약 프롬프트입니다. 피할 항목 또는 특성을 나열하거나 소스 이미지에서 제거할 요소를 설명하십시오. 이는 잘못된 텍스트, 로고 또는 인터페이스 요소를 청소하는 데 유용합니다.
ImageScaleToTotalPixels (#93) 과도한 입력이 결과를 불안정하게 만드는 것을 방지하기 위해 목표 총 픽셀 수로 스케일링합니다. 합성 전에 서로 다른 소스 해상도를 조화시키는 데 사용하십시오. 소스 간의 일관되지 않은 선명도가 눈에 띄면 여기에서 효과적인 크기를 더 가깝게 만드십시오.
ModelSamplingAuraFlow (#66) Qwen 이미지 모델에 맞춰 조정된 DiT/플로우 매칭 샘플링 스케줄을 적용합니다. 출력이 어둡거나 흐릿하거나 구조가 부족하면 스케줄의 시프트를 증가시켜 전체 톤을 안정화하십시오; 평평해 보일 때는 세부사항을 더하기 위해 시프트를 줄이십시오.
KSampler (#3) 속도, 충실도 및 확률적 다양성을 균형 있게 유지하는 주요 샘플러입니다. 일관성과 창의성에 대한 단계를 조정하고, 샘플러 방법을 선택하고, 실행 간 정확한 재현성을 원할 때 시드를 고정하십시오.
CFGNorm (#75) 높은 가이드 스케일에서 과포화 또는 대비 폭발을 줄이기 위해 분류기 자유 가이던스를 정규화합니다. 제공된 경로에 그대로 두십시오; 프롬프트를 반복하는 동안 안정적인 색상 및 노출을 유지하는 데 도움이 됩니다.
선택적 추가 기능#
- 최상의 다중 이미지 결과를 위해 유사한 원근과 조명의 소스를 선택하십시오; Nunchaku Qwen Image 편집 모델은 그러면 기하학을 수정하기보다는 콘텐츠에 집중합니다.
- 순서에 따라 소스를 참조하고(“이미지 1”, “이미지 2”, “이미지 3”) 어떤 속성이 어디로 전송되는지 명확하게 하십시오.
- 출력이 어둡거나 흐릿하게 치우칠 때,
ModelSamplingAuraFlow시프트를 위로 조정하십시오; 추가 텍스처가 필요할 때는 약간 낮은 시프트를 시도하십시오. - 특정 해상도를 설정하려면 사용 중인 분기에서
EmptySD3LatentImage로 인코딩된 잠재 공간을 교체하십시오. - UI 텍스트, 워터마크 또는 원치 않는 객체를 제거하려면 부정적 프롬프트를 사용하여 세부 스타일링에 투자하기 전에 Nunchaku Qwen Image 편집이 처음부터 깔끔하게 유지되도록 하십시오.
감사의 말#
이 워크플로우는 다음 작업 및 리소스를 구현하고 기반으로 합니다. 우리는 그들의 기여와 유지보수에 대해 Nunchaku의 Qwen-Image 워크플로우(ComfyUI-nunchaku)에 감사를 표합니다. 권위 있는 세부사항은 아래에 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- Nunchaku/Qwen-Image
- GitHub: nunchaku-tech/ComfyUI-nunchaku
- Hugging Face: nunchaku-tech/nunchaku-qwen-image
- arXiv: SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
- 문서 / 릴리스 노트: Nunchaku Qwen Image Source
참고: 참조된 모델, 데이터셋 및 코드의 사용은 해당 저자 및 유지보수자가 제공한 각각의 라이선스 및 조건에 따릅니다.




