
ComfyUI를 위한 LTX 2.3 ID-LoRA 말하는 비디오 워크플로우#
이 워크플로우는 단일 얼굴 이미지, 짧은 음성 클립, 프롬프트를 완전히 동기화된 말하는 비디오로 변환합니다. LTX-2.3에 기반하여 오디오와 비주얼을 하나의 확산 과정에서 융합하고, 참조 이미지의 인물이 모든 프레임에서 일관되게 유지되도록 In-Context LoRA 정체성 어댑터를 추가합니다. LTX 2.3 ID-LoRA는 아바타, 가상 호스트, 립싱크, 유사성, 프롬프트 제어가 한 번에 정렬되어야 하는 모든 시나리오에 이상적입니다.
세 가지를 제공합니다: 참조 이미지, 한두 문장의 오디오, 외모와 성능을 설명하는 텍스트 프롬프트. LTX 2.3 ID-LoRA 경로는 정체성을 처리하는 반면, 경량 오디오 전처리기는 더 강한 입술 신호를 위해 음성 명료성을 향상시킵니다. 결과는 정체성을 보존하면서 동기화된 음성을 가진 일관된 비디오로, 주제별 훈련이 필요하지 않습니다.
Comfyui LTX 2.3 ID-LoRA 워크플로우의 주요 모델#
- Lightricks LTX-2.3 22B 기본 체크포인트. 텍스트, 이미지, 오디오 조건에서 동기화된 프레임과 소리를 생성하는 오디오-비디오 공동 기반 모델입니다. 이 ComfyUI 파이프라인에서 사용되는 핵심 생성기입니다. 모델 카드
- LTX-2.3 증류 LoRA 384. 기본 모델에 증류 지침을 적용하여 품질을 희생하지 않고 샘플링을 안정화하고 가속화하는 공식 LoRA 어댑터입니다. 이 워크플로우에서 두 번째 단계 모델로 플러그인됩니다. LTX-2.3 페이지의 체크포인트 테이블을 참조하세요. 모델 카드
- LTX-2.3 공간 업스케일러 x2. 디코딩 전에 공간 세부 사항을 높이기 위해 샘플러 서브그래프 내에서 사용되는 잠재 공간 업스케일러로, 최종 비디오에서 얼굴과 가장자리 충실도를 향상시킵니다. 모델 카드
- LTX-2.3 용 Gemma 3 12B Instruct 텍스트 인코더. 스타일, 장면 및 성능을 구동하는 텍스트 조건을 제공합니다. 이 워크플로우는 ComfyUI에 패키지된 Gemma 3 인코더를 사용합니다. Comfy-Org 텍스트 인코더
- 비디오 및 오디오용 LTX-2.3 VAE. 모델이 생성한 시각적 및 음향 잠재를 이미지와 파형으로 디코딩하는 목적별 VAE입니다. 호환 bf16 빌드는 그래프에서 참조됩니다. 예제 소스: 비디오 VAE · 오디오 VAE
- Mel-Band RoFormer 음성 분리용. 모델이 음절과 입 모양을 더 신뢰할 수 있도록 참조 오디오에서 깨끗한 음성을 추출하는 선택적 전처리기입니다. 논문 · ComfyUI 노드
- LTX 2.3 ID-LoRA (IC-LoRA). 참조 이미지의 얼굴을 향해 생성기를 편향시키면서 프롬프트 및 음성 신호를 존중하는 말하는 비디오 사용을 위해 훈련된 In-context 정체성 LoRA입니다. Lightricks는 LTX-2.3의 모델 페이지에서 LoRA 및 IC-LoRA 사용을 문서화합니다. 모델 카드
Comfyui LTX 2.3 ID-LoRA 워크플로우 사용 방법#
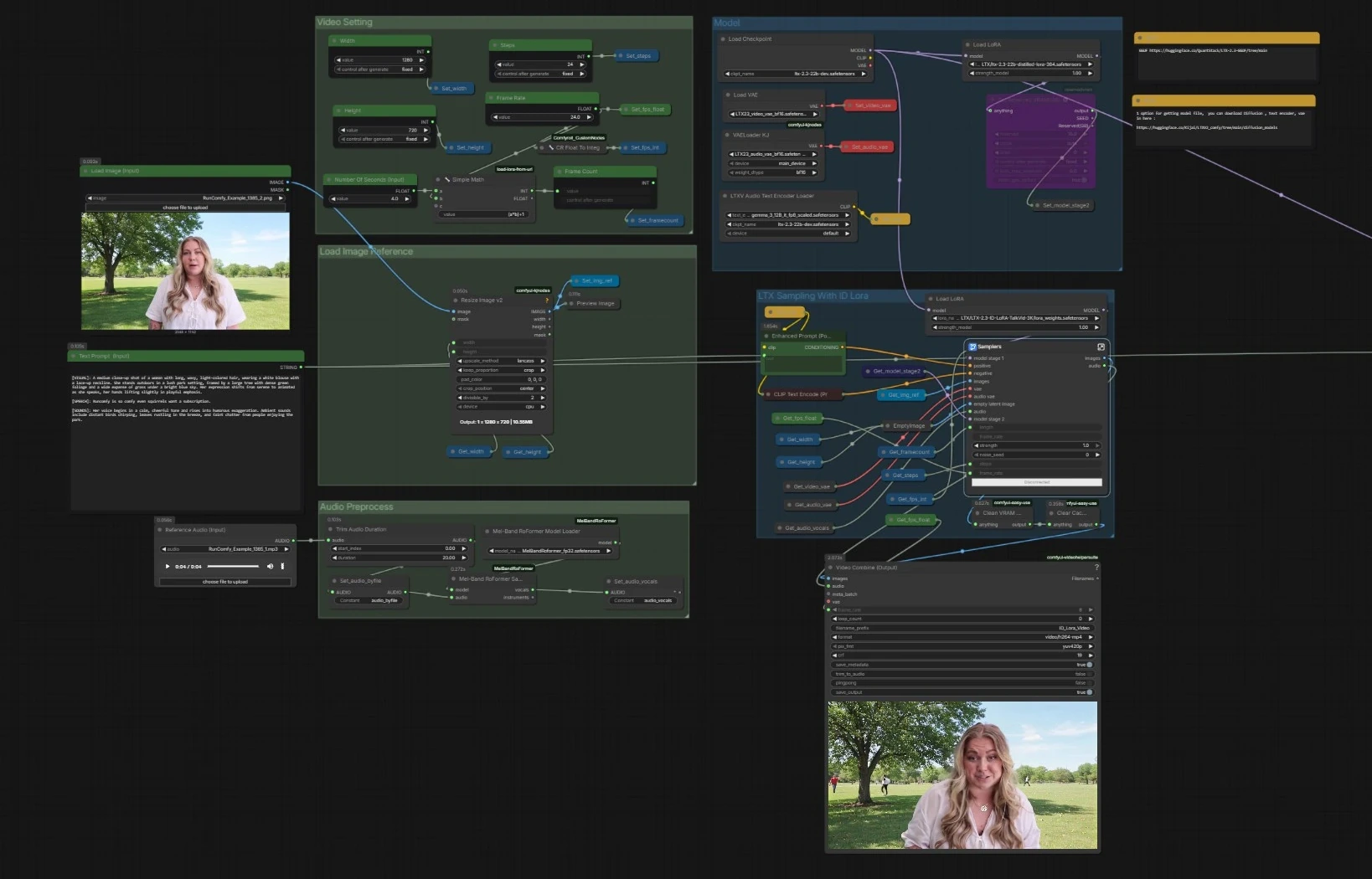
전체 흐름. 파이프라인은 텍스트 인코더와 VAE와 함께 LTX-2.3 기본을 로드하고, 이미지를 준비하고 오디오를 준비한 다음, 텍스트, 얼굴 참조, 음성 트랙을 결합하여 동기화된 프레임과 음성을 생성하는 두 단계 LTX 샘플러를 실행합니다. ID-LoRA가 없는 병렬 샘플러가 빠른 비교를 위해 포함되어 있습니다. 최종 프레임과 오디오가 MP4로 결합됩니다.
- 모델
- 그래프는
CheckpointLoaderSimple(#5493)로 기본 체크포인트를 로드하고,LTXAVTextEncoderLoader(#5494)로 Gemma 기반 텍스트 인코더를, 비디오VAELoader(#5651) 및 오디오VAELoaderKJ(#5649)를 전용 VAE로 로드합니다. 그런 다음 두 어댑터를 적용합니다: 공식 증류 LoRA는 2단계 모델을 형성하고, LTX 2.3 ID-LoRA는LoraLoaderModelOnly(#5573)를 통해 정체성 조건을 설정합니다. - 이 단계는 생성기가 프롬프트를 이해하고, 올바른 디코딩 스택을 가지고 있으며, 효율성 가이드와 정체성 편향으로 준비되도록 합니다.
- 일반적으로 여기에서 체크포인트 또는 LoRA를 교체하는 것 외에는 수정하지 않습니다.
- 그래프는
- 비디오 설정
- 출력 차원, 프레임 속도, 단계 및 길이를 제어합니다.
Width(#5284),Height(#5286), 및Frame Rate(#5289)는 초에서 총 프레임을 계산하는 작은 유틸리티로 피드되어 오디오와 비디오의 타이밍을 일관되게 유지합니다. - 설정은 한 번 저장되고 모든 다운스트림 노드에 의해 읽어져 두 샘플러와 멀티플렉서가 정렬되도록 합니다.
- 다른 비율, 부드러움 또는 지속 시간을 원할 때 먼저 이 값을 조정하십시오.
- 출력 차원, 프레임 속도, 단계 및 길이를 제어합니다.
- 이미지 참조 로드
Load Image (Input)(#5525)를 통해 단일 명확한 얼굴 이미지를 제공합니다. 선택한 출력에 맞게ImageResizeKJv2(#5280)로 이미지가 조정됩니다.- 이 전처리된 이미지는 LTX 2.3 ID-LoRA 단계에서 정체성의 앵커가 되어 유사성과 샷 구성을 안내합니다.
- 최상의 결과를 위해 잘 조명된 정면 사진을 사용하고 모션 블러가 최소화된 이미지를 사용하세요.
- 오디오 전처리
Reference Audio (Input)(#5652)를 사용하여 짧은 WAV 또는 MP3를 삽입합니다. 필요한 경우 클립이 잘리고MelBandRoFormerSampler(#5473)에 전달되어 음성을 분리합니다.- 깨끗한 음성은 모델이 정확한 입술 움직임과 말하는 리듬을 위한 음소와 타이밍을 추론하는 데 도움이 됩니다.
- 오디오가 이미 음성만 있는 경우 분리를 건너뛰고 직접 피드할 수 있습니다.
- ID LoRA와 함께 LTX 샘플링
- 이것이 주요 경로입니다. 샘플러 서브그래프 (
Samplers(#5278))는Enhanced Prompt (Positive)(#5174)에서 긍정적인 프롬프트와 부정적인 리스트, 얼굴 참조, 음성 트랙을 LTX-2.3의 AV 잠재 파이프라인을 통해 혼합합니다. LTXVReferenceAudio는 움직임을 음성과 정렬하고,LTXVImgToVideoInplace는 얼굴 이미지를 잠재에 앵커로 주입합니다. LTX 2.3 ID-LoRA 어댑터는 생성기를 주제의 정체성을 향해 조종합니다.- 이 단계는 디코딩 전에 세부 사항을 높이기 위한 내부 잠재 업스케일러를 포함합니다. 프레임과 동기화된 오디오 스트림을 출력합니다.
- 이것이 주요 경로입니다. 샘플러 서브그래프 (
- ID LoRA 없이 LTX 샘플링
- 동일한 조건을 실행하지만 ID-LoRA 어댑터 없이 실행되는 미러드 샘플러 (
Samplers(#5643))입니다. A/B 검사를 위해 또는 참조 정체성에서 더 많은 자유를 원할 때 사용하세요. - 그 외 모든 것은 동일하게 유지되므로, 눈에 띄는 차이는 정체성 조건에만 기인합니다.
- 이 경로는 빠른 초안이나 창의적인 출발점에 유용할 수 있습니다.
- 동일한 조건을 실행하지만 ID-LoRA 어댑터 없이 실행되는 미러드 샘플러 (
- 비디오 결합 및 출력
Video Combine (Output)(#5218)으로 프레임과 생성된 오디오를 MP4로 결합합니다. 프레임 속도는 전역 설정에서 가져오므로, 움직임과 립싱크가 샘플러의 타이밍과 일치합니다.- 보조
Video Combine(#5645)은 ID-LoRA 없는 분기를 미리 봅니다. 비교를 위해 유용합니다. - 워크플로우는 긴 세션에서 VRAM을 안정적으로 유지하기 위해 실행 간 캐시를 청소합니다.
Comfyui LTX 2.3 ID-LoRA 워크플로우의 주요 노드#
LoraLoaderModelOnly(#5573)- 얼굴 정체성을 보존하는 LTX 2.3 ID-LoRA를 로드합니다. 더 많은 창의적 변화를 원하면 가중치를 줄이고, 유사성을 더 강하게 잠그려면 증가시킵니다. 프롬프트 강도와 신중하게 짝지어 정체성과 스타일이 경쟁하지 않도록 하세요. 참조: LTX-2.3 LoRA 사용법은 모델 페이지에서 확인하세요. 모델 카드
LTXVReferenceAudio(#5589)- 참조 오디오를 음절 타이밍, 억양 및 입 모양을 위한 조건으로 변환합니다. 깨끗한 음성을 피드하여 최상의 정렬을 얻으세요. 펌핑 소리나 비트가 맞지 않는 발음이 들리면, 강도를 높이기보다는 클립을 짧게 하거나 단순화하세요.
LTXVImgToVideoInplace(#5245, 나중에 사용됨)- 얼굴 이미지를 잠재 비디오 스트림에 공간적 우선으로 주입합니다. 이미지 강도 제어는 사진에 대한 충실도와 움직임 자유도를 균형 잡습니다. 강한 정체성과 자연스러운 움직임을 위해 이미지 강도를 중간으로 유지하고 ID-LoRA에 유사성을 맡기세요.
LTXVConditioning(#5621)- LTX 샘플러를 위한 텍스트 조건과 타이밍 신호를 패키지합니다. 프레임 속도 입력이 출력 프레임 속도와 일치하도록 하여 모션 필드와 음소 타이밍이 일관성을 유지합니다.
VHS_VideoCombine(#5218)- 프레임과 오디오를 최종 파일로 결합합니다. 오디오가 프레임보다 약간 길면, 여기에서 트리밍을 활성화하여 검은 꼬리가 이어지지 않게 하세요. 플랫폼 호환성을 위해 기본 H.264 설정을 유지하세요. 노드 참조: ComfyUI-VideoHelperSuite
MelBandRoFormerSampler(#5473)- Mel-band 변환기를 사용하여 음악에서 음성을 분리하여 생성기가 음성에 잠기도록 합니다. 시빌런트가 번지거나 파열음이 튀면, 동일한 가족의 다른 모델 파일을 시도하거나 입력 음량을 줄이세요. 배경 읽기: arXiv
선택적 추가 기능#
- LTX-2.3의 가장 안정적인 생성을 위해 너비와 높이를 32로 나누어 떨어지게 하고, Lightricks에서 문서화한 대로 8n + 1의 프레임 수를 선택하세요. 모델 카드
- 참조 이미지를 프롬프트와 일치시키세요. 실외 조명을 설명하면서 실내 사진을 제공하면, 정체성은 유지될 수 있지만 색상과 음영이 프롬프트와 싸울 수 있습니다.
- 자연스러운 속도로 오디오를 2에서 8초 제공하세요. 과도하게 압축되거나 잔향이 있는 클립은 음성 분리 후에도 립싱크 충실도를 감소시킵니다.
- 얼굴이 흐려지면, 이미지 강도를 약간 낮추고 LTX 2.3 ID-LoRA에 더 의존하세요. 얼굴이 너무 많이 떠돌면, 반대로 하세요.
- 긴 테이크의 경우 동일한 시드와 전역 설정을 공유하는 세그먼트로 생성하고, 필요한 경우 비디오 편집에서 클립을 결합하세요.
참조 및 유용한 저장소#
- LTX-2.3 오픈 가중치 및 노트: Hugging Face 모델 페이지
- LTX 비디오용 공식 ComfyUI 노드: Lightricks/ComfyUI-LTXVideo
- LTX-2 코드베이스 및 논문: Lightricks/LTX-Video · arXiv
- ComfyUI의 LTX용 Gemma 3 12B IT 인코더: Comfy-Org/ltx-2 텍스트 인코더
- Mel-Band RoFormer 배경: arXiv
감사의 말#
이 워크플로우는 다음 작업 및 리소스를 구현하고 구축합니다. 우리는 LTX 2.3 ID-LoRA Source의 기여와 유지 관리에 대해 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하세요.
리소스#
- LTX 2.3 ID-LoRA Source
- 문서 / 릴리스 노트: YouTube @Benji’s AI Playground
참고: 참조된 모델, 데이터 세트 및 코드의 사용은 해당 작성자 및 유지 관리자가 제공하는 라이선스 및 조건을 따릅니다.
