
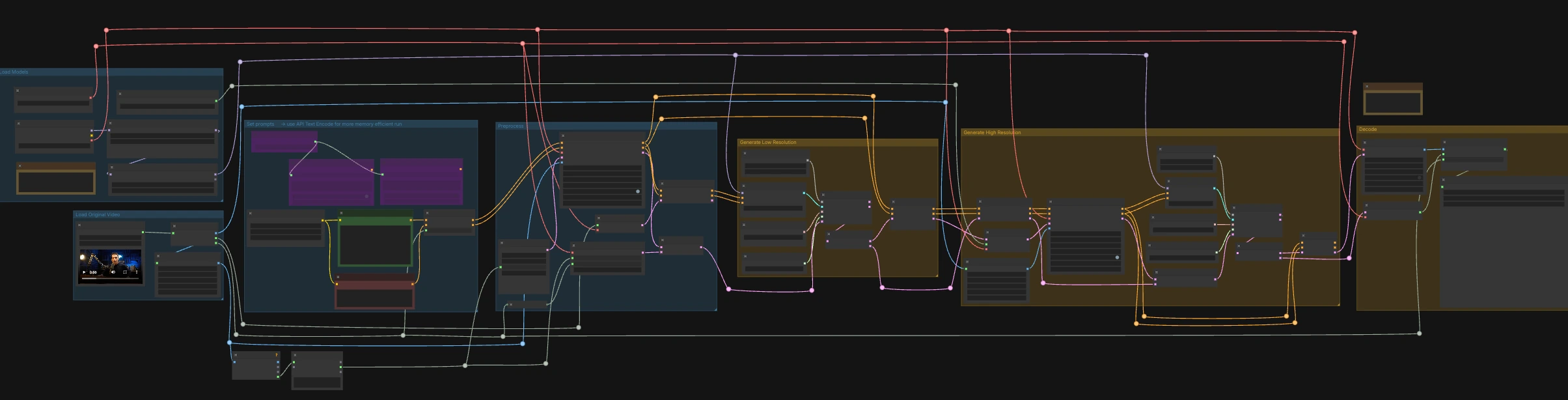
LTX-2.3 ICLoRA LipDub for ComfyUI#
LTX-2.3 ICLoRA LipDub는 두 단계로 구성된 비디오 및 오디오 제어 ComfyUI 워크플로우로, 말하는 사람을 더빙하면서 정체성과 움직임을 일관되게 유지합니다. Lightricks LTX-2.3 텍스트 및 비디오 컨디셔닝을 LipDub IC-LoRA와 결합하여 제공된 말에 입 모양을 정확히 맞추고, 더 높은 해상도로 결과를 정제하여 선명한 세부 사항을 제공합니다. 이 그래프는 표준화된 입력/출력 이름으로 RunComfy에 준비되어 있어 미디어를 교체하고 실행을 신뢰성 있게 반복할 수 있습니다.
이 ComfyUI LTX-2.3 ICLoRA LipDub 워크플로우는 다국어 더빙, 재구성 또는 ADR과 같은 수정을 필요로 하면서 원래의 성능을 유지하려는 창작자에게 이상적입니다. 이미 목표 언어의 말을 포함한 소스 비디오를 제공하고, 장면과 인물이 말해야 하는 내용을 설명하면 워크플로우가 동기화된 시각 및 오디오를 합성하여 완성된 클립을 제공합니다.
Comfyui LTX-2.3 ICLoRA LipDub 워크플로우의 주요 모델#
- LTX-2.3 22B 기본 비디오 모델. 비디오를 생성하고 프롬프트가 외형, 동작, 스타일을 어떻게 조정하는지를 관리하는 기반 확산 모델입니다.
- LTX-2.3 IC-LoRA LipDub. 제공된 말을 따라 입 모양을 음소에 맞추면서 정체성과 머리 움직임을 보존하도록 모델을 조건화하는 립 더빙에 특화된 LoRA입니다. 모델 카드
- LTX-2.3 Audio VAE. 입력된 말을 오디오 잠재 변수로 인코딩하여 텍스트 컨디셔닝에 주입하고 나중에 파형으로 다시 디코딩하여 타이밍이 프레임에 고정되도록 합니다.
- LTX-2.3 Spatial Upscaler x2. 고해상도 정제 단계 전에 비디오 잠재 변수를 더 높은 공간 해상도로 업스케일하여 텍스처를 개선하면서 동작을 변경하지 않습니다.
- LTX-2.3 Distilled LoRA (384). 기본 체크포인트와 함께 사용하여 세부 사항과 시간적 안정성을 향상시키지만 참조 프레임에 과적합하지 않는 강화 LoRA입니다.
Comfyui LTX-2.3 ICLoRA LipDub 워크플로우 사용법#
이 워크플로우는 오디오에 타이밍과 입 모양을 고정하는 저해상도 단계와, 동기화를 유지하면서 세부 사항을 정제하고 업스케일하는 고해상도 단계로 구성됩니다. 이미 원하는 말을 포함한 소스 비디오를 로드하고, 인물이 말해야 하는 텍스트 라인을 작성하세요.
원본 비디오 로드#
LoadVideo (#5002) 노드는 오디오가 포함된 소스 클립을 가져옵니다. GetVideoComponents (#5010)는 프레임, 오디오, 프레임 속도를 추출하며, 프레임 속도는 그래프 전체에서 공유되어 비디오와 오디오가 정렬됩니다. 두 개의 리사이저, Resize Image/Mask (s1 size) (#5009)와 Resize Image/Mask (s2 size) (#5003)는 저해상도 및 고해상도 단계에 맞게 작업 이미지 스트림을 준비합니다. 프레임 수는 샘플러 친화적인 길이로 측정 및 반올림되어 디코딩이 안정적으로 유지됩니다.
모델 로드#
CheckpointLoaderSimple (#5017)은 그래프에서 사용되는 LTX-2.3 22B 기본 모델과 VAE를 로드합니다. 두 개의 로더, LoraLoaderModelOnly (#5018)와 LTXICLoRALoaderModelOnly (#5012)는 기본 모델 위에 증류된 LoRA와 IC-LoRA LipDub을 추가하여 생성기가 말을 따르면서 정체성을 보존하도록 합니다. LTXVAudioVAELoader (#4010)는 사운드트랙을 인코딩/디코딩하기 위한 오디오 VAE를 제공합니다. IC-LoRA 로더의 latent_downscale_factor 출력은 여기에서 의도적으로 사용되지 않으며, 이는 LipDub 훈련이 풀 해상도 참조 프레임을 가정하기 때문입니다.
프롬프트 설정#
장면 설명과 정확한 대사를 CLIP Text Encode (Positive Prompt) (#2483)에 작성하세요. CLIP Text Encode (Negative Prompt) (#2612)를 사용하여 원치 않는 특성이나 인공물을 최소화하세요. 이러한 것들은 비디오 도메인에 맞게 컨디셔닝을 조정하고 프레임 속도 컨텍스트를 전달하는 LTXVConditioning (#1241)에 입력됩니다. 낮은 VRAM 실행을 위해, 그래프에는 API 기반 인코더 (🅛🅣🅧 Gemma API Text Encode - POSITIVE (#4980) 및 ... - NEGATIVE (#4981))가 포함되어 있으며 LTX API KEY 문자열 (#4979)에 의해 게이트됩니다; 기본 배선은 로컬 인코더를 사용합니다.
전처리#
LTXVAudioVAEEncode (#5005)는 소스 말을 오디오 잠재 변수로 변환하고, LTXVSetAudioRefTokens (#5006)는 그 잠재 변수를 텍스트 컨디셔닝에 주입하여 생성기가 타이밍과 음소를 "듣게" 합니다. EmptyLTXVLatentVideo (#3059)는 올바른 공간 크기와 입력에 맞게 정렬된 프레임 수로 플레이스홀더 비디오 잠재 변수를 준비합니다. LTXAddVideoICLoRAGuide (#5004)는 s1 프레임을 사용하여 IC-LoRA 참조 지침을 첨부하여 샘플링 전에 정체성과 입 주변 주의를 설정합니다.
저해상도 생성#
표준 확산 루프는 CFGGuider (#4828), KSamplerSelect (#4831), ManualSigmas (#4984), 및 SamplerCustomAdvanced (#4829)으로 형성됩니다. 샘플러는 LTXVConcatAVLatent (#4528)에 의해 구성된 오디오+비디오 잠재 변수에서 작동하여 모든 단계에서 오디오 컨디셔닝이 참여하도록 합니다. 샘플링 후, LTXVSeparateAVLatent (#4845)는 잠재 변수를 분리하여 LTXVSetAudioRefTokens (#5013)가 고해상도 단계에서 동일한 말 표현을 얼릴 수 있도록 합니다. 이 단계는 입 모양을 말에 고정하고 s1 크기에서 동작 기준선을 설정합니다.
고해상도 생성#
LTXVLatentUpsampler (#4975)는 Spatial Upscaler x2를 사용하여 비디오 잠재 변수를 끌어올려 공간 세부 사항을 추가할 수 있는 용량을 추가하면서 동작을 보존합니다. LTXAddVideoICLoRAGuide (#5014)는 s2 크기를 사용하여 고해상도 프레임에 IC-LoRA를 다시 적용하여 동일한 화자 정체성과 정확한 입 모양을 강화합니다. 두 번째 확산 루프 (CFGGuider (#4964), KSamplerSelect (#4976), ManualSigmas (#4985), SamplerCustomAdvanced (#4971))는 업스케일된 잠재 변수를 정제하면서 LTXVConcatAVLatent (#4969)는 고정된 말 잠재 변수를 동기화 상태로 유지합니다. LTXVCropGuides (#5011, #5015)는 안전한 크롭과 영역 지침을 관리하여 얼굴이 두 단계 모두에서 올바르게 프레임에 남아 있도록 합니다.
디코딩#
LTXVTiledVAEDecode (#4995)는 타일을 사용하여 최종 비디오 잠재 변수를 VRAM 효율성을 위해 이미지로 변환하고, LTXVAudioVAEDecode (#4848)는 동기화된 오디오를 반환합니다. CreateVideo (#4849)는 원래의 프레임 속도로 프레임과 오디오를 조립하고, SaveVideo (#4852)는 RunComfy 이름이 미리 채워진 파일을 작성합니다; 이 값을 변경하여 출력을 브랜드화하세요. 결과는 검토 또는 전달 준비가 된 완전한 동기화된 LTX-2.3 ICLoRA LipDub 클립입니다.
Comfyui LTX-2.3 ICLoRA LipDub 워크플로우의 주요 노드#
LTXICLoRALoaderModelOnly (#5012)#
LipDub IC-LoRA를 로드하고 기본 모델에 연결하여 입 모양이 입력된 말을 따르도록 하면서 정체성을 덮어쓰지 않습니다. 더 강력하거나 미세한 입 제어가 필요하면 여기서 LoRA 가중치를 조정하세요; 스택에 적용하는 추가 LoRA와 조정하여 과도한 조건화를 피하세요.
LTXAddVideoICLoRAGuide (#5004)#
저해상도 단계에서 다운스케일된 참조 프레임을 사용하여 IC-LoRA 지침을 적용합니다. 워크플로우가 처음으로 정체성과 입 주변 주의를 고정하는 곳입니다; 참조 지침이 타이밍과 발음에 미치는 영향을 보려면 가이드를 전환하여 A/B 테스트에 사용하세요.
LTXAddVideoICLoRAGuide (#5014)#
고해상도에서 s2 프레임을 사용하여 IC-LoRA 지침을 다시 적용하여 정제된 단계가 동일한 화자 정체성과 정확한 입 모양을 보존하도록 합니다. 고해상도 프레임 크기를 변경하면 참조 가이드를 목표 출력에 맞게 유지하기 위해 이 노드를 다시 방문하세요.
LTXVSetAudioRefTokens (#5006)#
인코딩된 말을 텍스트 컨디셔닝에 바인딩하여 샘플러가 비세임을 음소와 정렬하도록 합니다. 안정적인 결과를 위해 두 단계 모두에서 동일한 오디오 잠재 변수를 사용하세요; 이 그래프는 자동으로 처리하지만, 실행 중간에 오디오를 교체하면 컨디셔닝과 결합된 잠재 변수를 새로 고쳐야 합니다.
LTXVLatentUpsampler (#4975)#
LTX-2.3 Spatial Upscaler x2를 사용하여 비디오 잠재 변수를 업스케일하여 고해상도 샘플러 전에 세부 사항을 위한 공간을 만듭니다. VRAM이 부족하면, 작은 s2 크기와 디코더에서 더 가벼운 타일링을 사용하여 품질과 처리량을 균형있게 조정하세요.
LTXVTiledVAEDecode (#4995)#
타일링을 사용하여 최종 잠재 변수를 프레임으로 디코딩하여 제한된 GPU에서 큰 출력을 맞춥니다. 타일 수와 중복을 여기서 조정하여 속도와 메모리 사용량을 교환하세요; 타일이 적을수록 빠르지만 더 많은 VRAM이 필요하고, 타일이 많을수록 VRAM이 줄어들지만 시간이 더 걸립니다.
선택적 추가 기능#
- 더빙을 위한 프롬프트 작성: 말하게 하고 싶은 정확한 단어를 포함하세요; 모델이 자동으로 번역하지 않습니다. 목표 언어의 고유 스크립트를 사용하고, 단일 화자에 집중하며, 원본 대사와 비슷한 길이를 목표로 하여 자연스러운 페이싱을 유지하세요.
- 성능 팁: VRAM 한계에 도달하면
Resize Image/Mask (s2 size)(#5003)에서 s2 리사이즈를 줄이고LTXVTiledVAEDecode(#4995)에서 타일링을 늘리세요. 반복성을 위해 두 단계 모두에서RandomNoise시드를 고정하세요. - 워크플로우 기본값: 예제 입력 파일 이름이
LoadVideo(#5002)에 미리 입력되어 있으며, 저장기는 일관된 출력 이름을 설정합니다. 두 개를 모두 교체하여 여러 LTX-2.3 ICLoRA LipDub 실행을 배치하여 결과를 덮어쓰지 않도록 하세요. - 프레이밍: 얼굴이 가장자리 근처로 이동하면
LTXVCropGuides(#5011, #5015)를 조정하여 입 주변이 두 단계 모두에서 안정적인 크롭에 남아 있도록 합니다.
감사의 말씀#
이 워크플로우는 다음의 작업 및 리소스를 구현하고 확장합니다. Lightricks의 LTX-2.3-22b-IC-LoRA-LipDub 모델과 RunComfy의 공유 ComfyUI 워크플로우 (Cloud Save 소스)에 대한 기여와 유지보수에 대해 감사드립니다. 권위 있는 세부 사항은 아래 링크된 원본 문서 및 저장소를 참조하세요.
리소스#
- Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- arXiv: arXiv:2601.22143
- RunComfy/Cloud Save source
- Docs / Release Notes: RunComfy shared workflow
참고: 참조된 모델, 데이터셋 및 코드의 사용은 해당 저자 및 유지보수자가 제공한 라이선스 및 조건에 따릅니다.