
LTX 2.3 듀얼 캐릭터 립 싱크 LoRA: 하나의 이미지와 하나의 오디오 트랙에서 두 캐릭터 립 싱크 비디오 생성#
이 ComfyUI 워크플로우는 단일 정지 이미지와 녹음된 두 스피커 대화를 조화로운, 정체성이 안정적인 비디오로 변환하여 화면에 나타난 두 캐릭터의 음성을 동기화합니다. LTX‑2.3 비디오 백본과 LTX 2.3 듀얼 캐릭터 립 싱크 LoRA를 중심으로 구축되어, 대화의 음소와 타이밍을 각 얼굴에 매핑하면서 표정, 시선 및 장면 일관성을 프레임 간에 유지합니다.
인터뷰, 영화적 대화, 비디오 호스트가 있는 팟캐스트 및 가상 캐릭터 상호 작용을 위해 설계된 이 워크플로우는 장면 배치를 위한 텍스트 프롬프트와 오디오 기반 모션을 결합합니다. 빠른 외관 개발을 위한 이미지 부트스트랩 단계, 시간적 안정성을 위한 2단계 LTX 샘플링, 그리고 선명한 결과를 위한 잠재적 업스케일러를 포함합니다. 최종 출력은 오디오가 내장된 MP4입니다.
Comfyui LTX 2.3 듀얼 캐릭터 립 싱크 LoRA 워크플로우의 주요 모델#
- LTX‑2.3 비디오 생성 모델. 텍스트, 이미지 및 오디오에 조건화된 시간적으로 일관된 비디오를 합성하는 다중 모달 디퓨전 백본을 제공합니다. Lightricks/LTX-2.3
- LTX‑2.3 비디오 VAE 및 오디오 VAE. 모델이 효율적이고 동기화된 생성을 유지하기 위해 비디오 및 오디오 잠재를 인코딩하고 디코딩합니다. LTX‑2.3 릴리스와 함께 제공됩니다. Lightricks/LTX-2.3
- LTX 공간 잠재적 업스케일러. 기본 패스 후에 세부 사항을 세밀화하여 더 깨끗한 질감과 가장자리를 위해 잠재 공간에서 업샘플링합니다. LTX 자산과 함께 사용할 수 있는 변형이 있습니다. Lightricks/LTX-2
- LTX 2.3 듀얼 캐릭터 립 싱크 LoRA. 동일한 샷에서 두 얼굴의 입 움직임과 타이밍을 촉진하는 교육을 주입하면서 얼굴 정체성을 유지합니다.
- Z‑Image Turbo 텍스트‑투‑이미지 모델. 비디오 합성 전에 정체성, 구도, 조명을 고정하는 고품질 참조 정지를 신속하게 생성합니다. Comfy‑Org/z_image_turbo
이 워크플로우에 사용된 관련 노드 팩: ComfyUI‑KJNodes, ComfyUI‑VideoHelperSuite, rgthree‑comfy, 및 ComfyUI‑PromptRelay.
Comfyui LTX 2.3 듀얼 캐릭터 립 싱크 LoRA 워크플로우 사용법#
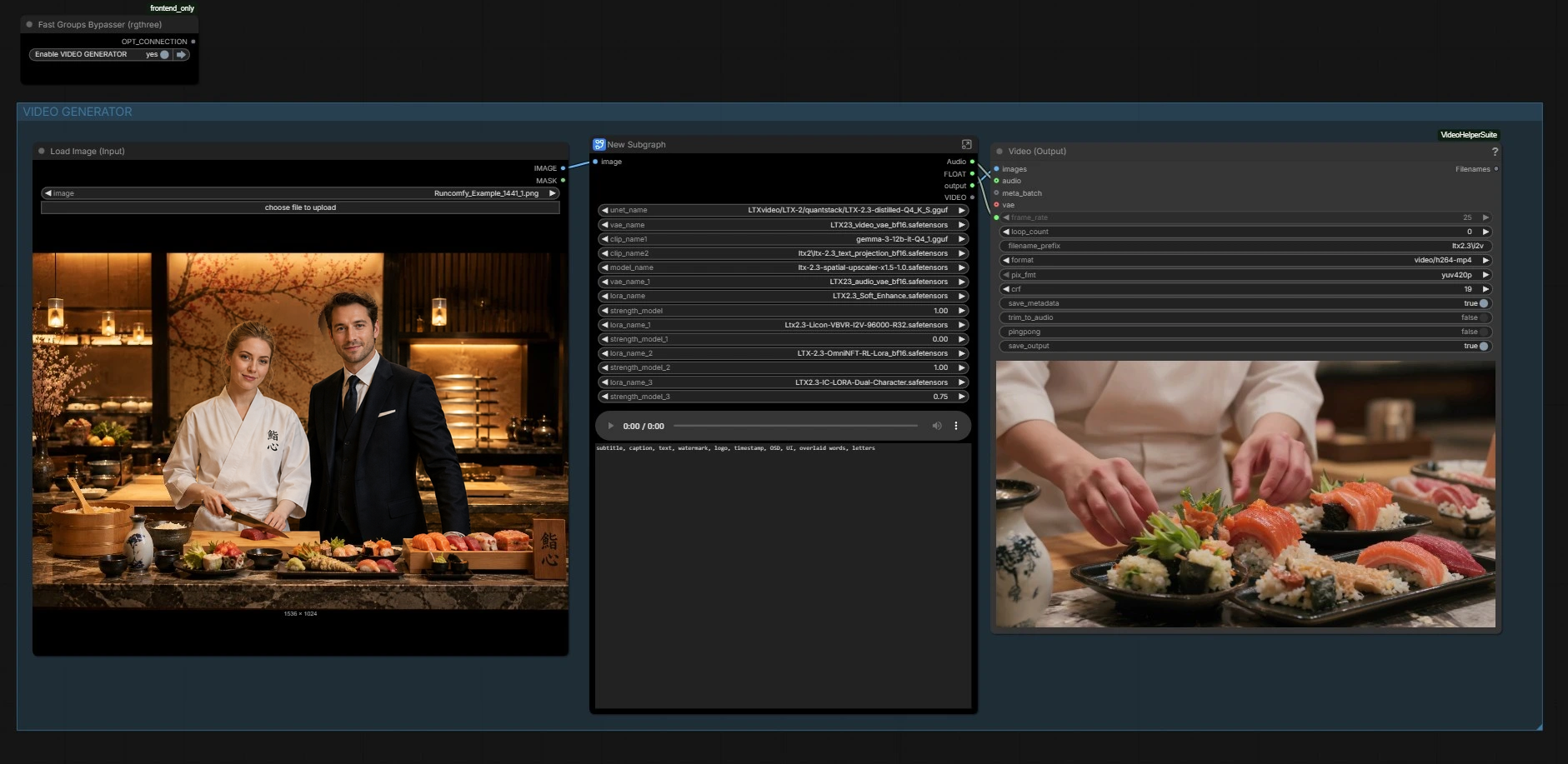
워크플로우는 이미지 생성기와 비디오 생성기의 두 조정된 부분으로 구성됩니다. 이미지 생성기는 히어로 프레임을 만들고, 비디오 생성기는 오디오에서 모션과 립 싱크를 구동하면서 외관을 유지합니다. 아래 그룹을 가이드로 사용하세요.
IMAGE GENERATOR#
이 섹션은 앵커 스틸을 구축합니다. 프롬프트 목록의 장면 프리셋을 사용하여 구성을 빠르게 초안한 다음, 두 사람의 캐릭터 설명으로 텍스트를 정제하세요. 컴팩트한 이미지 디퓨전 스택(“Z IMG TURBO” 서브그래프)은 프롬프트를 인코딩하고 깨끗한 참조 정지를 샘플링합니다. 이미지는 디코딩되어 검사용으로 저장된 후 비디오를 위한 정체성과 레이아웃을 시드하기 위해 전달됩니다.
여기서 다루는 주요 입력: 장면, 의상 및 두 개의 구별된 캐릭터에 대한 설명 프롬프트; 현실성을 방해하는 렌즈나 렌더링 용어는 의도적으로 그 외관을 원하지 않는 한 피하세요.
Models#
여기서 그래프는 LTX‑2.3 백본, 그 비디오 및 오디오 VAE, 텍스트 인코더 및 잠재적 업스케일러를 로드합니다. 또한 LTX 2.3 듀얼 캐릭터 립 싱크 LoRA를 적용하며, 옵션으로 스타일 또는 향상 LoRA도 활성화할 수 있습니다. 이곳에서 기본 모델의 기능과 LoRA의 두 스피커 립 싱크 동작이 결합되어 입 움직임을 지시하면서도 정체성이 손상되지 않도록 합니다. 가중치를 교환하거나 LoRA 영향을 조정하고자 하는 경우를 제외하고는 조치가 필요하지 않습니다.
CUSTOM AUDIO#
여기에서 대화 트랙을 제공하세요. 오디오 파일이 로드되고 오디오 잠재로 인코딩되어 파이프라인을 통해 타이밍과 음소 큐를 전달합니다. 오디오를 제공하지 않으면 워크플로우는 빈 오디오 잠재를 사용하여 모션을 생성할 수 있지만, LTX 2.3 듀얼 캐릭터 립 싱크 LoRA는 실제 대화에서 빛을 발하도록 설계되었습니다. 깨끗한 두 스피커 믹스와 명확한 턴테이킹을 사용하여 입 움직임의 분리를 최적화하세요.
Video PARAMETERS#
목표 지속 시간과 프레임 속도를 설정하세요. 이 값은 샘플링, 스케줄링, 크롭 가이드 및 최종 렌더링 전반에 걸쳐 저장되고 재사용되어 입술, 눈 깜빡임 및 샷 타이밍이 정렬된 상태를 유지합니다. 제공된 오디오와 비디오 길이를 일치시켜 리드인이나 테일을 피하세요.
LATENT GENERATION#
선택한 스틸이 전처리되고 그 차원이 감지됩니다. 워크플로우는 올바른 길이의 비디오 잠재를 생성한 후, 첫 프레임이 디자인과 일치하도록 스틸을 제자리에 삽입합니다. 배경이 얼굴에 비해 얼마나 진화할 수 있는지를 제어하기 위해 전체 프레임 노이즈 마스크가 적용됩니다. 준비된 오디오 잠재가 비디오 잠재와 쌍을 이루어 두 가지 모달리티 모두 조건화에 준비됩니다.
주목할 만한 노드: LTXVPreprocess는 LTX를 위한 스틸을 스케일링하고, EmptyLTXVLatentVideo는 타임라인을 구축하며, LTXVImgToVideoInplaceKJ (#5881)은 스틸에서 첫 프레임을 시딩하여 정체성을 고정합니다.
Conditioning#
텍스트 프롬프트가 인코딩되어 긍정적 및 부정적 조건으로 첨부됩니다. 자연어로 무대와 의도를 설명하기 위해 글로벌 프롬프트 박스를 사용하세요; 도움이 된다면 짧은 샷 목록을 포함할 수 있습니다. 전용 부정적 텍스트 인코더는 자막, 워터마크 및 UI를 억제하여 얼굴이 깨끗하게 유지되도록 합니다. 크롭 가이드 도우미는 잠재를 분석하여 두 얼굴에 주의가 집중되도록 하여 LTX 2.3 듀얼 캐릭터 립 싱크 LoRA가 활성화된 상태에서 스피커별 표현 추적을 개선합니다.
대표적인 구성 요소: PromptRelayEncode (#5903)는 장면 설명과 잠재적 컨텍스트를 병합하여 두 모달리티에 대한 프레임 속도 인식 지침을 첨부합니다.
1st Sampling#
첫 번째 디노이징 패스는 입 움직임이 차단된 시간적으로 일관된 기본 비디오를 생성합니다. 경량 스케줄러와 샘플러 쌍이 자동으로 선택되며, 매개변수는 저장된 타이밍 값에서 라우팅됩니다. LTX2_NAG에서 나오는 모델 변형은 비디오 및 오디오 조건에 대한 노이즈 인식 지침을 추가하여 콘텐츠가 형성될 때 음성 타이밍이 고정되도록 합니다.
핵심 샘플러 경로: SamplerCustom (#5891)과 KSamplerSelect 및 기본 스케줄러; 특정 샘플러 환경 설정이 있는 경우에만 조정하세요.
Stage #2 Upscale and refinement#
두 번째 단계는 선명도와 미세한 표현을 향상합니다. 잠재적 업스케일러는 공간적 세부 사항을 증가시키고, 오디오 및 비디오 잠재는 다시 결합되며, 정제 샘플러는 수립된 모션을 유지하면서 미세한 수정을 합니다. 이후 잠재는 분리되고 이미지 시퀀스와 오디오 파형으로 디코딩됩니다.
중요한 블록: LTXVLatentUpsampler (#5927)는 선명도를 위한 잠재적 업스케일러를 적용하고, SamplerCustomAdvanced (#5929)는 정제 패스를 위해 사용되며, VAEDecode와 LTXVAudioVAEDecode는 픽셀 및 오디오 공간으로 복귀합니다.
Output#
마지막으로 프레임과 오디오가 MP4로 포장되어 재생 및 검토를 위해 제공됩니다. 생성 중 모델이 본 시각적 리듬과 음소 타이밍이 일치하도록 조건화에 사용된 프레임 속도가 여기서 재사용됩니다. 중간 그래프에서 오디오를 미리 볼 수도 있습니다.
출력 경로: CreateVideo (#5931)이 클립을 생성하며, 메타데이터 제어가 포함된 대체 내보내기를 위한 보조 VHS_VideoCombine (#5905) 경로가 제공됩니다.
Comfyui LTX 2.3 듀얼 캐릭터 립 싱크 LoRA 워크플로우의 주요 노드#
LTXICLoRALoaderModelOnly(#5958) LTX 2.3 듀얼 캐릭터 립 싱크 LoRA를 LTX‑2.3 백본에 로드합니다. 입의 아티큘레이션과 스피커 분리를 더 강화해야 할 때strength_model을 증가시키고, 추가 스타일 LoRA를 쌓을 때는 기본 모델의 움직임과 스타일이 지배하도록 낮추세요.PromptRelayEncode(#5903) 장면 설명과 선택적으로 짧은 샷 계획을 작성할 중앙 장소입니다. 글로벌 프롬프트와 모델 컨텍스트, 현재 잠재를 융합하여 타임라인 전반에 걸쳐 지침이 일관되게 유지되도록 합니다. 언어를 명확하게 유지하고 두 캐릭터를 명확히 설명하여 정체성과 역할 분리를 돕습니다.LTXVImgToVideoInplaceKJ(#5881) 생성되거나 로드된 스틸에서 직접 비디오 잠재의 첫 프레임을 시드합니다. 이는 시간이 지남에 따라 드리프트를 줄이며 정체성, 의상 및 조명을 고정합니다. 최상의 결과를 위해 두 얼굴이 방해받지 않는 중간 또는 중간 와이드 투 샷을 사용하세요.LTXVAudioVAEEncode(#5851) 제공된 대화 트랙을 모델이 음소 타이밍에 사용할 수 있는 오디오 잠재로 변환합니다. 과도한 압축 없이 깨끗한 믹스를 공급하고, 시작 시간이 화면에 처음 나타나는 음성과 일치하도록 하여 입 움직임 오프셋을 피하세요.SamplerCustom(#5891) 및SamplerCustomAdvanced(#5929) 두 가지 보완적인 디노이징 단계. 모션 연속성을 유지하기 위해 단계 간 샘플러 패밀리를 일관되게 유지하고, 원하는 외관을 얻었을 때 노이즈 스케줄링의 급격한 변화를 피하세요.LTXVLatentUpsampler(#5927) 잠재적 업스케일러를 정제 전에 적용하여 설정된 모션을 불안정하게 만들지 않고 선명도를 추가합니다. 목표 해상도와 질감 현실성에 적합한 업스케일러 변형을 선택하세요.
선택적 추가 기능#
- 배경 소음을 최소화한 24 kHz의 두 스피커 WAV를 사용하세요; LTX 2.3 듀얼 캐릭터 립 싱크 LoRA가 턴을 분리하는 데 도움이 되도록 자연스러운 짧은 휴식을 대사 사이에 추가하세요.
- 두 주제가 보이고, 일반적으로 카메라를 향하고 있으며, 얼굴에 걸쳐 일관된 조명이 있는 스틸을 생성하거나 제공하세요.
- 샘플링 중에 번인된 UI 요소를 피하기 위해 “자막, 캡션, 로고, 타임스탬프”를 제외하는 부정적 텍스트 프롬프트를 유지하세요.
- 타이밍을 검증하려면 짧은 클립으로 시작한 후, 동작이 마음에 들면 지속 시간을 연장하거나 해상도를 높이세요.
- 스타일 LoRA를 추가하는 경우, 장면이 선택한 미학을 유지하면서도 아티큘레이션이 정확하게 유지되도록 LTX 2.3 듀얼 캐릭터 립 싱크 LoRA와 균형을 맞추세요.
감사의 글#
이 워크플로우는 다음 작품과 리소스를 구현하고 기반으로 합니다. 우리는 “LTX 2.3 듀얼 캐릭터 립 싱크 LoRA 워크플로우 소스”의 창작자들에게 감사드립니다. 권위 있는 세부사항은 아래에 연결된 원본 문서 및 저장소를 참조하세요.
리소스#
- LTX 2.3 듀얼 캐릭터 립 싱크 LoRA 워크플로우 소스/LTX 2.3 듀얼 캐릭터 립 싱크 LoRA 워크플로우 소스
- 문서 / 릴리스 노트: YouTube video
참고: 참조된 모델, 데이터 세트 및 코드의 사용은 해당 저자 및 유지 관리자가 제공하는 라이센스 및 조건에 따릅니다.