
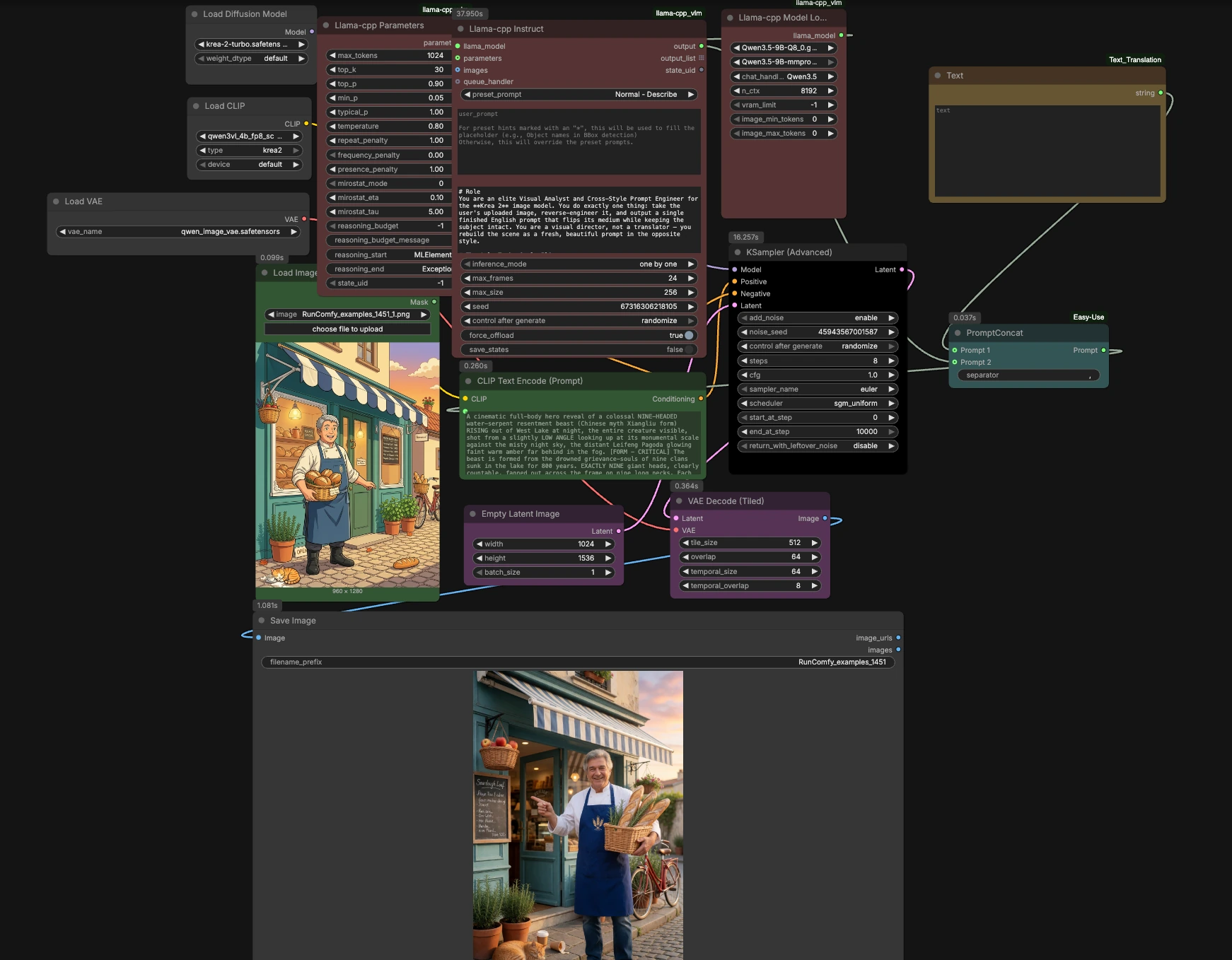






Krea 2 Turbo image-to-image ComfyUI 워크플로우#
이 워크플로우는 업로드된 이미지를 반대 시각 매체로 변환하면서 주제, 색상, 포즈, 프레임 및 장면 논리를 보존하는 스타일 전환 및 재생성 시스템입니다. 스타일화된 소스(애니메이션, 일러스트레이션, 3D, 그림)는 실감 나는 사진으로 재구성되며, 진정한 사진은 선명한 2D 애니메이션으로 재해석됩니다. Krea 2 Turbo를 중심으로 로컬 llama.cpp 비전 프롬프트 단계, Qwen3‑VL 텍스트 인코딩 및 Qwen Image VAE를 통합하여 시각적 세련미와 스타일 전환을 위한 빠르고 신뢰할 수 있으며 반복 가능한 결과를 제공합니다. 빠른 반복을 위한 재사용 가능하고 제작 준비된 Krea 2 Turbo image-to-image ComfyUI 워크플로우가 필요한 경우, 이것이 바로 그것입니다.
Comfyui Krea 2 Turbo image-to-image ComfyUI 워크플로우의 주요 모델#
- Krea 2 Turbo huggingface.co/krea/Krea-2-Turbo. 몇 단계의 빠른 추론에 최적화된 오픈 웨이트, 텍스트-이미지 확산 변환기입니다. Turbo는 속도와 일관된 프롬프트 준수를 위해 증류되었으며 높은 시각적 품질과 스타일 제어를 유지합니다.
- Qwen3‑VL 4B 텍스트 인코더 (Krea 2 에디션) huggingface.co/Comfy-Org/Krea-2. Krea 2에 조건을 부여하는 언어-비전 임베딩을 제공합니다; 이 릴리스에는 Krea 준비된 Qwen3‑VL 인코더 웨이트가 포함되어 있습니다.
- Qwen Image VAE huggingface.co/Comfy-Org/Krea-2. Krea 2가 잠재 공간과 픽셀 간을 높은 충실도로 이동하기 위해 사용하는 오토인코더입니다.
- Qwen 3.5 9B 비전-언어 모델 (GGUF) via llama.cpp github.com/mickeylan/ComfyUI-llama-cpp_vlm 및 github.com/ggml-org/llama.cpp. 업로드된 이미지를 분석하고 매체를 전환하면서 구체적인 시각적 사실을 고정하는 단일 세련된 프롬프트를 작성합니다.
Comfyui Krea 2 Turbo image-to-image ComfyUI 워크플로우 사용법#
워크플로우는 로컬 VLM으로 이미지를 분석하고 깨끗한 반대-매체 프롬프트를 생성하며, Krea 2를 위해 인코딩한 다음 Krea 2 Turbo로 재생성합니다. 파이프라인은 입력에서 출력까지 다섯 단계로 구성되며, 몇 가지 선택적 제어를 제공합니다.
1) 이미지 업로드 및 분석#
LoadImage (#128)에 이미지를 드롭하여 시작합니다. 사진은 llama_cpp_model_loader (#127) 및 llama_cpp_instruct_adv (#125)에 입력되어 로컬 Qwen 패밀리 비전-언어 모델이 llama.cpp를 통해 실행됩니다. 신중하게 제작된 system_prompt는 VLM이 주제 정체성, 정확한 색상, 구성 및 카메라 논리를 보존하면서 매체를 전환하도록 지시합니다: 스타일화된 소스는 사진으로, 진정한 사진은 생생한 2D 애니메이션으로 변환됩니다. 출력은 Krea 2를 위한 단일 자연 언어 프롬프트입니다.
2) 생성 프롬프트 조립#
Text (#130)를 사용하여 프로젝트 태그, 브랜드 용어 또는 렌즈 노트와 같은 짧은 지침을 추가하세요. easy promptConcat (#129)는 수동 텍스트를 VLM이 작성한 설명과 결합하여 하나의 일관된 프롬프트로 만듭니다. 추가는 최소화하세요; VLM은 이미 모든 보이는 요소를 정확하게 설명하므로 Krea 2 Turbo image-to-image ComfyUI 워크플로우가 신뢰성을 유지할 수 있습니다.
3) Krea 2를 위한 텍스트 인코딩#
CLIPLoader (#106)는 Krea 2를 위해 번들된 Qwen3‑VL 4B 텍스트 인코더를 로드하고, CLIPTextEncode (#5)는 최종 프롬프트를 조건으로 변환합니다. 이 인코더는 Krea 2의 토크나이저와 짝을 이루도록 설계되었으며, 상세한 장면 의미, 색상 진술 및 카메라 단서를 보존합니다. ConditioningZeroOut (#124)는 의도적으로 빈 부정 브랜치를 제공하여, 일반적으로 Krea 2 Turbo의 증류된 가이드 행동에 적합합니다.
4) Krea 2 Turbo로 생성#
UNETLoader (#107)는 Krea 2 Turbo 체크포인트를 로드하고 KSamplerAdvanced (#12)에 전달합니다. EmptyLatentImage (#10)는 캔버스 크기를 설정합니다; 원하는 너비와 높이를 선택하세요. Krea 2 Turbo는 매우 낮거나 제로 분류자-프리 가이던스로 몇 단계 샘플링을 위해 제작되었으므로 제로 CFG에 가깝게 시작하고, 더 엄격한 프롬프트 준수가 필요한 경우에만 이를 높이세요. 샘플러와 스케줄러는 프롬프트의 고정된 색상과 구성을 존중하는 빠르고 선명한 결과를 제공합니다.
5) 출력 디코딩 및 저장#
VAELoader (#105)는 VAEDecodeTiled (#123)를 사용하여 큰 이미지에 대한 VRAM 친화적인 타일링으로 잠재 공간에서 픽셀을 재구성하는 데 사용되는 Qwen Image VAE를 제공합니다. SaveImage (#35)는 최종 렌더링을 기록합니다. 결과는 반대 매체에서 깨끗하고 신뢰할 수 있는 재생성으로, 검토 또는 또 다른 빠른 패스를 위해 준비됩니다.
Comfyui Krea 2 Turbo image-to-image ComfyUI 워크플로우의 주요 노드#
llama_cpp_instruct_adv (#125)#
이 노드는 스타일 전환의 브레인입니다. system_prompt를 조정하여 전환 정책이나 보존 규칙을 변경하려는 경우에만 조정하세요; 기본값은 정체성, 포즈, 프레이밍 및 정확한 색상을 유지하도록 조정되어 있습니다. 렌즈를 사진 출력으로 지정하거나 애니메이션에 부드러운 팔레트 노트를 추가하는 등 작은 조정을 위해 preset_prompt 및 custom_prompt를 사용하세요. 출력은 하나의 유창한 단락으로 유지하세요; Krea 2는 자연어에 가장 잘 반응합니다.
KSamplerAdvanced (#12)#
속도, 선명도 및 준수를 제어합니다. Krea 2 Turbo는 몇 단계 샘플링을 위해 낮거나 제로 cfg(모델 카드 및 코드의 공식 가이던스를 참조)를 위해 증류되었으므로 최소한의 가이던스로 시작하고, 더 엄격한 프롬프트 준수가 필요한 경우에만 조정하세요. sampler_name 및 scheduler를 전환하여 선명한 가장자리와 초매끄러운 그라디언트 사이의 다른 균형을 선호하는 경우 조정하세요. 일관된 변형을 원할 때 noise_seed를 고정하세요.
EmptyLatentImage (#10)#
출력 크기 및 배치를 설정합니다. 의도한 프레이밍과 일치하는 종횡비 및 해상도를 선택하는 데 사용하세요; VLM 프롬프트는 구성을 전달하므로 이후의 자르기 변경을 피하세요. 더 큰 프레임은 메모리 효율성을 유지하기 위해 타일 디코딩 단계에서 이점을 얻습니다.
ConditioningZeroOut (#124)#
설계상 부정 프롬프트를 비활성화합니다, 이는 일반적으로 Krea 2 Turbo에 적합합니다. 프로젝트에 전통적인 부정 프롬프트가 필요한 경우, KSamplerAdvanced (#12)의 부정 입력을 공급하는 두 번째 CLIPTextEncode로 이를 대체하세요.
VAEDecodeTiled (#123)#
더 높은 해상도에서 VRAM 사용을 안정적으로 유지하기 위해 타일 디코딩을 수행합니다. 극한 크기에서 이음새가 보이면 겹침을 부드럽게 증가시키세요; 메모리가 부족하면 타일링 세분성을 증가시키세요.
선택적 추가 기능#
- 스타일화 제어를 위해 Comfy-Org 리팩에서 Krea-2 LoRAs를 로드하고 ComfyUI에서 다른 LoRA처럼 적용할 수 있습니다 huggingface.co/Comfy-Org/Krea-2. Krea는 Raw에서 LoRAs를 훈련하고 Turbo에서 적용하는 것을 권장합니다; 자세한 내용은 공식 저장소를 참조하세요 github.com/krea-ai/krea-2.
- 수동 편집은 짧게 유지하세요. Krea 2 Turbo image-to-image ComfyUI 워크플로우는 정확한 색조와 장면 논리를 보존하도록 설계되었으며, 긴 수동 프롬프트는 VLM의 색상 잠금을 의도치 않게 무효화할 수 있습니다.
- 가장 빠른 반복을 위해 중간 해상도에서 작업하고, 구성을 검토한 후 플립에 만족한 후에 최종 결과를 위해 업스케일하거나 해상도를 높이세요.
감사의 글#
이 워크플로우는 다음 작업 및 리소스를 구현하고 기반으로 합니다. Image-to-Image 워크플로우 소스에 대한 RunningHub에 감사하며, Krea AI에 Krea 2 및 Krea-2-Turbo를, Comfy-Org 및 mickeylan에 ComfyUI Krea 2 웨이트 및 ComfyUI llama-cpp VLM 커스텀 노드에 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하세요.
리소스#
- RunningHub/Image-to-Image Workflow
- 문서 / 릴리스 노트: RunningHub post
- krea-ai/Krea 2
- GitHub: krea-ai/krea-2
- Krea/Krea-2-Turbo
- Hugging Face: krea/Krea-2-Turbo
- Comfy-Org/Krea-2
- Hugging Face: Comfy-Org/Krea-2
- mickeylan/ComfyUI-llama-cpp_vlm
- GitHub: mickeylan/ComfyUI-llama-cpp_vlm
참고: 언급된 모델, 데이터셋 및 코드는 해당 저자 및 유지 관리자가 제공하는 라이선스 및 조건에 따라 사용됩니다.
