
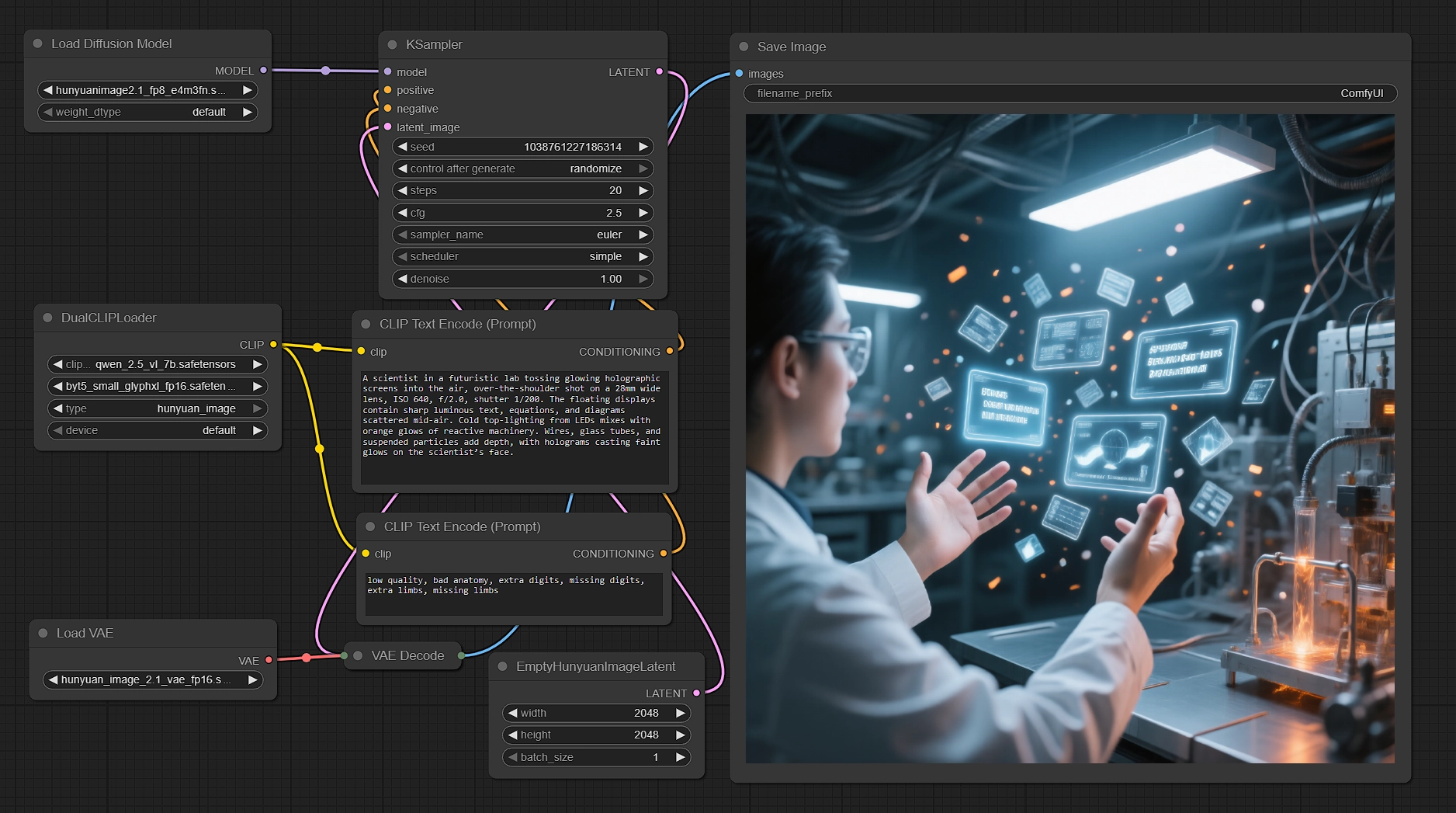










ComfyUI에서 Hunyuan Image 2.1로 네이티브 2K 이미지 생성#
이 워크플로우는 Hunyuan Image 2.1을 사용하여 프롬프트를 선명한 네이티브 2048×2048 렌더로 변환합니다. Tencent의 확산 변환기를 이중 텍스트 인코더와 결합하여 의미 정렬과 텍스트 렌더링 품질을 높인 후 효율적으로 샘플링하고 일치하는 고압축 VAE를 통해 디코딩합니다. 제작 준비가 된 장면, 캐릭터, 명확한 텍스트를 2K로 생성하면서 속도와 제어를 유지해야 하는 경우, 이 ComfyUI Hunyuan Image 2.1 워크플로우가 적합합니다.
창작자, 아트 디렉터, 기술 아티스트는 다국어 프롬프트를 사용하고 몇 가지 설정을 미세 조정하여 일관되게 선명한 결과를 얻을 수 있습니다. 이 그래프는 합리적인 네거티브 프롬프트, 네이티브 2K 캔버스 및 VRAM을 관리하기 위한 FP8 UNet을 포함하여 Hunyuan Image 2.1이 제공할 수 있는 것을 보여줍니다.
ComfyUI Hunyuan Image 2.1 워크플로우의 주요 모델들#
- Tencent의 HunyuanImage‑2.1. 확산 변환기 백본, 이중 텍스트 인코더, 32× VAE, RLHF 사후 훈련 및 효율적인 샘플링을 위한 meanflow 증류를 갖춘 기본 텍스트-이미지 모델입니다. 링크: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct. 복잡한 장면 및 언어 전반의 프롬프트 이해를 향상시키기 위해 여기에서 의미 텍스트 인코더로 사용되는 다중 모달 비전-언어 인코더입니다. 링크: Hugging Face
- ByT5 Small. 이미지 내 텍스트 렌더링을 위한 문자 및 글자 처리 강화를 위한 토크나이저 없는 바이트 수준 인코더입니다. 링크: Hugging Face · Paper
ComfyUI Hunyuan Image 2.1 워크플로우 사용 방법#
그래프는 프롬프트에서 픽셀까지의 명확한 경로를 따릅니다: 두 인코더로 텍스트를 인코딩하고, 네이티브 2K 잠재 캔버스를 준비하고, Hunyuan Image 2.1로 샘플링하고, 일치하는 VAE를 통해 디코딩한 후 출력을 저장합니다.
이중 인코더를 사용한 텍스트 인코딩#
DualCLIPLoader(#33)은 Hunyuan Image 2.1에 대해 구성된 Qwen2.5‑VL‑7B 및 ByT5 Small을 로드합니다. 이 이중 설정은 모델이 장면 의미를 구문 분석하면서 글자 및 다국어 텍스트에 강력하게 유지되도록 합니다.CLIPTextEncode(#6)에서 주요 설명을 입력합니다. 영어 또는 중국어로 작성할 수 있으며, 카메라 힌트 및 조명을 혼합하고 이미지 내 텍스트 지침을 포함할 수 있습니다.CLIPTextEncode(#7)에서 사용 가능한 네거티브 프롬프트는 일반적인 아티팩트를 억제합니다. 스타일에 맞추어 조정하거나 균형 잡힌 결과를 위해 그대로 둘 수 있습니다.
네이티브 2K의 잠재 캔버스#
EmptyHunyuanImageLatent(#29)은 단일 배치로 2048×2048에서 캔버스를 초기화합니다. Hunyuan Image 2.1은 2K 생성을 위해 설계되었으므로 최상의 품질을 위해 네이티브 2K 크기를 권장합니다.- 필요에 따라 너비와 높이를 조정하되, Hunyuan이 지원하는 종횡비를 유지하세요. 대체 비율의 경우, 아티팩트를 피하기 위해 모델 친화적인 크기를 고수하세요.
Hunyuan Image 2.1의 효율적인 샘플링#
UNETLoader(#37)은 FP8 체크포인트를 로드하여 VRAM을 줄이면서 충실도를 유지한 후KSampler(#3)에 피드하여 노이즈를 제거합니다.- 인코더에서 긍정 및 부정 조건을 사용하여 구성 및 선명도를 조절합니다. 다양성을 위해 시드를 조정하고, 품질 대 속도를 위해 단계를 조정하고, 프롬프트 준수를 위해 가이던스를 조정하세요.
- 워크플로우는 기본 모델 경로에 중점을 둡니다. Hunyuan Image 2.1은 정제 단계도 지원하므로 추가적인 세련미가 필요할 경우 나중에 추가할 수 있습니다.
디코딩 및 저장#
VAELoader(#34)는 Hunyuan Image 2.1 VAE를 가져오고,VAEDecode(#8)는 모델의 32× 압축 스킴을 사용하여 샘플링된 잠재로부터 최종 이미지를 재구성합니다.SaveImage(#9)는 선택한 디렉토리에 출력을 저장합니다. 시드나 프롬프트를 통해 반복할 계획이라면 명확한 파일 이름 접두어를 설정하세요.
ComfyUI Hunyuan Image 2.1 워크플로우의 주요 노드들#
DualCLIPLoader (#33)#
이 노드는 Hunyuan Image 2.1이 기대하는 텍스트 인코더 쌍을 로드합니다. 모델 유형을 Hunyuan에 맞춰 설정하고 Qwen2.5‑VL‑7B 및 ByT5 Small을 선택하여 강력한 장면 이해와 글자 인식 텍스트 처리를 결합하세요. 스타일을 반복하려면 인코더를 교체하기보다는 가이던스와 함께 긍정 프롬프트를 조정하세요.
CLIPTextEncode (#6 및 #7)#
이 노드는 긍정 및 부정 프롬프트를 조건화로 변환합니다. 긍정 프롬프트를 간결하게 위에 두고 렌즈, 조명 및 스타일 힌트를 추가하세요. 부정 프롬프트를 사용하여 추가 팔다리나 시끄러운 텍스트와 같은 아티팩트를 억제하세요; 개념에 비해 지나치게 제한적이라고 느껴질 경우 다듬으세요.
EmptyHunyuanImageLatent (#29)#
작업 해상도와 배치를 정의합니다. 기본 2048×2048은 Hunyuan Image 2.1의 네이티브 2K 기능과 일치합니다. 다른 종횡비의 경우 모델 친화적인 너비와 높이 쌍을 선택하고, 사각형에서 멀어질 경우 단계를 약간 늘리는 것을 고려하세요.
KSampler (#3)#
Hunyuan Image 2.1로 노이즈 제거 프로세스를 구동합니다. 미세 세부 사항이 필요할 때 단계를 늘리고, 빠른 초안을 위해 줄입니다. 프롬프트 준수를 위해 가이던스를 높이지만 과포화 또는 경직됨을 주의하세요; 보다 자연스러운 변화를 위해 낮추세요. 프롬프트를 변경하지 않고 구성을 탐색하려면 시드를 전환하세요.
UNETLoader (#37)#
Hunyuan Image 2.1 UNet을 로드합니다. 포함된 FP8 체크포인트는 2K 출력을 위한 메모리 사용을 적절히 유지합니다. 충분한 VRAM이 있고 공격적인 설정을 위한 최대 여유 공간을 원할 경우, 공식 릴리스에서 더 높은 정밀도의 변형을 고려하세요.
VAELoader (#34) 및 VAEDecode (#8)#
이 노드는 올바르게 디코딩하기 위해 Hunyuan Image 2.1 릴리스와 일치해야 합니다. 모델의 고압축 VAE는 빠른 2K 생성의 핵심이며, 올바른 VAE를 페어링하면 색상 이동 및 블록형 텍스처를 피할 수 있습니다. 기본 모델을 변경할 경우 항상 VAE를 업데이트하세요.
선택적 추가 기능#
- 프롬프트
- Hunyuan Image 2.1은 구조화된 프롬프트에 잘 반응합니다: 주제, 행동, 환경, 카메라, 조명, 스타일. 이미지 내 텍스트의 경우, 정확한 단어를 인용하고 간결하게 유지하세요.
- 속도와 메모리
- FP8 UNet은 이미 효율적입니다. 더 짜내야 할 경우, 큰 배치를 비활성화하고 적은 단계를 선호하세요. 선택적 GGUF 로더 노드는 그래프에 있지만 기본적으로 비활성화되어 있습니다; 고급 사용자는 양자화된 체크포인트를 실험할 때 교체할 수 있습니다.
- 종횡비
- 최상의 결과를 위해 네이티브 2K 친화적인 크기를 고수하세요. 넓거나 높은 형식으로 이동할 경우 깔끔한 렌더를 확인하고 작은 단계 증가를 고려하세요.
- 정제
- Hunyuan Image 2.1은 정제 단계를 지원합니다. 시도하려면 기본 패스 후 정제 체크포인트와 가벼운 노이즈 제거를 사용하여 구조를 보존하면서 미세 세부 사항을 향상시키는 두 번째 샘플러를 추가하세요.
- 참고 자료
- Hunyuan Image 2.1 모델 세부 사항 및 다운로드: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct: Hugging Face
- ByT5 Small 및 논문: Hugging Face · Paper
감사의 글#
이 워크플로우는 다음 작업 및 리소스를 구현하고 이에 기반하여 구축되었습니다. Hunyuan Image 2.1 Demo에 대한 기여 및 유지보수에 대해 @Ai Verse 및 Hunyuan에게 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원래 문서 및 저장소를 참조하십시오.
리소스#
- Hunyuan/Hunyuan Image 2.1 Demo
- 문서 / 릴리스 노트: Hunyuan Image 2.1 Demo tutorial from @Ai Verse
참고: 참조된 모델, 데이터셋 및 코드의 사용은 해당 작성자 및 유지 관리자가 제공하는 각각의 라이선스 및 조건에 따릅니다.

