
こんにちは!このガイドでは、ComfyUIにおけるControlNetの興味深い世界を一緒に探求します。ControlNetが何をもたらしてくれるのか、プロジェクトでどのように活用できるのか見ていきましょう!
以下の項目をカバーします:
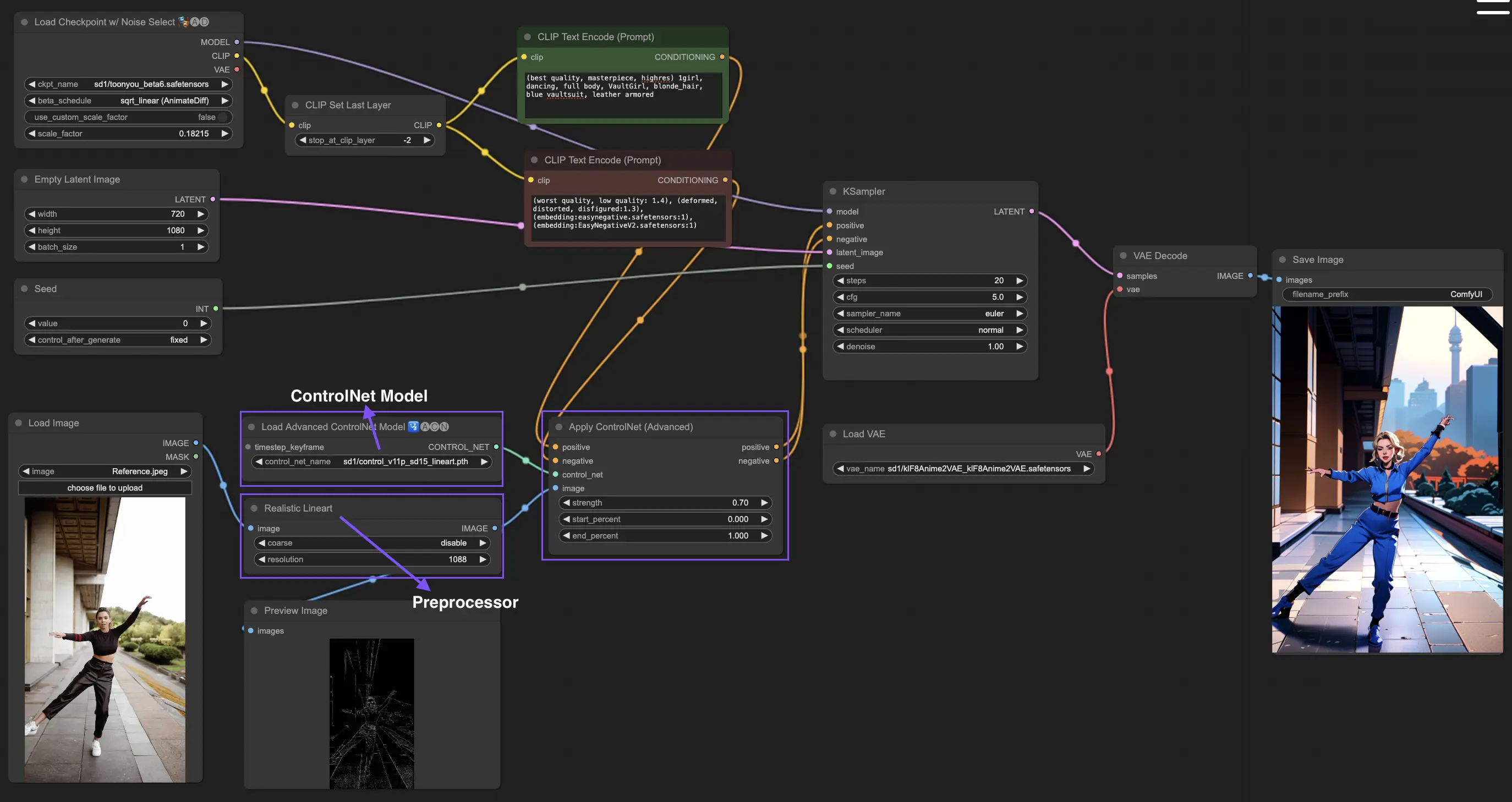
- 3.1. ComfyUIでの「Apply ControlNet」ノードの読み込み
- 3.2. 「Apply ControlNet」ノードの入力
- 3.3. 「Apply ControlNet」ノードの出力
- 3.4. 「Apply ControlNet」のファインチューニング用パラメーター
- 5.1. ControlNet Openpose
- 5.2. ControlNet Tile
- 5.3. ControlNet Canny
- 5.4. ControlNet Depth
- 5.5. ControlNet Lineart
- 5.6. ControlNet Scribbles
- 5.7. ControlNet Segmentation
- 5.8. ControlNet Shuffle
- 5.9. ControlNet Inpainting
- 5.10. ControlNet MLSD
- 5.11. ControlNet Normalmaps
- 5.12. ControlNet Soft Edge
- 5.13. ControlNet IP2P (Instruct Pix2Pix)
- 5.14. T2I Adapter
- 5.15. 他の人気のControlNet: QRCode MonsterとIP-Adapter
6. 複数のControlNetの使い方#
7. 今すぐComfyUI ControlNetを体験!#
🌟🌟🌟 ComfyUIオンライン - 今すぐControlNetのワークフローを体験🌟🌟🌟#
ControlNetワークフローを探索したい方は、次のComfyUI Webをご利用ください。必要なカスタマーノードとモデルが全てそろっており、手動設定不要でスムーズに創造活動ができます。ControlNetの機能をさっそく試してみて、すぐに実践的な体験を積んでください。あるいは、引き続きこのチュートリアルを読み進め、ControlNetを上手に使いこなす方法を学んでください。
さらに高度でプレミアムなComfyUIワークフローについては、🌟ComfyUIワークフローリスト🌟をご覧ください。#
1. ControlNetとは?#
ControlNetは、テキストから画像への拡散モデルの機能を大幅に拡張し、画像生成の空間的な制御を可能にする革命的な技術です。ニューラルネットワークアーキテクチャとして、Stable Diffusionなどの大規模な事前学習済みモデルとシームレスに統合されます。画像生成プロセスに空間的な条件を導入するために、これらのモデルが数十億枚の画像で訓練された臨場感を活用します。これらの条件は、エッジや人物のポーズから深度やセグメンテーションマップまで多岐に渡り、テキストプロンプトのみでは以剄dには不可能だった方法で、ユーザーが画像生成をガイドできるようになります。
2. ControlNetの技術的側面#
ControlNetの天才的な点は、その独特な方法論にあります。まず、元のモデルのパラメータを確保し、基礎となるトレーニングが変更されないようにします。次に、ControlNetは「ゼロ畳み込み」を利用してトレーニングするためのモデルのエンコーディング層のクローンを導入します。これらの特別設計された畳み込み層は、ゼロの重みで始まり、新しい空間的条件を注意深く組み込みます。このアプローチは、モデルの元々の熟達度を維持しながら、新しい学習軌跡を開始するための、邪魔なノイズの介在を防ぐことができます。
3. ComfyUIの基本的なControlNetの使用方法#
伝統的に、安定拡散モデルは画像の生成をガイドするための条件付けメカニズムとしてテキストプロンプトを使用し、出力をテキストプロンプトの指示に合わせて調整します。ControlNetはこのプロセスに追加の条件付け形式を導入します。これにより、テキストと画像の両方の入力に応じて、生成された画像をより正確に制御できるようになります。
3.1. ComfyUIでの「Apply ControlNet」ノードの読み込み#
このステップでは、ControlNetをComfyUIのワークフローに統合し、画像生成プロセスに追加の条件付けを適用できるようにします。テキストプロンプトと並行して画像ガイダンスを適用する基礎を築きます。
3.2. 「Apply ControlNet」ノードの入力#
ポジティブとネガティブの条件付け: これらの入力は、望ましい結果を定義し、生成される画像の望ましくない部分を避けるために重要です。それぞれ「Positive prompt」と「Negative prompt」にリンクする必要があり、テキスト条件付けの部分と一致させます。
ControlNetモデル: この入力は「Load ControlNet Model」ノードの出力に接続する必要があります。このステップは、ControlNetモデルまたはT2IAdapterモデルを選択し、ワークフローに組み込むために不可欠です。これにより、選択したモデルが提供する特定のガイダンスを拡散モデルが活用できるようになります。ControlNetモデルであれ、T2IAdapterモデルであれ、それぞれが特定のデータタイプやスタイルの嫌味に応じて画像生成プロセスに影響を与えるように訓練されています。T2IAdapterモデルの多くがControlNetモデルの機能と密接に関係しているため、今後の議論では主にControlNetモデルに焦点を当てますが、一部の人気のT2IAdapterについても取り上げます。
前処理: 「image」入力は「ControlNet Preprocessor」ノードに接続する必要があります。これは、使用しているControlNetモデルの特定の要件を満たすように画像を適応させるために重要です。選択したControlNetモデルに合わせて正しい前処理を使用することが不可欠です。このステップでは、フォーマット、サイズ、色の調整や特定のフィルターの適用など、必要な修正が元の画像に施されるようにします。これにより、ControlNetのガイドラインに最適化されます。この前処理の段階で、元の画像は修正されたバージョンに置き換えられ、ControlNetがそれを利用します。このプロセスにより、入力画像がControlNetプロセスに向けて正確に準備されることが保証されます。
3.3. 「Apply ControlNet」ノードの出力#
「Apply ControlNet」ノードは、ポジティブとネガティブの条件付けという2つの重要な出力を生成します。これらの出力は、ControlNetと画像ガイダンスの細かな効果を備えており、ComfyUIの拡散モデルの振る舞いを決定する上で重要な役割を果たします。その後、選択肢があります。生成された画像をさらに洗練するためにサンプリングフェーズにKSamplerに進むか、より高いレベルの詳細とカスタマイズを追求するクリエイターのために、さらに追加のControlNetを重ねることです。この高度なテクニックは、より細かな画像の属性操作を可能にし、ビジュアル出力で最高の精度と制御を目指すクリエイターのための強力なツールを提供します。
3.4. 「Apply ControlNet」のファインチューニング用パラメーター#
strength: このパラメーターは、ComfyUIで生成された画像に対するControlNetの効果の強度を決定します。1.0の値は、完全な強度を意味し、ControlNetのガイダンスが拡散モデルの出力に最大限の影響を与えることを意味します。逆に、0.0の値は影響がないことを示し、事実上、画像生成プロセスに対するControlNetの効果を無効にします。
start_percent: このパラメーターは、拡散プロセスのパーセンテージとして、ControlNetが生成に影響を与え始める開始点を指定します。例えば、20%の開始パーセントを設定すると、ControlNetのガイダンスは拡散プロセスの20%地点から画像生成に影響を与え始めることを意味します。
end_percent: 「Start Percent」と同様に、「End Percent」パラメーターは、ControlNetの影響が停止するポイントを定義します。例えば、80%の終了パーセントは、ControlNetのガイダンスが拡散プロセスの80%完了時点で画像生成への影響を停止し、最終段階には影響を与えないことを意味します。
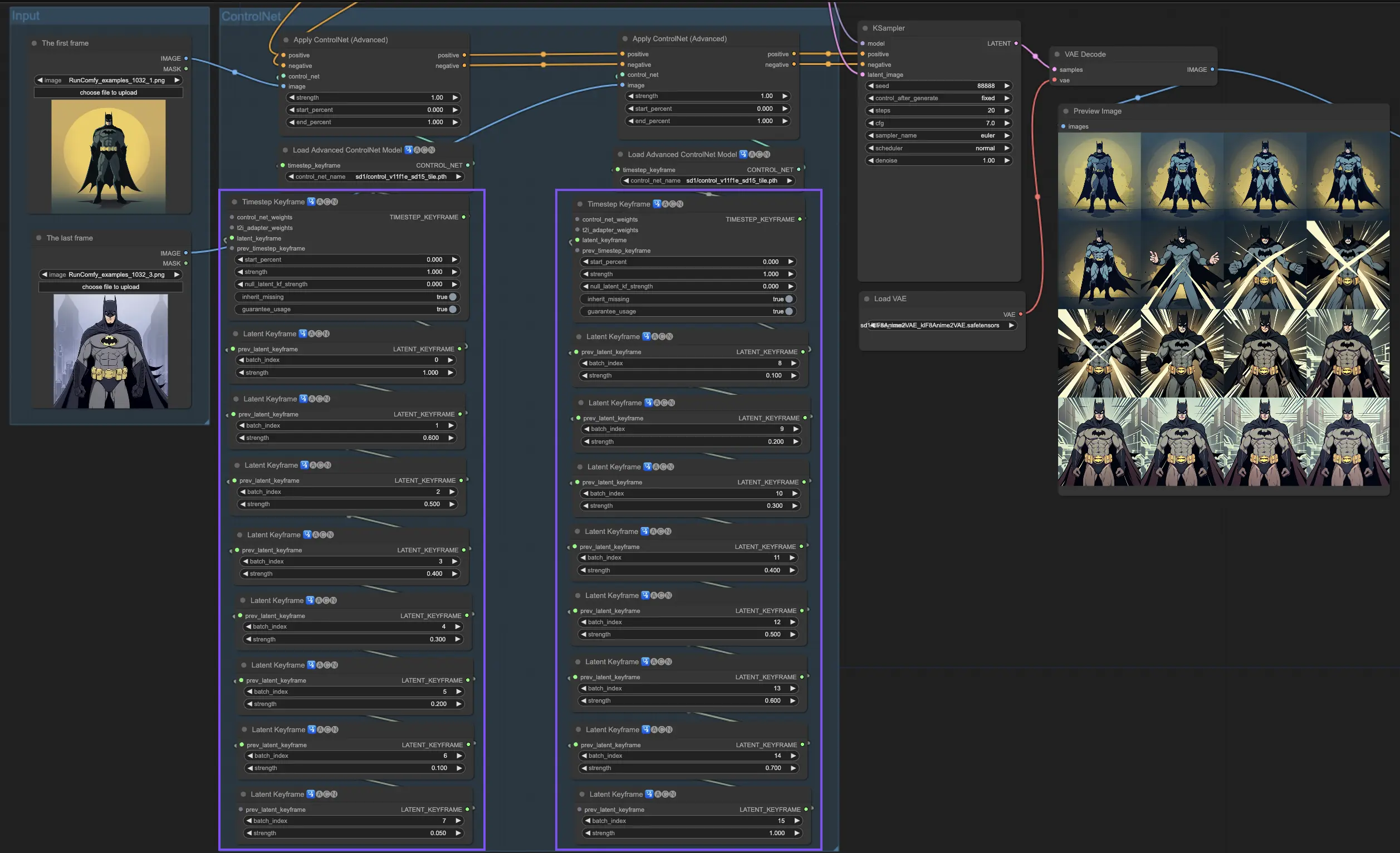
4. ComfyUIの高度なControlNetの使用方法 - Timestep Keyframes#
ControlNetでのTimestep Keyframesは、特にアニメーションや進する画像のようにタイミングと進行が重要なAI生成コンテンツの振る舞いを細かく制御するための洗練された方法を提供します。主要なパラメーターの詳細な内訳を以下に示し、それらを効果的かつ直感的に活用できるようにします:
prev_timestep_kf: prev_timestep_kfは、連続したキーフレーム内で直前のキーフレームと手をつなぐようなものだと考えてください。キーフレームを接続することで、段階的に進行するAIをガイドするスムーズな遷移やストーリーボードを作成し、各フェーズが論理的に次のフェーズへと流れるようにします。
cn_weights: cn_weightsは、生成プロセスの異なる段階でControlNet内の特定の機能を調整することで、出力を微調整するのに役立ちます。
latent_keyframe: latent_keyframeは、生成プロセスの特定の段階で、AIモデルの各部分が最終的な結果にどれだけ強く影響を与えるかを調整できます。例えば、プロセスが進展するにつれて前景がより詳細になるような画像を生成する場合、後半のキーフレームでは前景の詳細を担当するモデルの側面(latents)の強度を増やすことができます。逆に、特定の特徴が時間とともに背景にフェードアウトする必要がある場合は、その後のキーフレームでそれらの強度を下げることができます。このレベルの制御は、ダイナミックで進化するビジュアルを作成したり、正確なタイミングと進行が重要なプロジェクトで特に有用です。
mask_optional: 注意マスクをスポットライトのように使って、ControlNetの影響を画像の特定の領域に集中させます。シーンの中のキャラクターを強調する場合でも、背景要素を強調する場合でも、これらのマスクは一様に適用することも、強度を変えることもできます。AIの注意を望むところに正確に向けることができます。
start_percent: start_percentは、全体の生成プロセスの中でのパーセンテージとして測ったときに、キーフレームがいつ登場するかを示します。これを設定することは、予定通りのタイミングで俳優を舞台に登場させるようなものです。
strength: strengthは、ControlNetの全体的な影響力の高レベルな制御を提供します。
null_latent_kf_strength: このシーン(キーフレーム)で明示的に指示していない俳優(latents)については、null_latent_kf_strengthがデフォルトの指示として機能し、背景での演技方法を伝えます。これにより、特に言及していない領域でも、生成のどの部分もガイダンスなしで放置されることはなく、一責した出力を維持できます。
inherit_missing: inherit_missingを有効にすると、現在のキーフレームは、前のキーフレームから指定されていない設定を引き継ぐことができます。ちょうど弟が服を受け継ぐように。これは便利なショートカットで、指示を繰り返すことなく継続性と一責性を確保できます。
guarantee_usage: guarantee_usageは、他の条件に関わらず、現在のキーフレームがプロセスの中で必ずその役目を果たすことを保証します。たとえそれが短い瞬間でも。これにより、設定した全てのキーフレームがAIの創造プロセスに影響を与えることが確定し、詳細な計画を尊重します。
Timestep Keyframesは、AIの創造プロセスを細心にガイドするために必要な精度を提供し、ビジョンに応じて、ビジュアルや可視化の旅を正確に組み立てることができます。特にアニメーションでは、冒頭のシーンから終わりまで、ビジュアルの進展を管理するための強力なツールとしても活躍します。芸術的な目標に完璧に合致しています。
5. さまざまなControlNet/T2IAdapterモデル: 詳細な概要#
T2IAdapterモデルの多くがControlNetモデルの機能と密接に関係しているため、今後の議論では主にControlNetモデルに焦点を当てますが、一部の人気のT2IAdapterについても取り上げます。
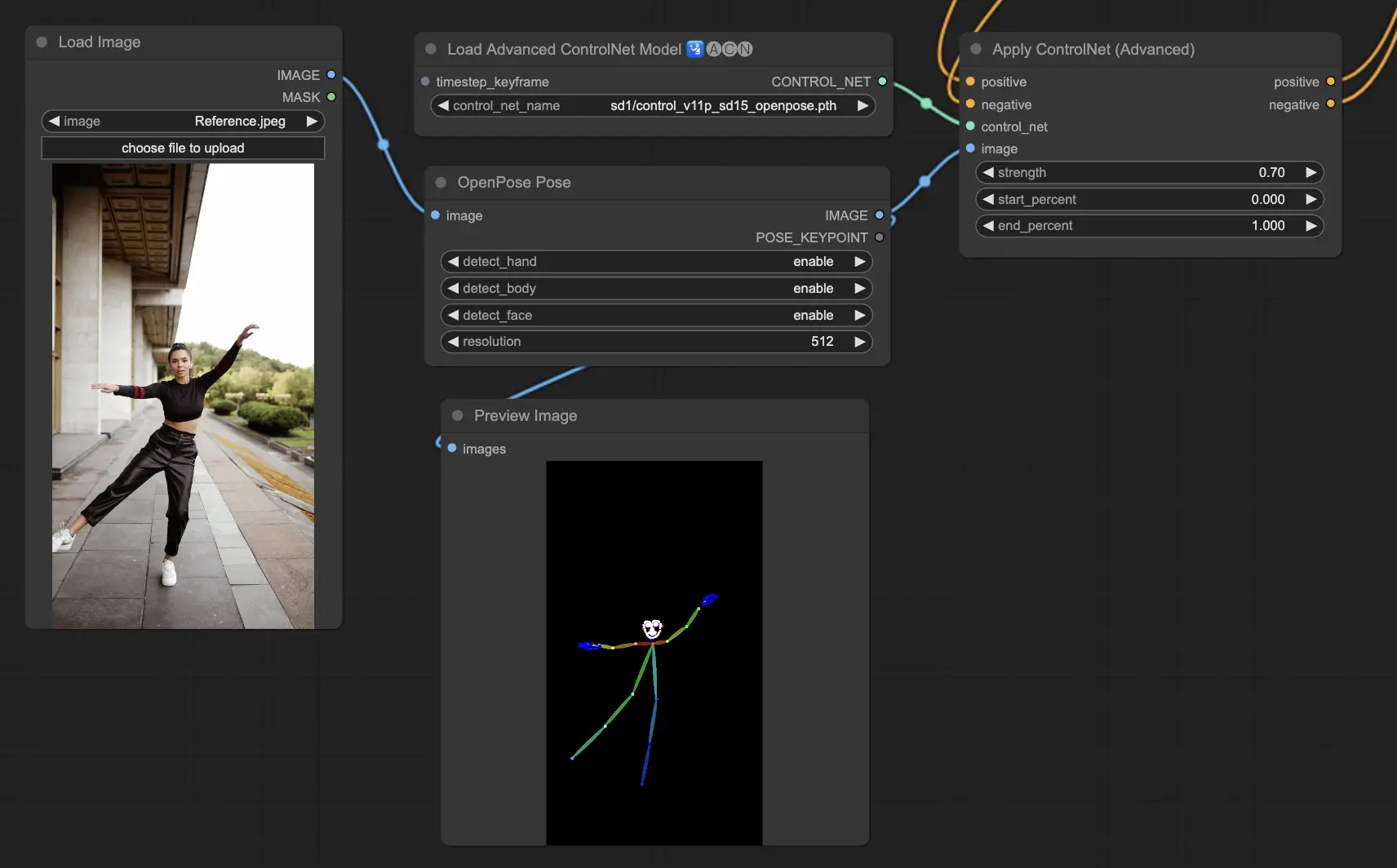
5.1. ComfyUI ControlNet Openpose#
- Openpose (=Openpose body): 目、鼻、首、肩、肩、ひじ、手首、ひざ、足首などの基本的な体のキーポイントを識別する、ControlNetでの基礎となるモデルです。基本的な人間のポーズの再現に理想的です。
- Openpose_face: 顔のキーポイント検出を追加することで、OpenPoseモデルを拡張し、表情と向きのより詳細な分析を提供します。このControlNetモデルは、表情に焦点を当てたプロジェクトに不可欠です。
- Openpose_hand: OpenPoseモデルを拡張して、手と指の詳細をキャプチャできるようになり、詳細な手のジェスチャーと位置に焦点を当てます。この追加によって、ControlNet内でのOpenPoseの汎用性が向上します。
- Openpose_faceonly: 体のキーポイントを省略し、表情と顔の向きのキャプチャに焦点を当てた、顔の詳細に特化したモデルです。このモデルは、ControlNetの枠内で顔の特徴にのみ焦点を当てています。
- Openpose_full: OpenPose、OpenPose_face、OpenPose_handモデルを総合的に組み合わせたモデルで、全身、顔、手の完全な検出機能を提供し、ControlNet内での完全な人間のポーズ再現を可能にします。
- DW_Openpose_full: OpenPose_fullモデルの強化版であり、さらなる改良を取り入れて、より詳細で正確なポーズ検出を実現します。このバージョンは、ControlNetフレームワークにおけるポーズ検出精度の最高峰を表しています。
Preprocessor: OpenposeまたはDWpose
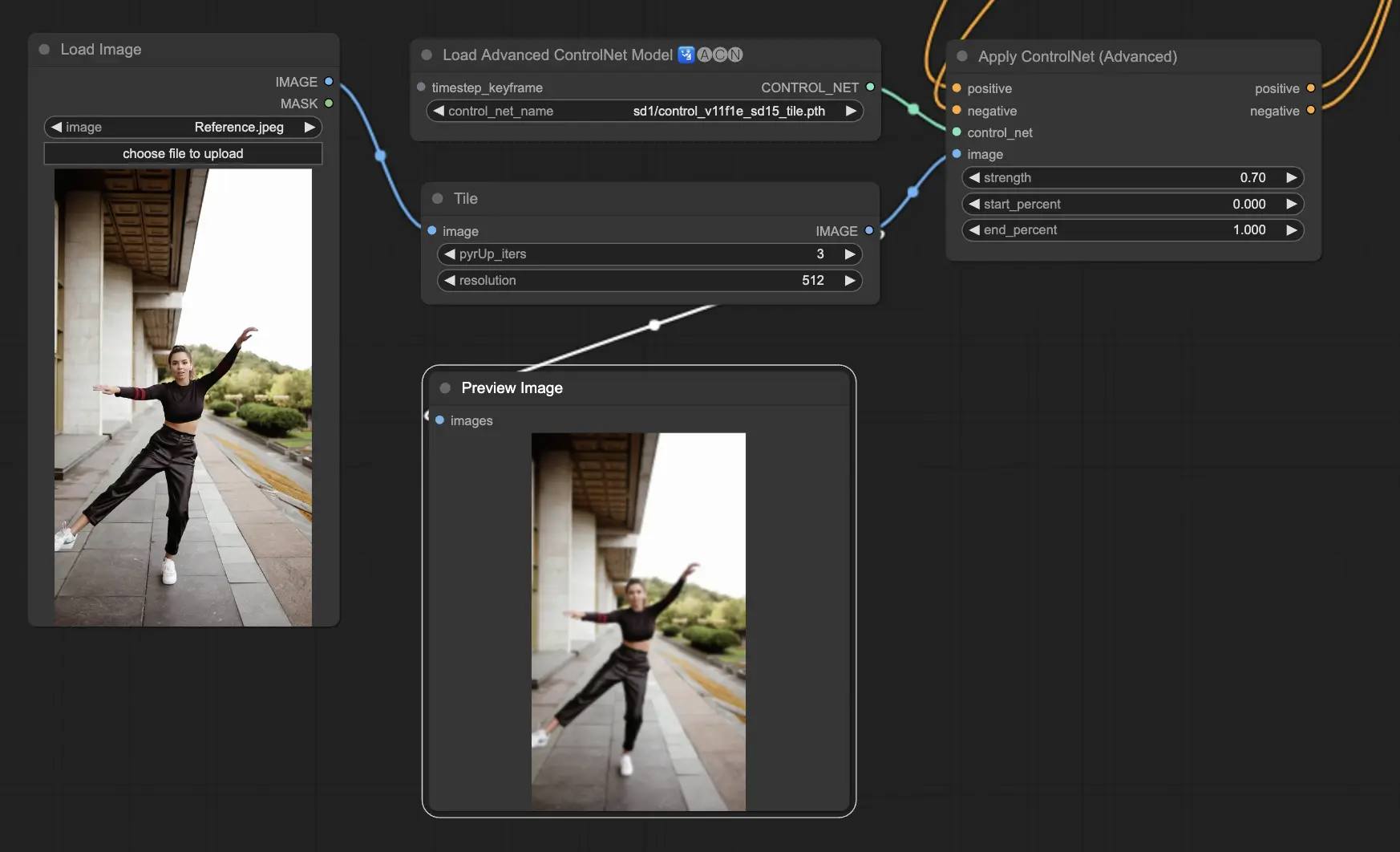
5.2. ComfyUI ControlNet Tile#
Tile Resampleモデルは、画像の細部を強調するために使用されます。画像解像度を向上させながらも細かいディテールを追加するため、アップスケーラーと一緒に使用するのが特に有効です。画像内のテクスチャや要素を鮮明にし、豊かにするためによく利用されます。
Preprocessor: Tile
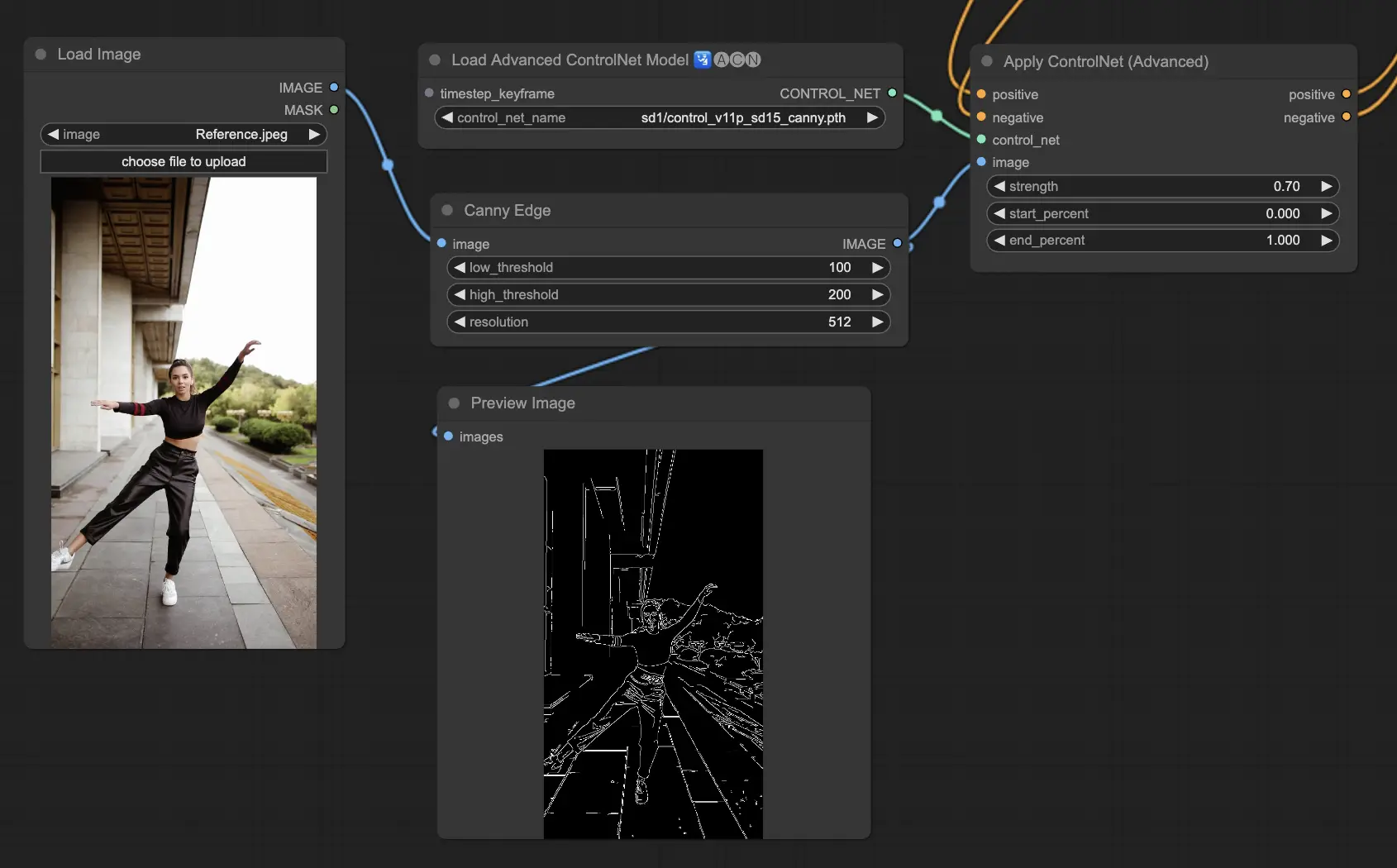
5.3. ComfyUI ControlNet Canny#
Cannyモデルは、多段階のプロセスであるCannyエッジ検出アルゴリズムを適用し、画像内の幅広いエッジを検出します。このモデルは、画像の構造的な側面を保存しながらも視覚的な構成を簡略化するのに役立ちます。スタイリッシュなアートや、他の画像操作のための前処理として有用です。
Preprocessors: Canny
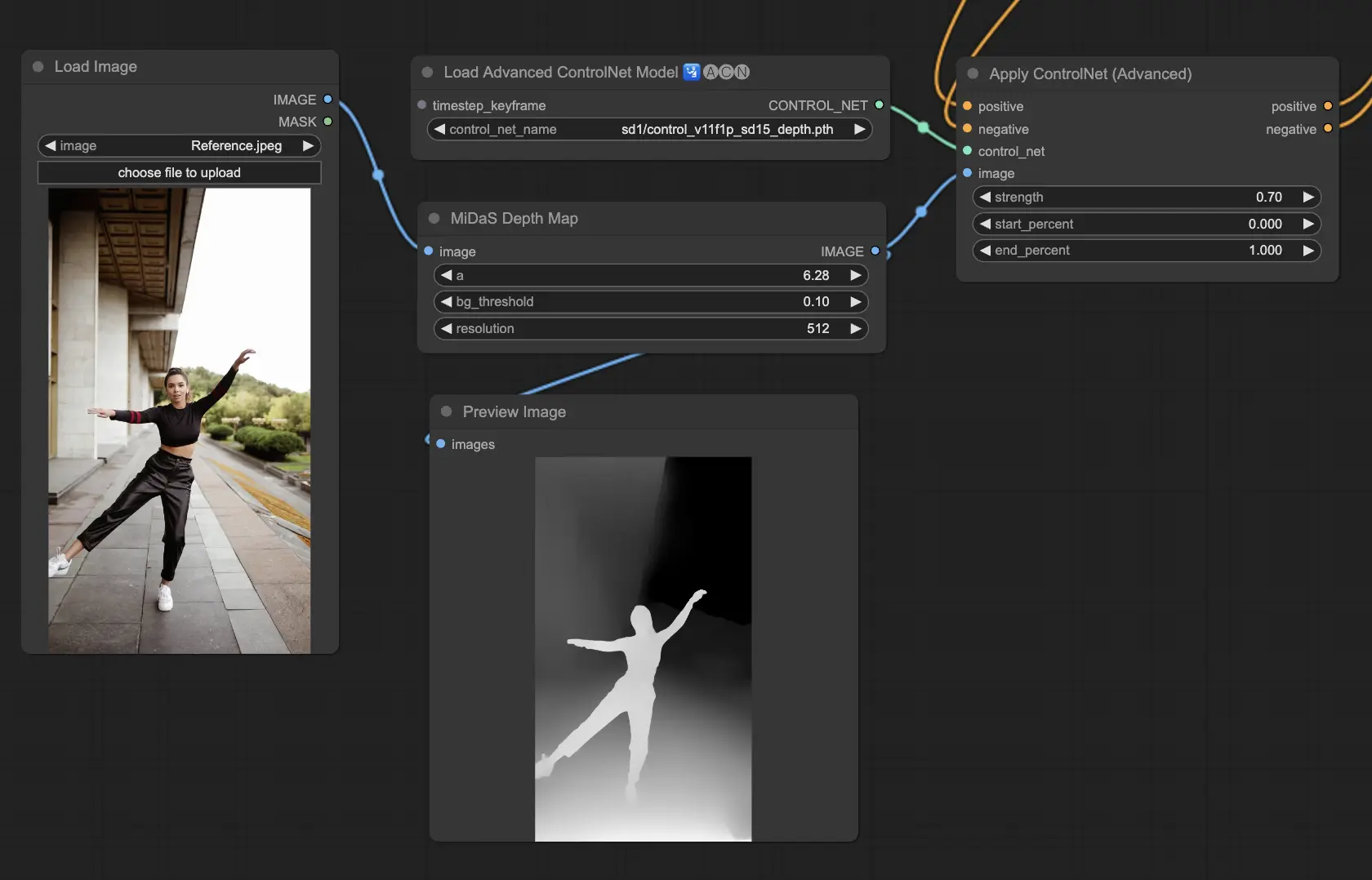
5.4. ComfyUI ControlNet Depth#
Depthモデルは、2D画像から深度情報を推定し、知覚された距離をグレースケールの深度マップに変換します。それぞれのバリアントは、ディテールのキャプチャと背景の強調のバランスが異なります。
- Depth Midas: クラシックな深度推定を提供し、ディテールと背景のレンダリングのバランスをとります。
- Depth Leres: 背景要素をより多く含める傾向を持ちながら、ディテールの強調に焦点を当てています。
- Depth Leres++: 複雑なシーンに最適な、深度情報の高度なレベルのディテールを提供します。
- Zoe: MidasとLeresモデルの間で、ディテールレベルのバランスをとります。
- Depth Anything: 幅広いシーンに対応するよう設計された、深度推定のための新しい改良されたモデルです。
- Depth Hand Refiner: 深度マップにおいて手のディテールを改善するために特別に設計されており、手の位置が重要なシーンで役立ちます。
Preprocessors: Depth_Midas, Depth_Leres, Depth_Zoe, Depth_Anything, MeshGraphormer_Hand_Refiner。このモデルは非常に堅牢で、レンダリングエンジンからの実際の深度マップでも機能します。
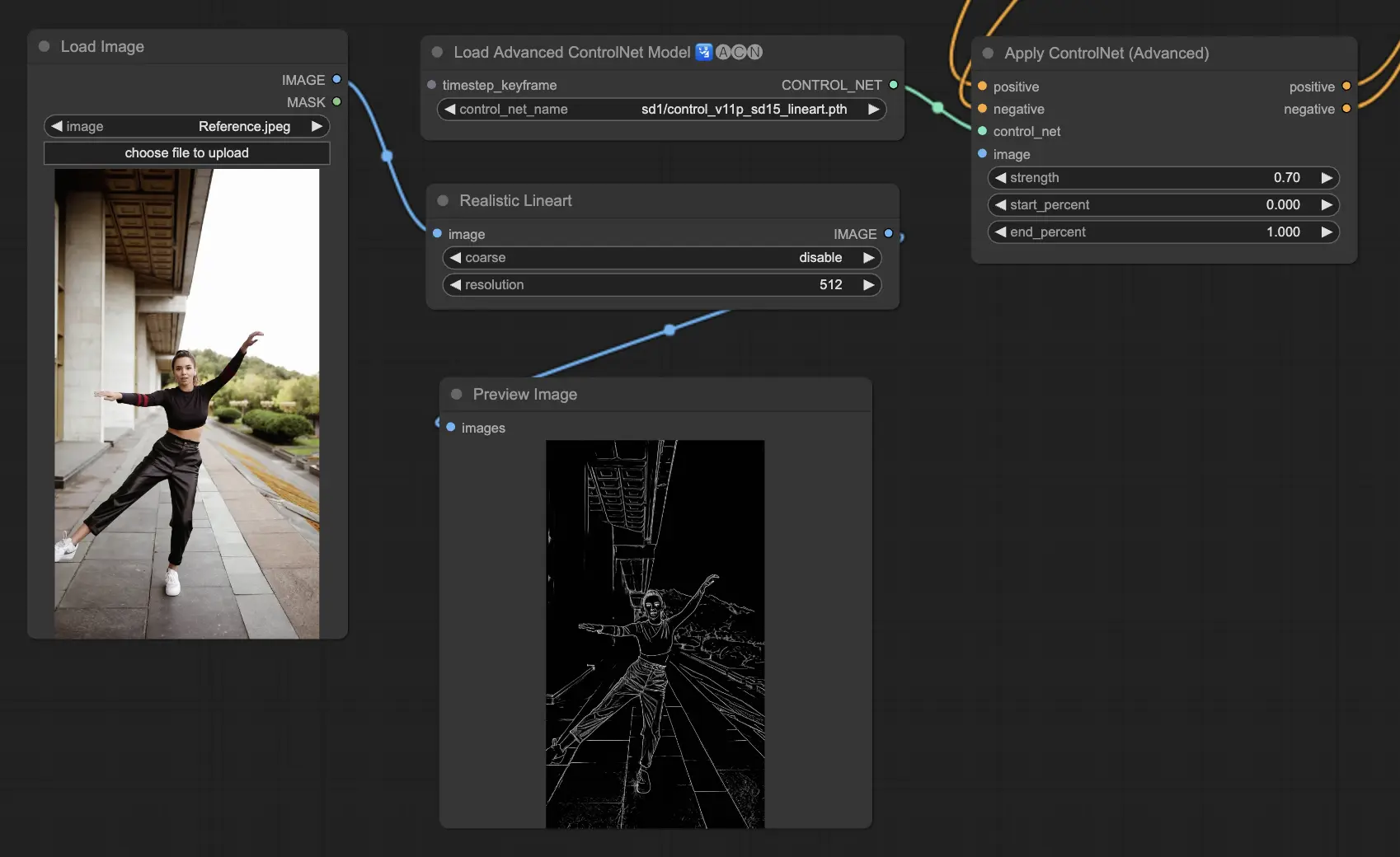
5.5. ComfyUI ControlNet Lineart#
Lineartモデルは画像をスタイリッシュな線画に変換し、芸術的なレンダリングや創造的な作業の基礎として有用です。
- Lineart: この標準的なモデルは、画像をスタイリッシュな線画に変換し、様々な芸術的や創造的なプロジェクトのための汎用性のある基礎を提供します。
- Lineart anime: アニメ風の線画を生成することに焦点を当てており、クリーンで正確な線で特徴付けられています。アニメの美的感覚を目指すプロジェクトに適しています。
- Lineart realistic: より写実的なタッチで線画を生成し、より詳細に被写体の本質をとらえ、写実的な表現を必要とするプロジェクトに最適\u3067す。
- Lineart coarse: より重めで大胆な線を使用し、目を引く印象的な効果を生み出します。大胆な芸術的表現に特に適しています。
プリプロセッサは画像から詳細または粗いラインアートを生成できます(LineartとLineart_Coarse)。
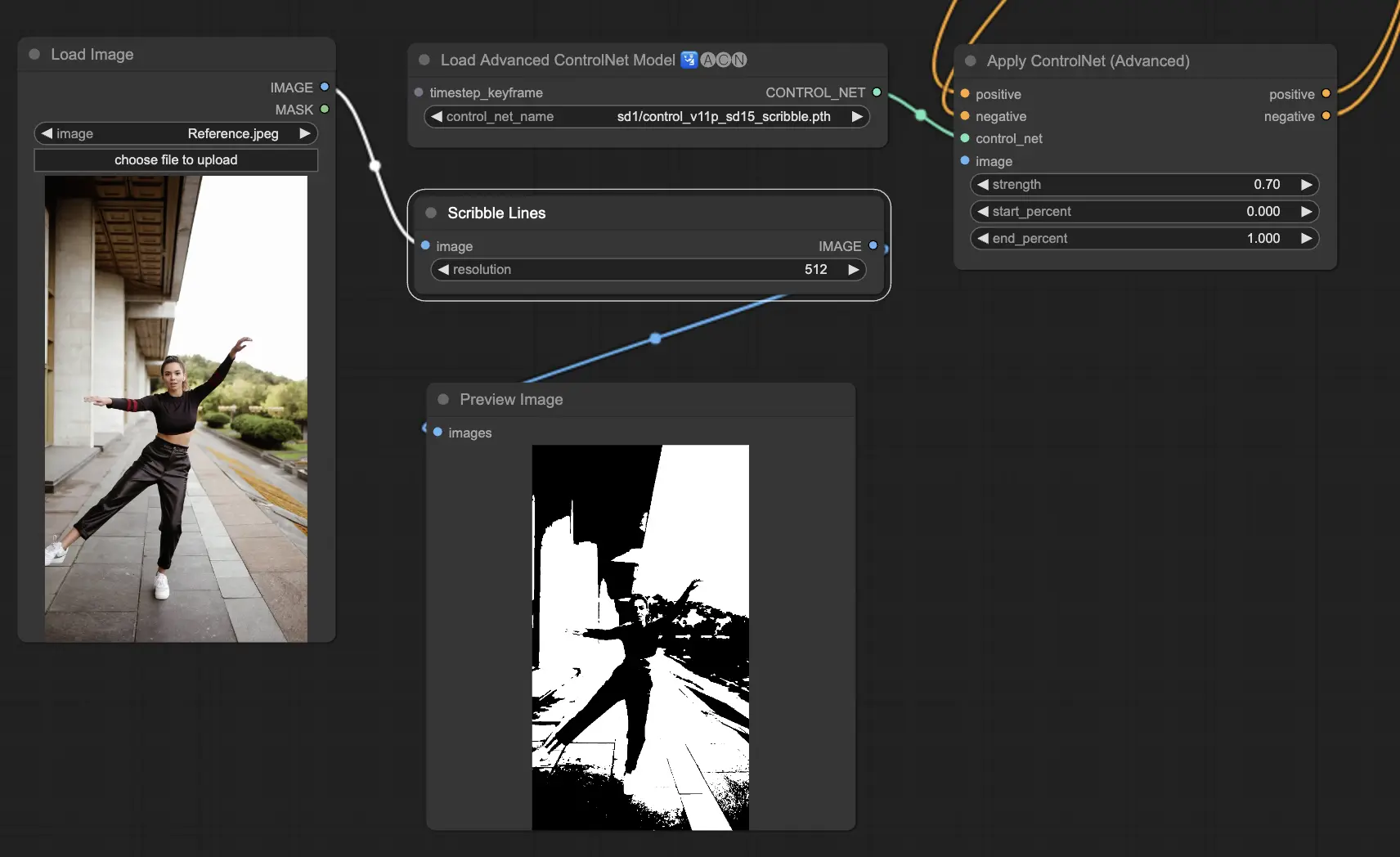
5.6. ComfyUI ControlNet Scribbles#
Scribbleモデルは、画像を手書きのスケッチのような外見に変換するよう設計されています。芸術的なリスタイルや大規模なデザインワークフローの予備段階として特に有用です。
- Scribble: 画像を手書きのスクリブルやスケッチをシミュレーションした詳細なアートワークに変換するよう設計されています。
- Scribble HED: ホリスティック・ネスト・エッジ検出(HED)を利用して、手書きのスケッチに似たアウトラインを作成します。画像の再色とリスタイルに推奨され、アートワークにユニークな芸術的フレアを加えます。
- Scribble Pidinet: ピクセルの差異の検出に焦点を当て、ディテールを減らしたよりクリーンな線を生成します。よりクリアで抽象的な表現に最適です。Scribble Pidinetは、必要なディテールを保持しながらもクリスプな曲線とまっすぐなエッジを求める人には完璧で、洗練された見た目を提供します。
- Scribble xdog: 拡張差分ガウシアン(xDoG)法を用いてエッジ検出を行います。これにより、スクリブル効果を微調整するための調整可能なしきい値設定が可能になり、アートワークでディテールのレベルをコントロールできるようになります。xDoGは汎用性が高く、ユーザーが芸術的な創作物で完璧なバランスを見出すのに役立ちます。
Preprocessors: Scribble, Scribble_HED, Scribble_PIDI, Scribble_XDOG
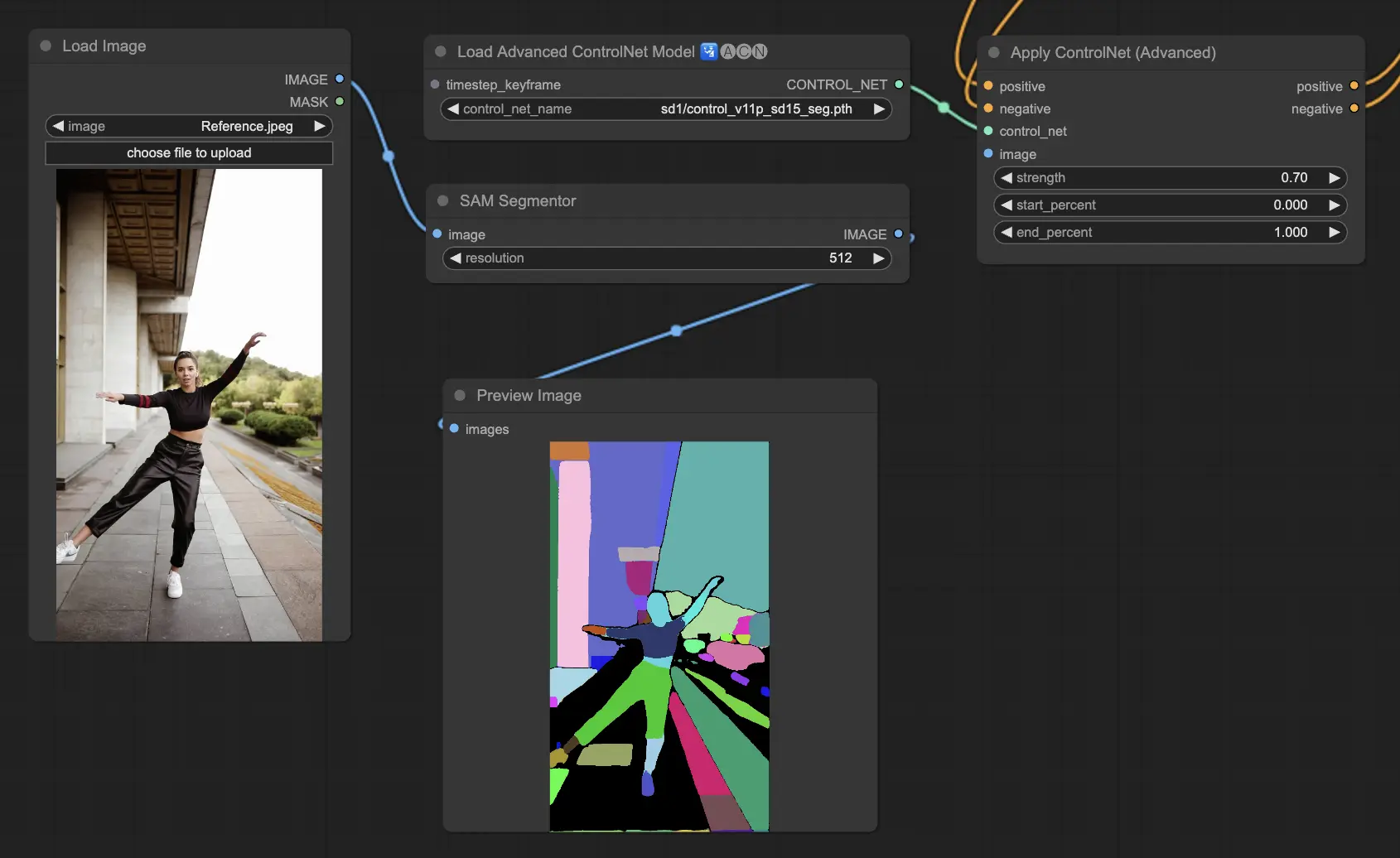
5.7. ComfyUI ControlNet Segmentation#
Segmentationモデルは、画像のピクセルを異なるオブジェクトクラスに分類し、それぞれに特定の色で表現します。これは、画像内の個々の要素を識別して操作するために非常に価値があり、前景と背景を分離したり、詳細な編集のためにオブジェクトを区別したりします。
- Seg: 画像内のオブジェクトを色で区別し、それらの区別を出力内の異なる要素に効果的に翻訳するよう設計されています。例えば、部屋のレイアウトで家具を分離することができ、画像の構成と編集の正確なコントロールが必要なプロジェクトに特に価値があります。
- ufade20k: ADE20KデータセットでトレーニングされたUniFormerセグメンテーションモデルを使用し、高い精度で幅広い種類のオブジェクトを識別できます。
- ofade20k: ADE20KでトレーニングされたOneFormerセグメンテーションモデルを採用し、独自のセグメンテーション機能でオブジェクトの区別に対する代替アプローチを提供します。
- ofcoco: COCOデータセットでトレーニングされたOneFormerセグメンテーションを活用し、COCOデータセットのパラメーター内で分類されたオブジェクトを含む画像に特化し、正確なオブジェクト識別と操作を容易にします。
Acceptable Preprocessors: Sam, Seg_OFADE20K (Oneformer ADE20K), Seg_UFADE20K (Uniformer ADE20K), Seg_OFCOCO (Oneformer COCO), または手動で作成したマスク。
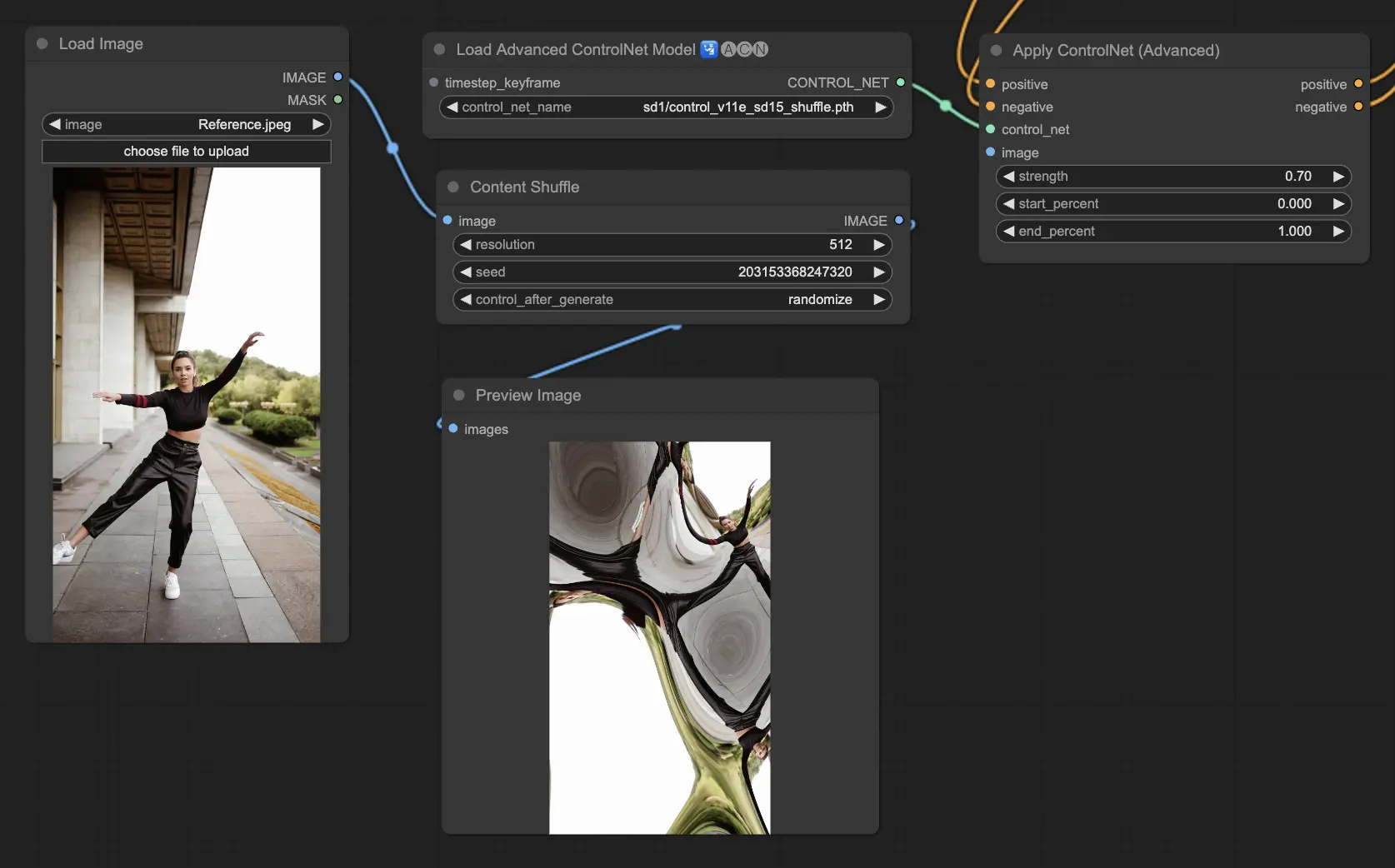
5.8. ComfyUI ControlNet Shuffle#
Shuffleモデルは、構成を変更することなく入力画像の属性(色のスキームやテクスチャなど)をランダム化するという新しいアプローチを導入しています。このモデルは、クリエイティブな探索や、構造的な整合性を保ちながらも視覚的美学を変えた画像のバリエーションを生成するのに特に効果的です。そのランダム性から、生成プロセスで使用されるシード値の影響を受けて、出力はそれぞれユニークになります。
Preprocessors: Shuffle
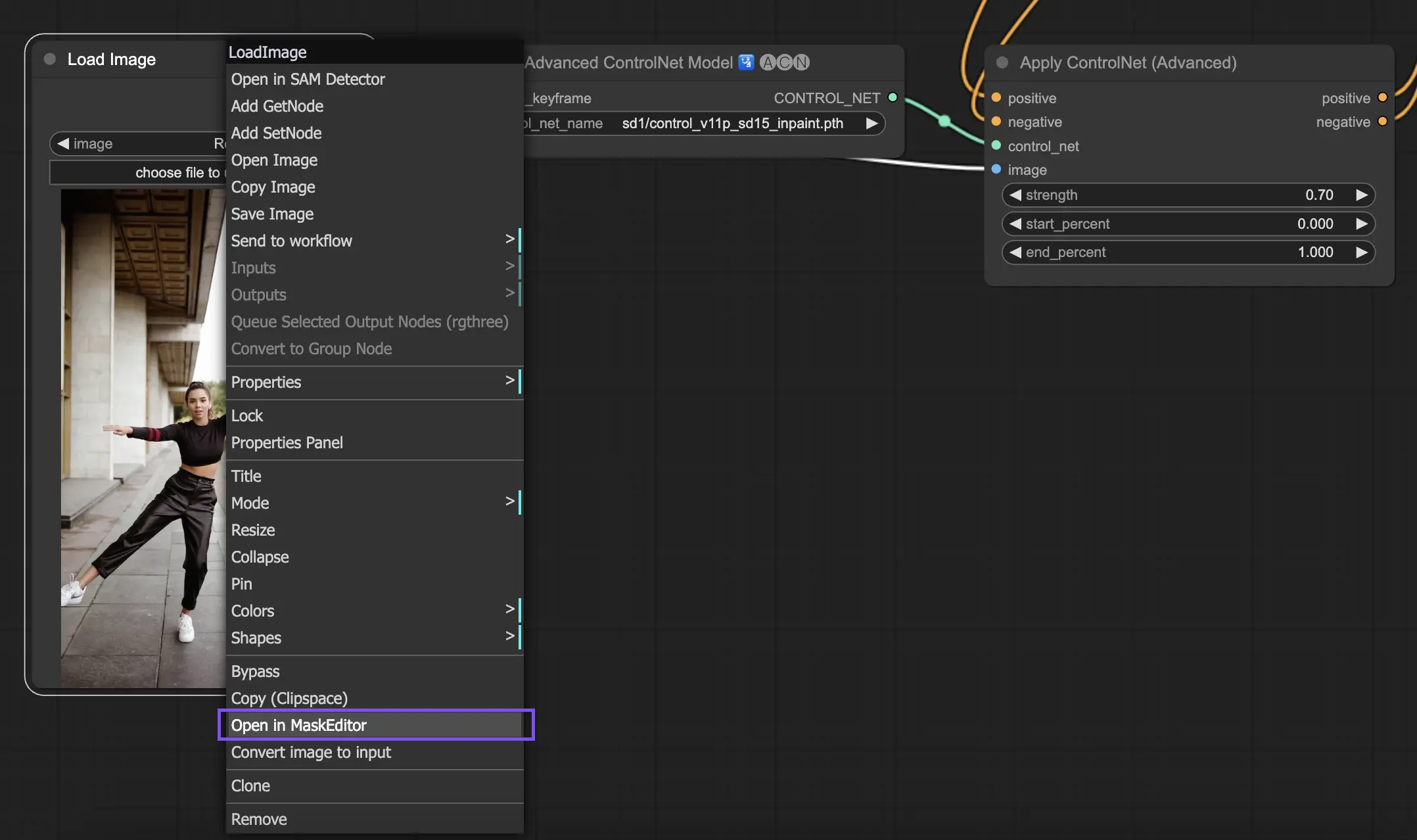
5.9. ComfyUI ControlNet Inpainting#
ControlNet内のInpaintingモデルは、全体の一責性を維持しながらも、画像の特定の領域内で大幅な変更や修正を導入することで、細かい編集が可能になります。
ControlNet Inpaintingを使用するには、まずマスキングを通して再生成したい領域を分離します。これは、目的の画像を右クリックして「Open in MaskEditor」を選択し、修正を加えることで行えます。
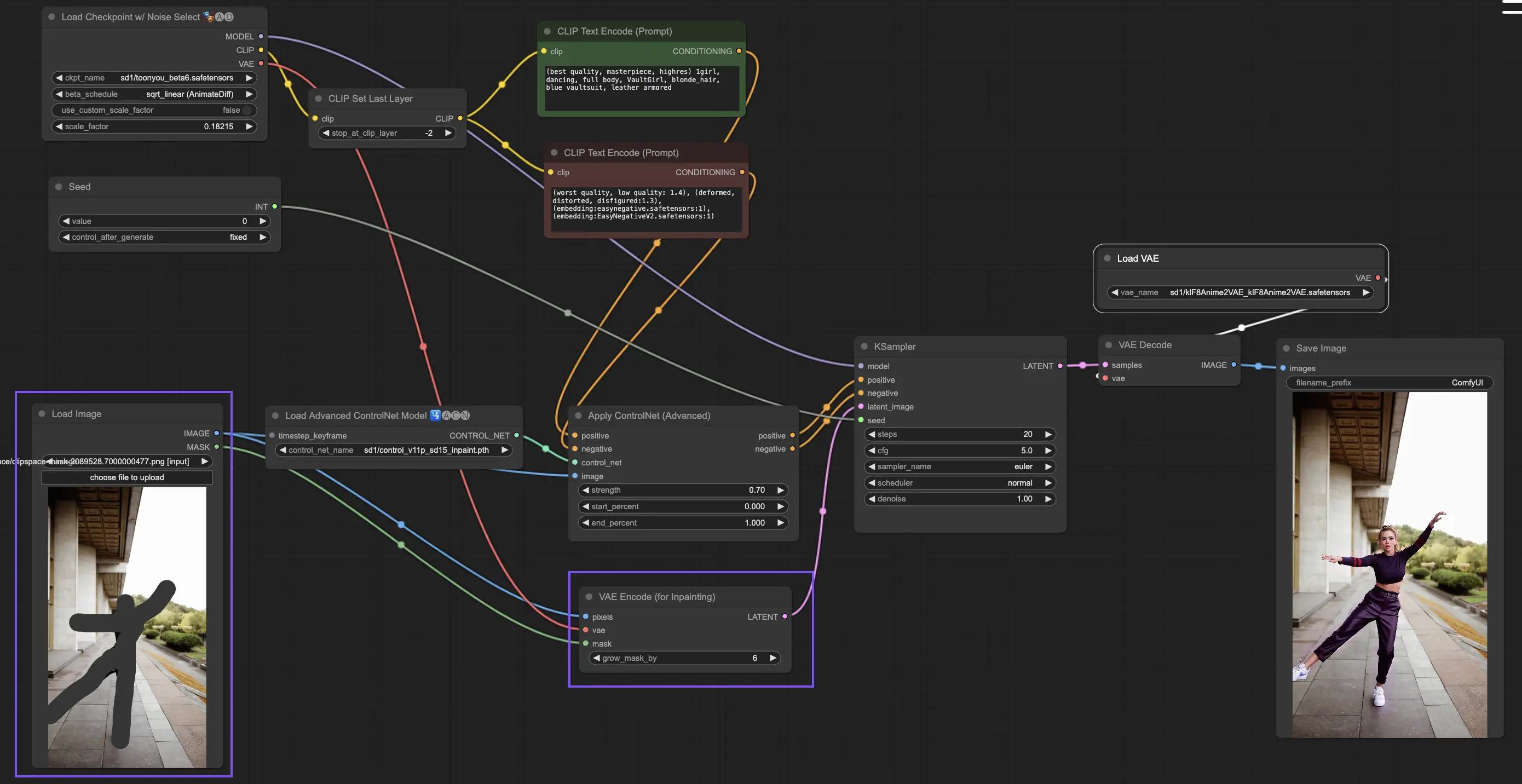
ControlNet内の他の実装とは異なり、Inpaintingは画像に直接修正を加えるため、プリプロセッサーを介さないで済みます。しかし、編集した画像を潜在空間を介してKSamplerに転送することが重要です。これにより、拡散モデルがマスクされた領域のみを再生成することに集中し、マスクされていない領域の整合性を維持することが保証されます。
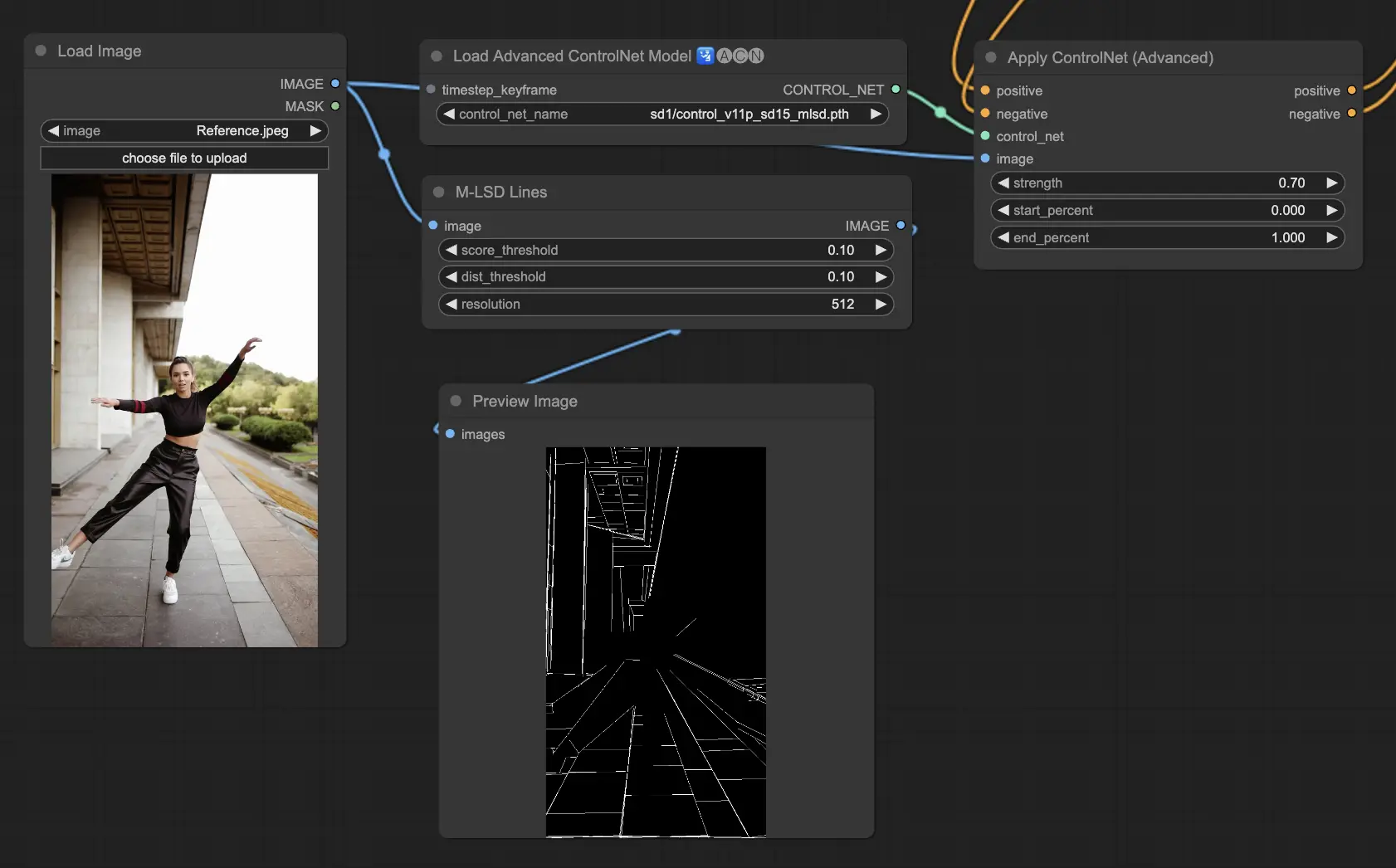
5.10. ComfyUI ControlNet MLSD#
M-LSD(モバイル線分検出)は、直線の検出に焦点を当てており、建築物や室内、幾何学的なフォームなど、強い構造的要素を持つ画像に理想的です。シーンを構造的な本質に単純化し、人工物の環境を含むクリエイティブなプロジェクトを容易にします。
Preprocessors: MLSD。
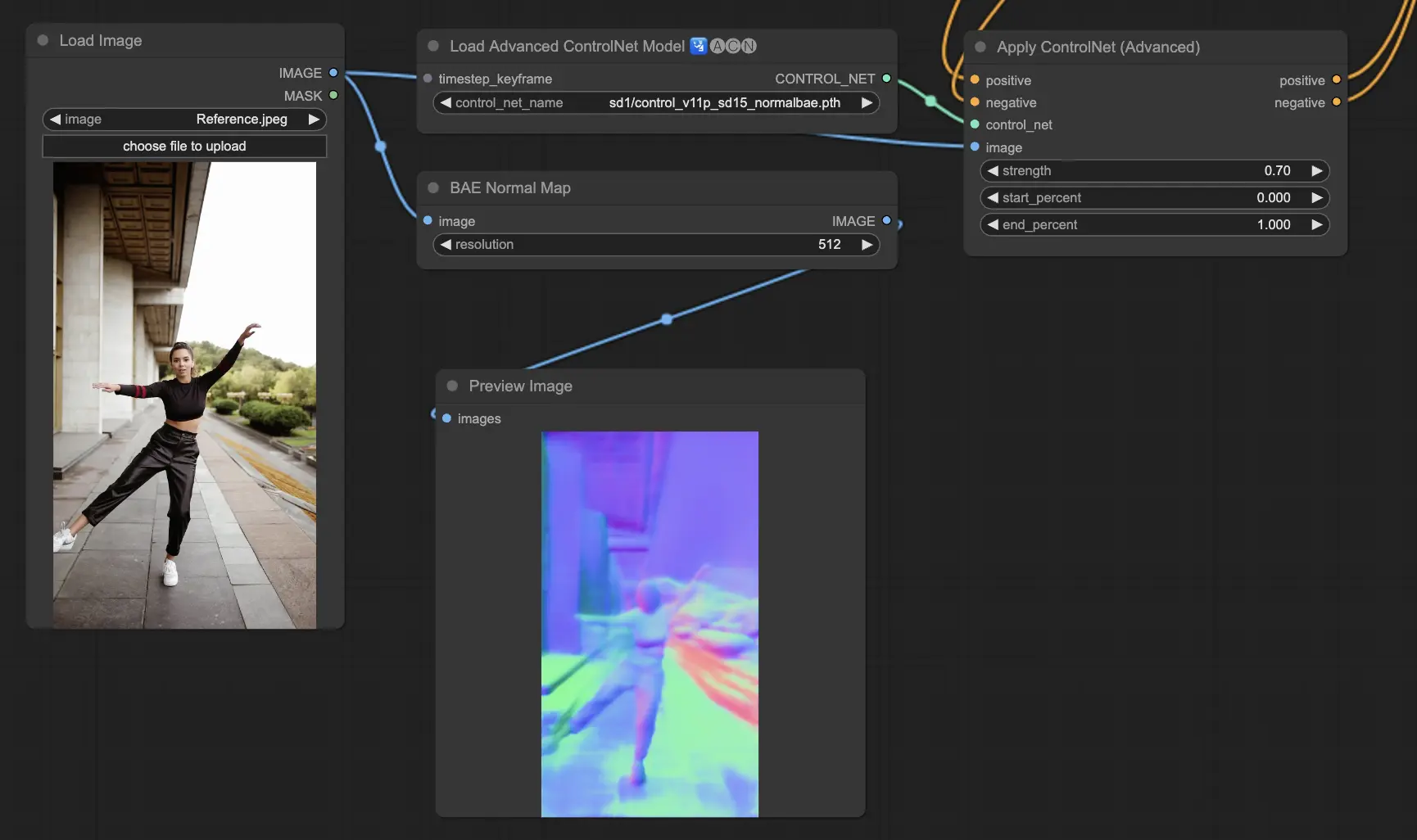
5.11. ComfyUI ControlNet Normalmaps#
Normalmapsは、色情報だけではなく、視覚シーンの中で表面の向きをモデル化することで、複雑な照明とテクスチャ効果のシミュレーションを可能にします。これは3Dモデリングとシミュレーションのタスクに不可欠です。
- Normal Bae: この方法は、正規の不確定性のアプローチを活用して正規マップを生成します。表面の向きを表現するのに革新的な方法を提供し、得られたシーンの物理的形状ではなく、従来の色情報に基づく方法に基づいて照明効果のシミュレーションを向上させます。
- Normal Midas: Midasモデルで生成された深度マップを使用して、正規マップを正確に推定します。このアプローチは、シーンの深度情報に基づいて、表面のテクスチャと照明の細かなシミュレーションを可能にし、3Dモデルの視覚的複雑さを高めます。
Preprocessors: Normal BAE, Normal Midas
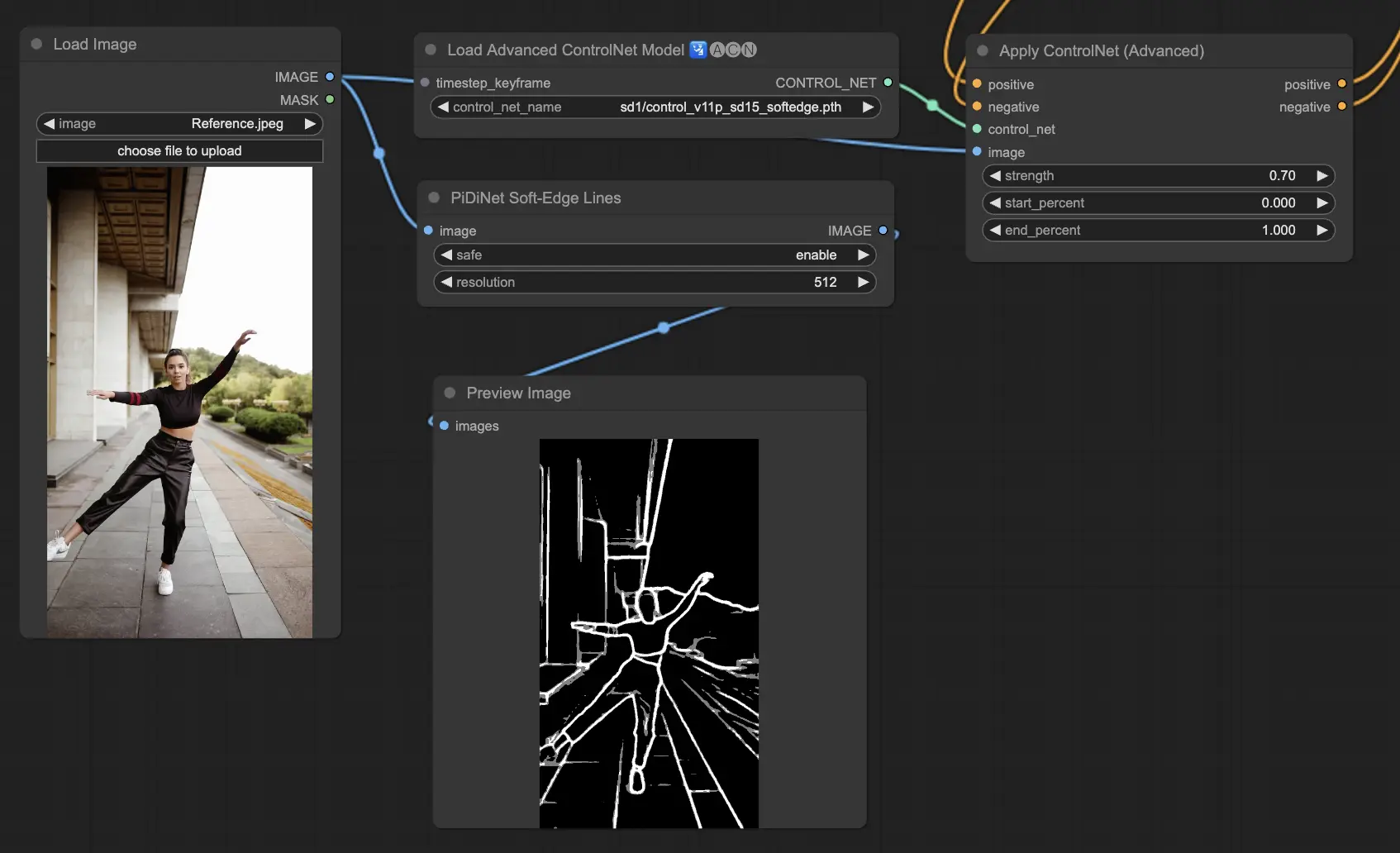
5.12. ComfyUI ControlNet Soft Edge#
ControlNet Soft Edgeは、エッジをより柔らかくした画像を生成するよう設計されており、詳細のコントロールと自然な外観に重点を置いています。高度なニューラルネットワーク技術を使用して、画像を正確に操作し、より大きな創造の自由とシームレスなブレンディング機能を提供します。
堅牢性: SoftEdge_PIDI_safe > SoftEdge_HED_safe >> SoftEdge_PIDI > SoftEdge_HED
最大の結果品質: SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
トレードオフを考えると、デフォルトでSoftEdge_PIDIを使用することをお勧めします。ほとんどの場合、非常にうまく機能します。
Preprocessors: SoftEdge_PIDI, SoftEdge_PIDI_safe, SoftEdge_HED, SoftEdge_HED_safe。
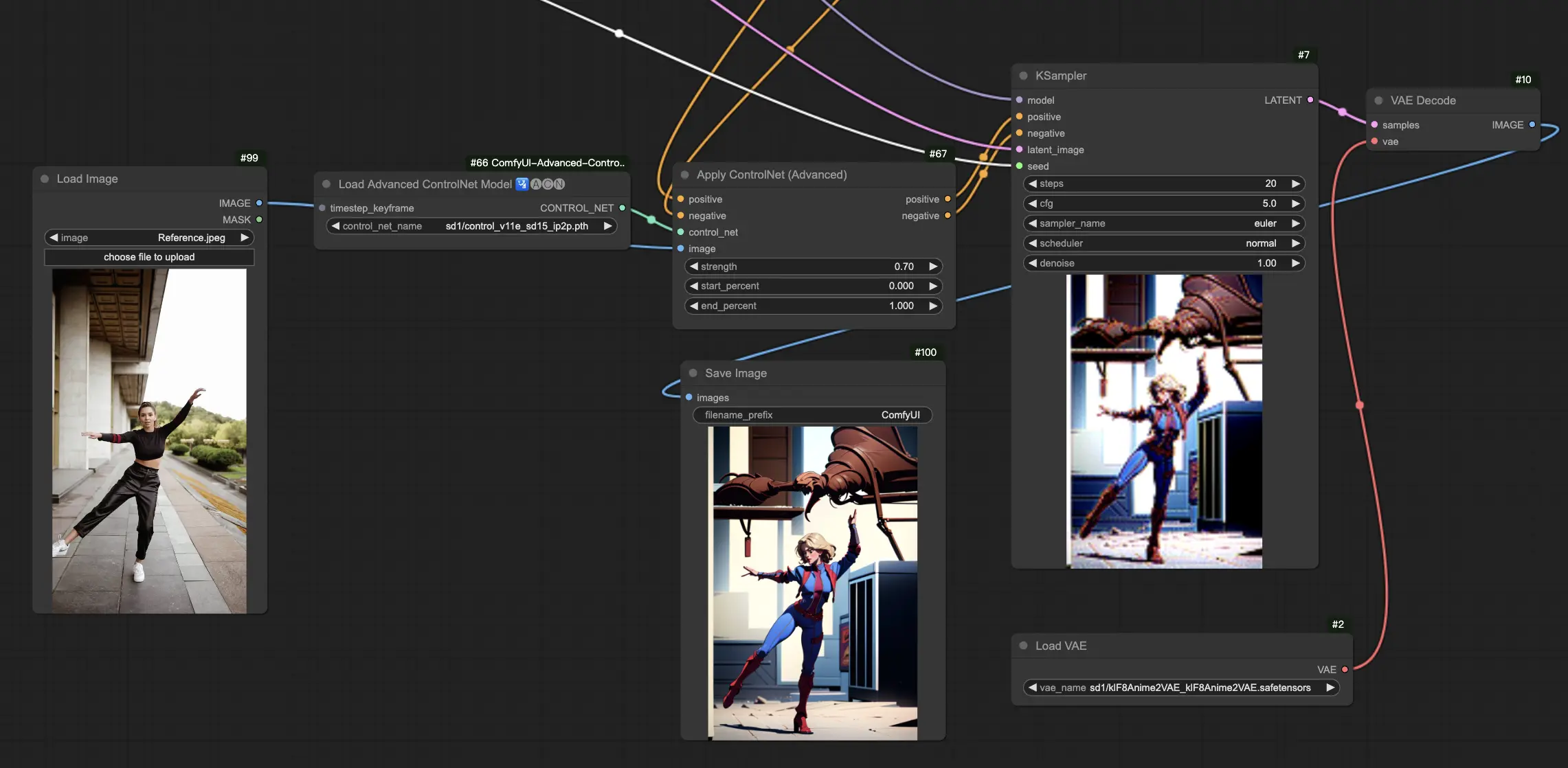
5.13. ComfyUI ControlNet IP2P (Instruct Pix2Pix)#
ControlNet IP2P (Instruct Pix2Pix) モデルは、ControlNetフレームワーク内でユニークな適応として障害を生じ、画像変換のためにInstruct Pix2Pixデータセットを活用するよう調整されています。このControlNetバリアントは、トレーニング段階で指示プロンプトと説明プロンプトのバランスをとることで障害を生じています。公式Instruct Pix2Pixの一般的なアプローチとは異なり、ControlNet IP2Pは、これらのプロンプトタイプの50/50のミックスを取り入れ、多用性と望ましい結果を生み出す効果を高めています。
5.14. ComfyUI T2I Adapter#
t2iadapter color: t2iadapter_colorモデルは、テキストから画像への拡散モデルを使用する際に、生成される画像の色の表現と精度を向上させることに特化しています。色の適応に焦点することで、このモデルは、テキストプロンプトで提供される記述に寄り添った、より正確で鮮やかな色のパレットを実現できます。色の微妙さと特殊性が重要なプロジェクトで特に有用で、生成された画像に新たなリアリティと詳細を加えます。
t2iadapter style: t2iadapter_styleモデルは、画像生成のスタイル的側面を対象とし、出力画像の芸術的スタイルの変更と制御を可能にします。このアダプターは、テキストプロンプトに記述された特定の芸術的スタイルや美的感覚に応じた\u753b像を生成するよう、テキストから画像へのモデルをガイドします。画像のスタイルが重要な役割を果たすクリエイティブなプロジェクトには欠かせないツールであり、伝統的なアートスタイルと最新のAI機能をシームレスに融合する方法を提供します。
5.15. 他の人気のComfyUI ControlNet: QRCode MonsterとIP-Adapter#
これらのセグメントについては、負っている情報量が多いため、別の記事で詳しく紹介します。
6. 複数のComfyUI ControlNetの使い方#
ComfyUIで複数のComfyUI ControlNetを使用するには、ポーズや形状、スタイル、色など、様々な側面をより正確に制御するために、ControlNetモデルを重ねたり連続したりするプロセスが含まれます。
したがって、ControlNet(例えばOpenPose)を適用し、その出力を別のControlNet(例えばCanny)にフィードすることで、ワークフローを構築できます。このようなControlNetの重層的な適用により、各ControlNetがそれぞれ特有の変換や制御を適用し、画像の詳細なカスタマイズが可能になります。このプロセスにより、異なるControlNetにガイドされる複数の側面を統合して、最終的な出力を精密に制御できるようになります。
🌟🌟🌟 ComfyUIオンライン - 今すぐControlNetのワークフローを体験🌟🌟🌟#
ControlNetワークフローを探索したい方は、次のComfyUI Webをご利用ください。必要なカスタマーノードとモデルが全てそろっており、手動設定不要でスムーズに創造活動ができます。今すぐControlNetの機能を体験し、その使い方を習得してください!