
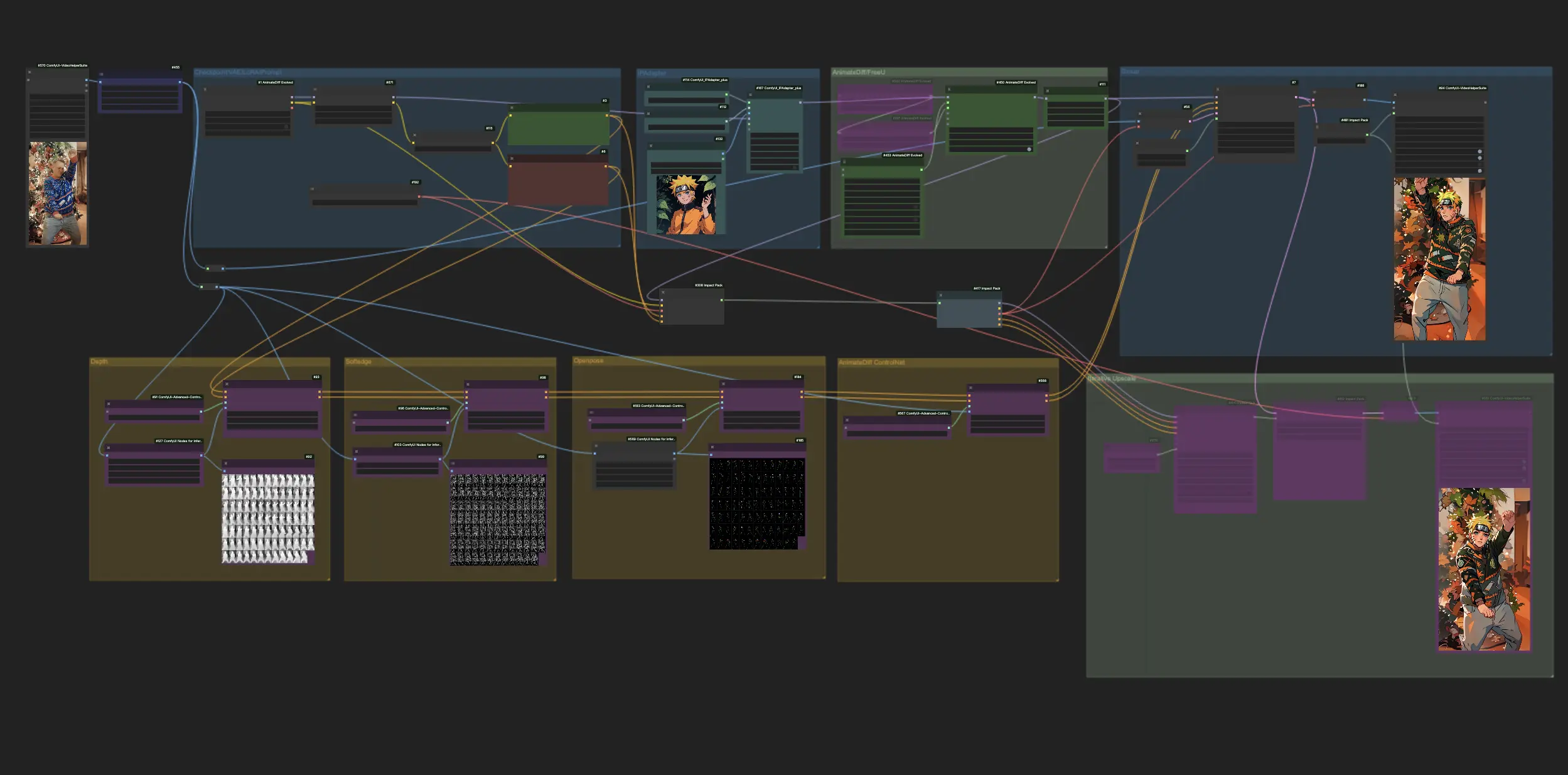
このワークフローは、enigmatic_eに触発され、いくつかの修正を加えたものです。詳細については、彼のYouTubeチャンネルをご覧ください。
1. ComfyUIワークフロー:AnimateDiff + ControlNet + IPAdapter | 日本のアニメスタイル#
このワークフローでは、AnimateDiff、ControlNet、IPAdapterを使用して、標準のビデオを魅惑的な日本のアニメ作品に変換できます。様々なチェックポイント、LoRA設定、IPAdapterのリファレンス画像を試して、ユニークなスタイルを作り上げてください。アニメの世界でビデオに命を吹き込むための楽しくクリエイティブな方法です!
2. AnimateDiffの概要#
ComfyUIでAnimateDiffを使用する方法の詳細をご確認ください。
3. ControlNetの使用方法#
3.1. ControlNetの理解#
ControlNetは、テキスト・トゥ・イメージ・ディフュージョン・モデルに新しいレベルの空間制御をもたらすことで、画像生成の方法を革新しています。この最先端のニューラルネットワークアーキテクチャは、Stable Diffusionのような巨人と見事に連携し、数十億の画像から鍛え上げられた膨大なライブラリを活用して、空間のニュアンスを画像作成の核心に直接織り込みます。エッジのスケッチから人間のポーズのマッピング、深度知覚、ビジュアルのセグメンテーションまで、ControlNetは単なるテキストプロンプトの範囲をはるかに超えた方法でイメージを形作る力を与えてくれます。
3.2. ControlNetのイノベーション#
ControlNetの核心は、驚くほどシンプルです。まず、オリジナルモデルのパラメータの整合性を保護し、ベーストレーニングを維持します。そして、ControlNetは、モデルのエンコーディング層のミラーセットを導入しますが、ひねりを加えています:それらは "ゼロ畳み込み" を使用してトレーニングされています。出発点としてのこれらのゼロは、層が新しい空間条件をそっと折り込むことを意味し、モデルの元の才能が新しい学習経路に乗り出しても保存されることを保証します。
3.3. ControlNetとT2I-Adapterの理解#
ControlNetとT2I-Adapterはどちらも画像生成のコンディショニングにおいて重要な役割を果たしており、それぞれ独自の利点を提供しています。T2I-Adapterは、特に画像生成プロセスのスピードアップという点で、効率性で認知されています。それにもかかわらず、ControlNetは生成プロセスを複雑に導く能力において比類なく、クリエイターにとって強力なツールとなっています。
多くのT2I-AdapterとControlNetモデルの機能の重複を考慮して、私たちの議論は主にControlNetに焦点を当てます。しかし、RunComfyプラットフォームには、使いやすさのために、いくつかのT2I-Adapterモデルがプリロードされていることは注目に値します。T2I-Adapterを試してみたい方は、これらのモデルをシームレスにロードし、プロジェクトに統合することができます。
ComfyUIでControlNetとT2I-Adapterモデルを選択することは、ControlNetノードの使用やワークフローの一貫性に影響を与えません。この均一性により、プロジェクトのニーズに応じて各モデルタイプの独自の利点を活用しながら、合理化されたプロセスが保証されます。
3.4. ControlNetノードの使用#
3.4.1. "Apply ControlNet"ノードのロード
始めるには、"Apply ControlNet"ノードをComfyUIにロードする必要があります。これは、視覚的な要素とテキストプロンプトを融合させた二重条件付き画像作成の旅への最初のステップです。
3.4.2. "Apply ControlNet"ノードの入力の理解
ポジティブとネガティブのコンディショニング:これらは最終的な画像を形作るためのツールです。何を取り入れ、何を避けるべきかを決めます。これらを"Positive prompt"と"Negative prompt"スロットに接続して、創造的な方向性のテキストベースの部分と同期させます。
ControlNetモデルの選択:この入力を"Load ControlNet Model"ノードの出力にリンクする必要があります。ここで、目指す特定の特徴やスタイルに基づいて、ControlNetモデルまたはT2IAdaptorモデルを使用するかどうかを決定します。ControlNetモデルに焦点を当てていますが、バランスの取れた見方のために、いくつかの注目すべきT2IAdaptorについて言及する価値があります。
画像の前処理:画像を"ControlNet Preprocessor"ノードに接続することが、画像がControlNetの準備ができていることを確認するために不可欠です。プリプロセッサをControlNetモデルと一致させることが重要です。このステップは、元の画像をモデルのニーズに完全に適合するように調整します。リサイズ、再着色、または必要なフィルターを適用して、ControlNetで使用できるように準備します。
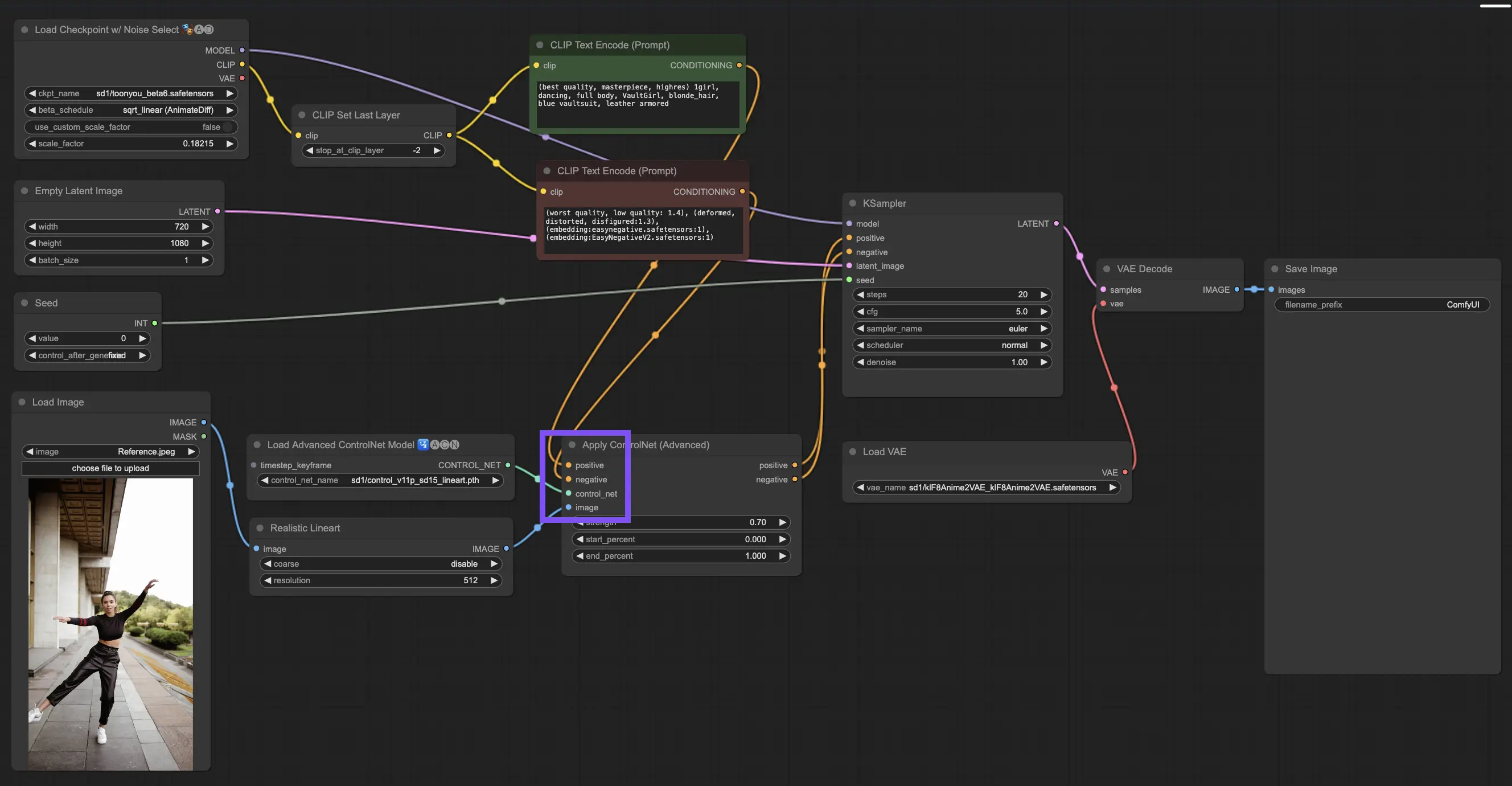
3.4.3. "Apply ControlNet"ノードの出力の理解
処理後、"Apply ControlNet"ノードは、ControlNetとあなたの創造的な入力の洗練された相互作用を反映した2つの出力を提示します:ポジティブとネガティブのコンディショニング。これらの出力は、ComfyUI内のディフュージョンモデルを導き、次の選択につながります:KSamplerを使用して画像を改良するか、比類のない詳細とカスタマイズを求める人のために、さらにControlNetを重ねるかです。
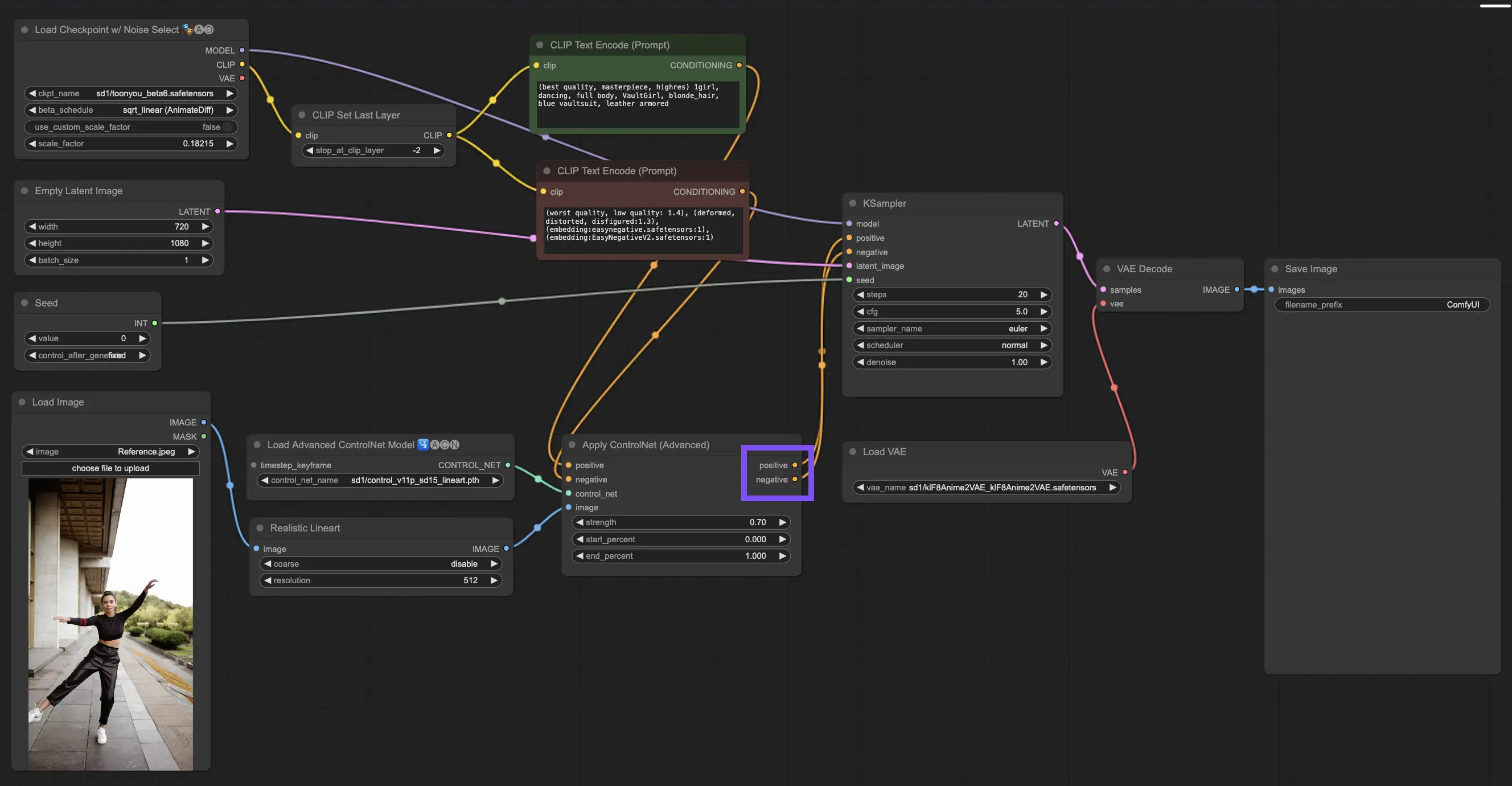
3.4.4. 最良の結果のための"Apply ControlNet"の調整
強度の決定:この設定は、ControlNetが結果の画像にどの程度影響を与えるかを制御します。完全な1.0は、ControlNetの入力が主導権を握っていることを意味し、0.0までダイヤルを下げると、ControlNetの影響なしでモデルが実行されます。
開始パーセントの調整:これは、ディフュージョンプロセス中にControlNetがいつ貢献し始めるかを示します。たとえば、20%の開始は、5分の1の時点からControlNetが印象を与え始めることを意味します。
終了パーセントの設定:これは開始パーセントの反対側であり、ControlNetがいつ姿を消すかを示します。80%に設定すると、画像が最終段階に近づくにつれてControlNetの影響が薄れ、最後の段階ではControlNetに触れられずに終了します。
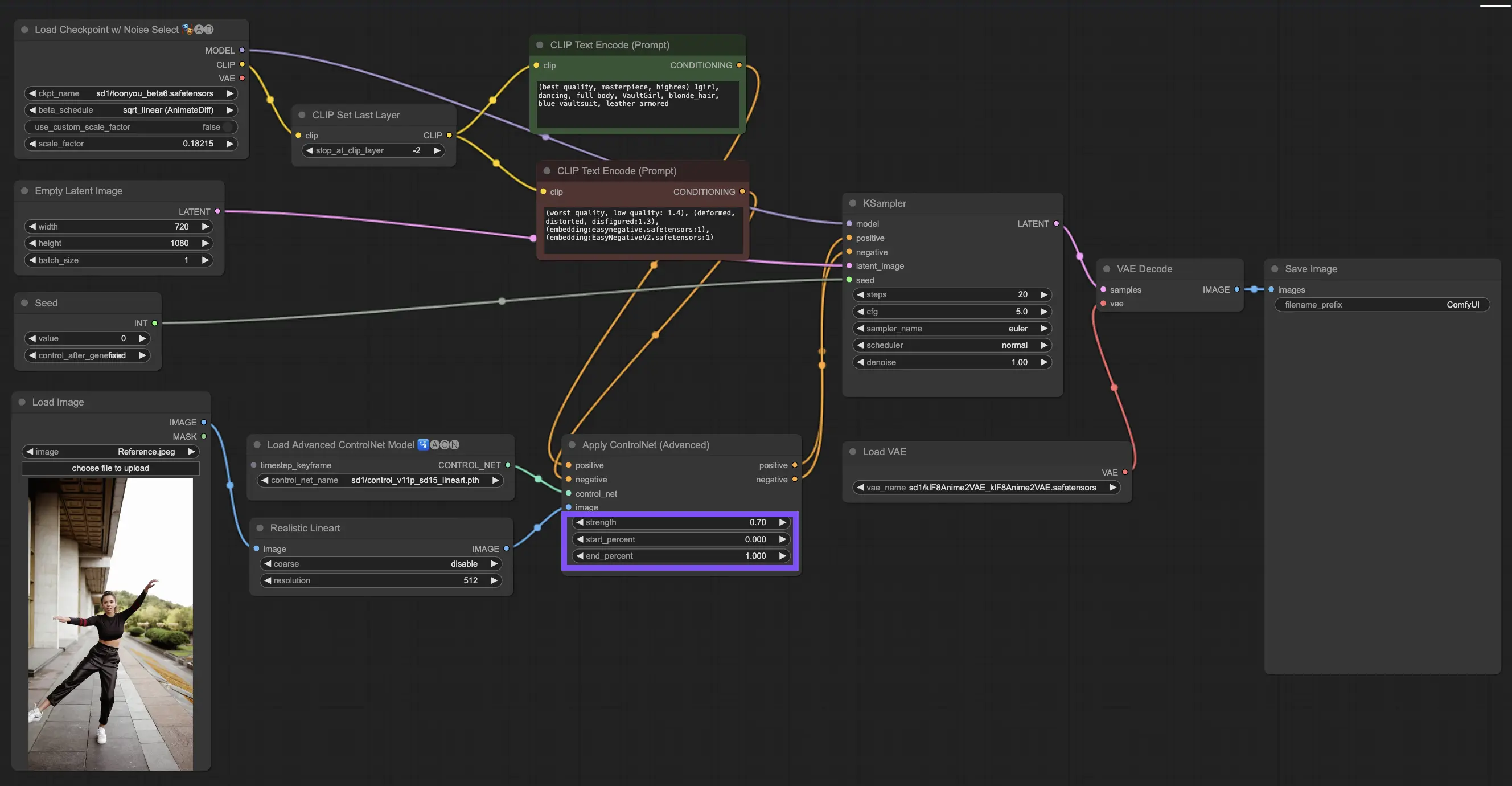
3.5. ControlNetモデルガイド:Openpose、Depth、SoftEdge、Canny、Lineart、Tile#
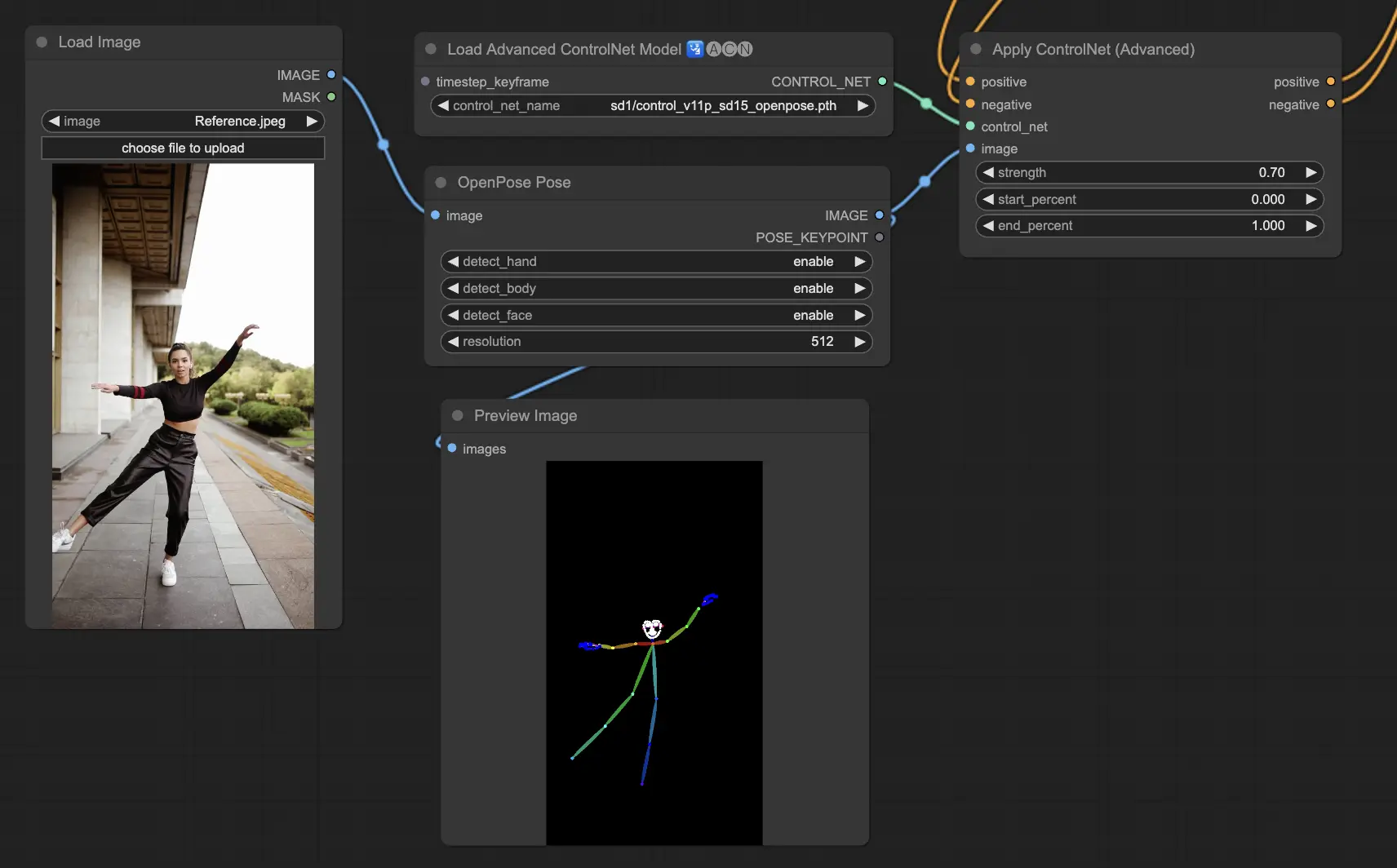
3.5.1. ControlNetモデル:Openpose
- Openpose(Openpose bodyとも呼ばれる):このモデルは、目、鼻、首、肩、肘、手首、膝、足首など、人体の主要なポイントを特定するためのControlNetの基礎として機能します。シンプルな人間のポーズを再現するのに最適です。
- Openpose_face:このOpenposeのバージョンは、顔の主要なポイントを検出することでさらに一歩進み、顔の表情と顔が向いている方向の微妙な分析を可能にします。プロジェクトが顔の表情を中心とする場合、このモデルは不可欠です。
- Openpose_hand:OpenposeモデルのこのエンハンスメントはV手と指の動きの細部に焦点を当てており、これは手のジェスチャーと位置の詳細な理解のために重要です。ControlNet内でOpenposeができることの範囲を広げます。
- Openpose_faceonly:顔の詳細分析に特化したこのモデルは、体のキーポイントをスキップして、顔の表情と向きだけに集中します。顔の特徴だけが重要な場合は、これが選ぶべきモデルです。
- Openpose_full:このオールインワンモデルは、Openpose、Openpose_face、Openpose_handの機能を統合し、全身、顔、手のキーポイント検出を行い、ControlNet内で包括的な人間のポーズ分析のための頼りになるモデルとなっています。
- DW_Openpose_full:Openpose_fullを基に、このモデルはポーズ検出の詳細と精度を向上させるさらなる機能強化を導入しています。ControlNetスイートで利用可能な最も高度なバージョンです。
プリプロセッサーのオプションには、OpenposeまたはDWposeが含まれます。
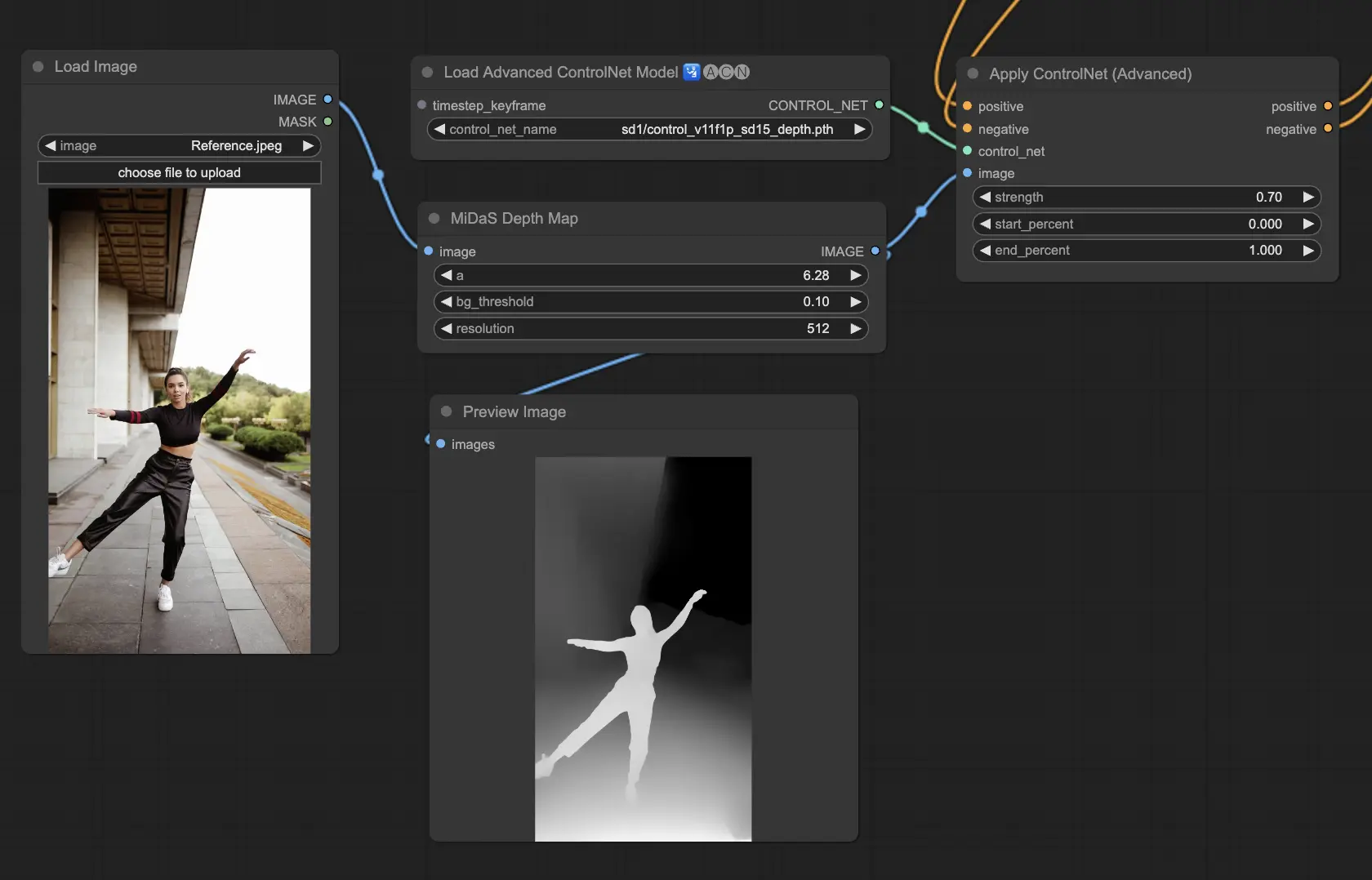
3.5.2. ControlNetモデル:Depth
Depthモデルは2D画像を使用して深度を推測し、それをグレースケールマップとして表現します。それぞれが詳細や背景の焦点の面で長所を持っています。
- Depth Midas:深度推定へのバランスの取れたアプローチであるDepth Midasは、ディテールと背景の描写の中間点を提供します。
- Depth Leres:背景要素をより目立たせながら、詳細を重視します。
- Depth Leres++:複雑なシーンに特に役立つ深度情報の詳細さを追求します。
- Zoe:MidasとLeresモデルの詳細レベルの間の平衡点を見つけます。
- Depth Anything:多様なシーンにわたって汎用的な深度推定のために改良されたモデルです。
- Depth Hand Refiner:深度マップ内の手の詳細を特異的に微調整し、手の正確な位置が不可欠なシーンにとって非常に価値があります。
検討すべきプリプロセッサ:Depth_Midas、Depth_Leres、Depth_Zoe、Depth_Anything、MeshGraphormer_Hand_Refiner。このモデルは、レンダリングエンジンからの実際の深度マップとの堅牢性と互換性に優れています。
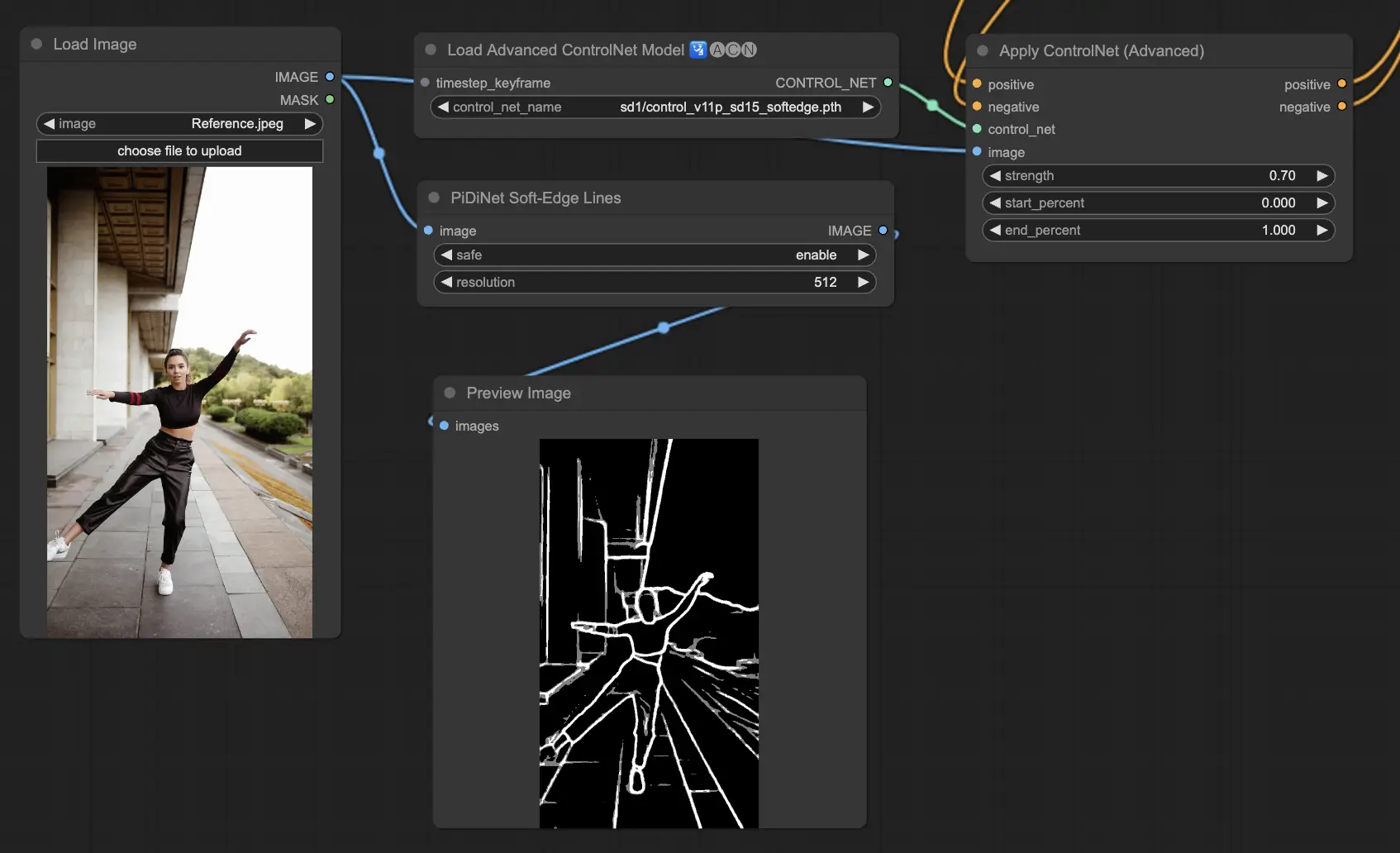
3.5.3. ControlNetモデル:SoftEdge
ControlNet Soft Edgeは、エッジを柔らかくしたイメージを生成するように作られており、自然な外見を保ちながら詳細を高めます。洗練された画像操作のために最先端のニューラルネットワークを利用し、広範なクリエイティブコントロールとシームレスな統合を提供します。
堅牢性の面では:SoftEdge_PIDI_safe > SoftEdge_HED_safe >> SoftEdge_PIDI > SoftEdge_HED
最高品質の結果のために:SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
一般的な推奨事項として、SoftEdge_PIDIは通常優れた結果を出すので定番の選択肢です。
プリプロセッサには、SoftEdge_PIDI、SoftEdge_PIDI_safe、SoftEdge_HED、SoftEdge_HED_safeが含まれます。
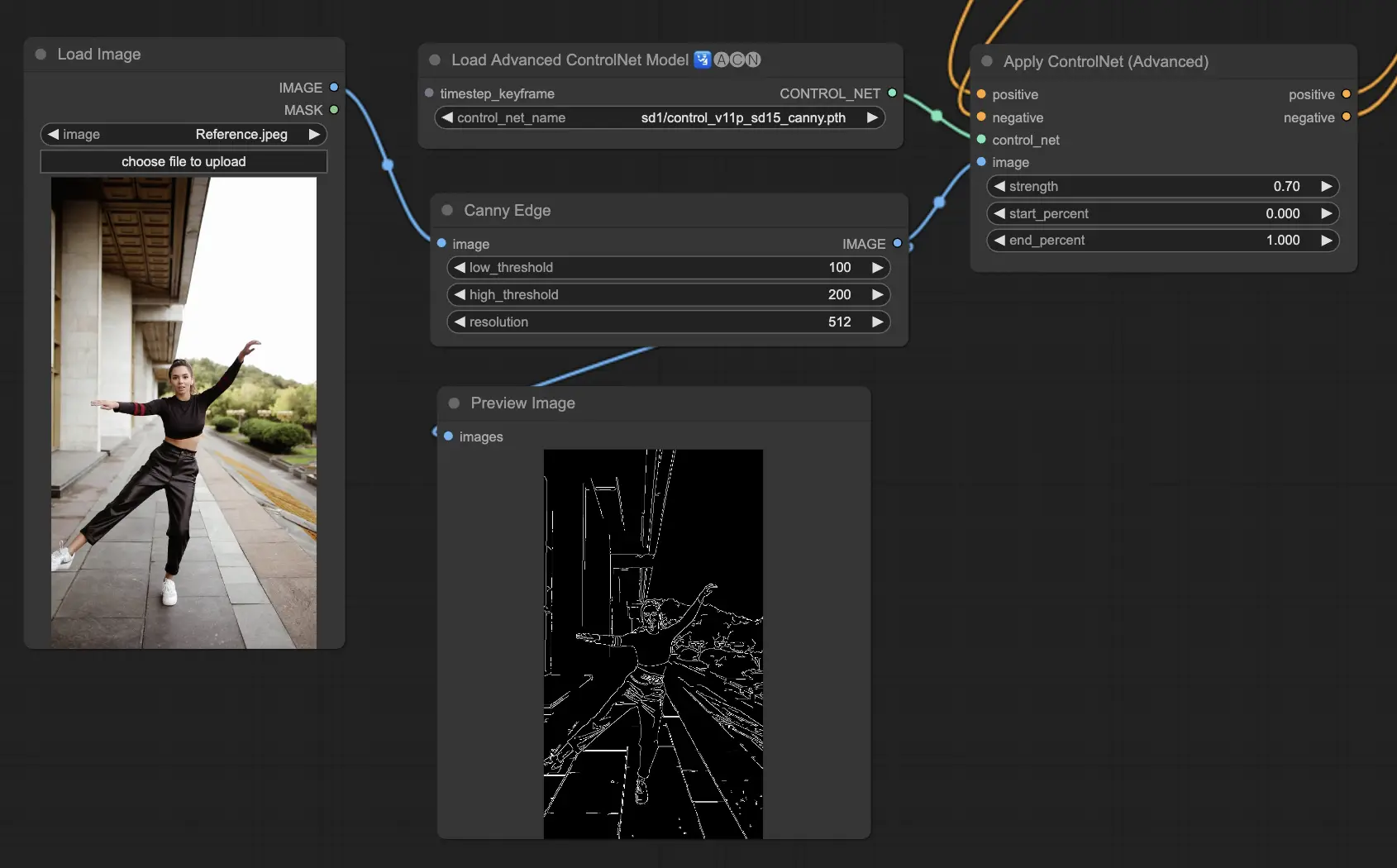
3.5.4. ControlNetモデル:Canny
Cannyモデルは、Cannyエッジ検出を実装して、画像内の幅広いエッジをハイライトします。このモデルは、画像の全体的な外観を単純化しながら、構造要素の完全性を維持するのに優れており、スタイル化されたアートの作成や、追加の操作のための画像の準備に役立ちます。
利用可能なプリプロセッサ:Canny
3.5.5. ControlNetモデル:Lineart
Lineartモデルは、画像をスタイライズされた線画に変換するためのツールであり、様々な芸術的用途に適しています。
- Lineart:画像を線画に変換するための標準的な選択肢で、様々な芸術的またはクリエイティブな努力のための汎用的な出発点を提供します。
- Lineart anime:アニメ風のクリーンで正確な線画を作成するために調整されており、アニメ風の外観を目指すプロジェクトに最適です。
- Lineart realistic:線画でよりリアルな表現を捉えることを目的とし、リアリズムを必要とするプロジェクトのためにより多くのディテールを提供します。
- Lineart coarse:視覚的なインパクトを与えるためにより大胆で目立つラインを強調し、大胆なグラフィックステートメントに理想的です。
利用可能なプリプロセッサは、詳細な線画またはより目立つ線画を生成できます(LineartとLineart_Coarse)。
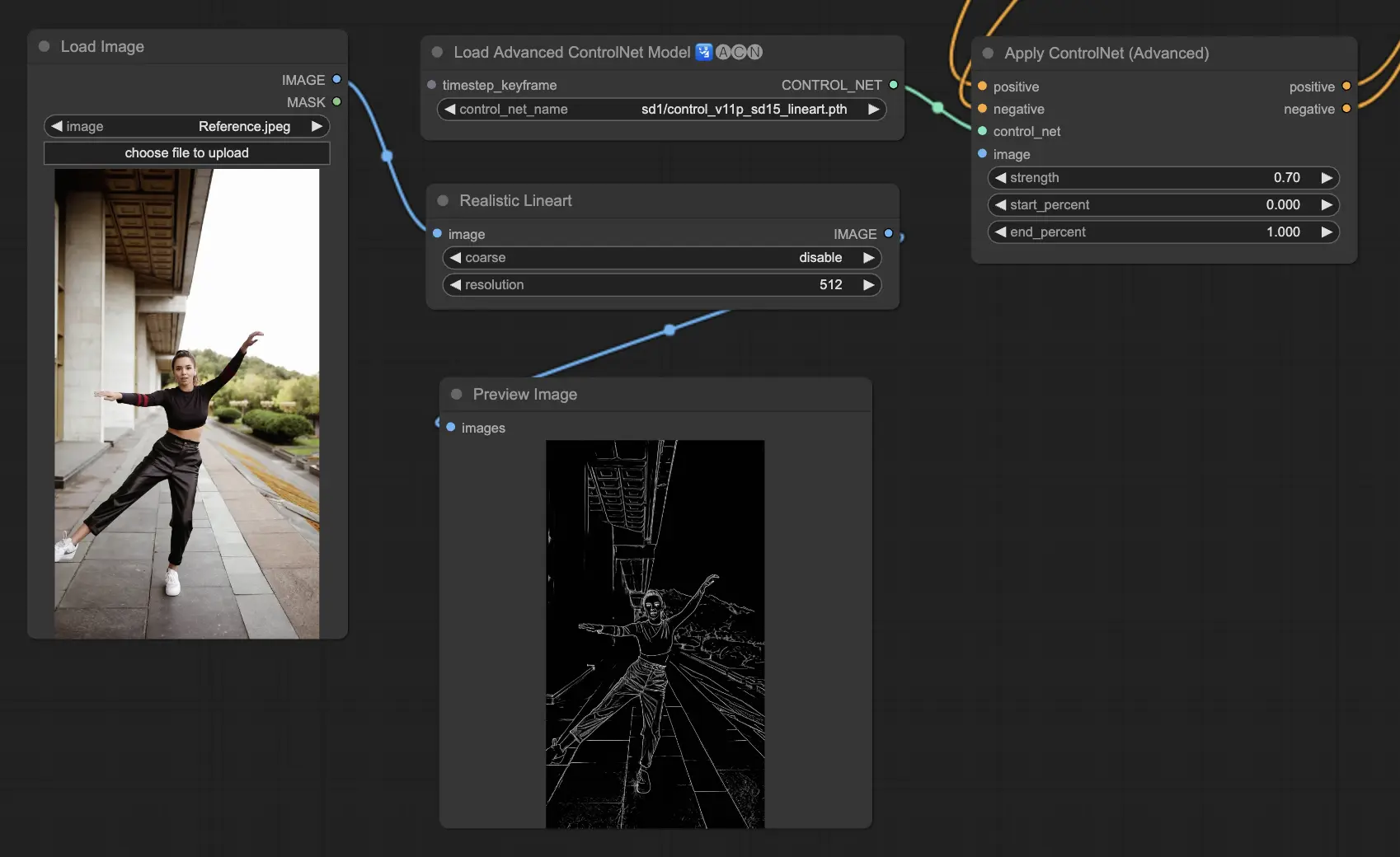
3.5.6. ControlNetモデル:Tile
Tile Resampleモデルは、画像の詳細を引き出すのに優れています。特にアップスケーラーと組み合わせて画像の解像度と詳細を高める際に効果的で、多くの場合、画像のテクスチャと要素を鮮明にし、豊かにするために適用されます。
推奨プリプロセッサ:Tile
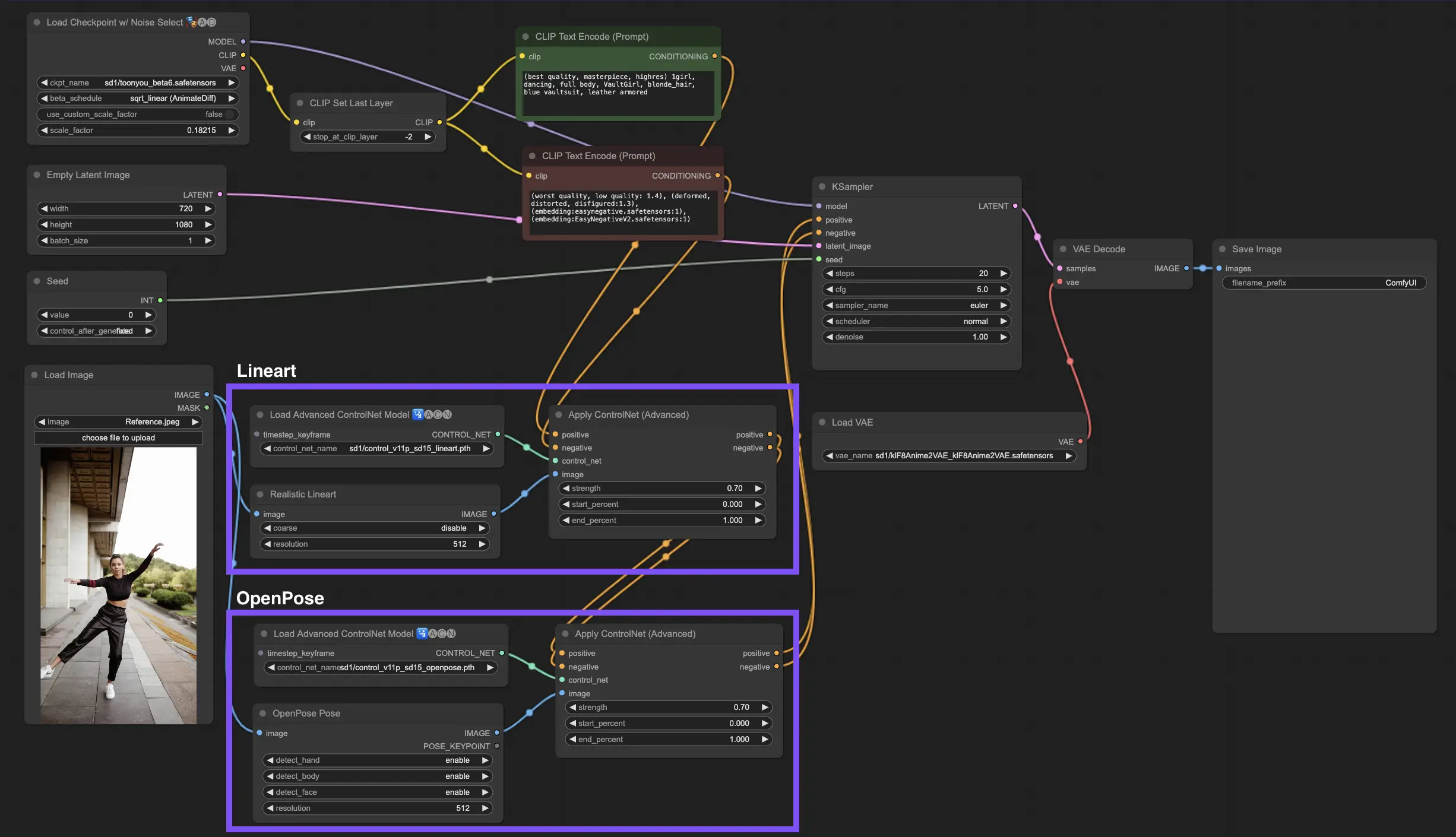
3.6. 複数のControlNetを使用するためのガイド#
複数のControlNetまたはT2I-Adapterを組み込むことで、画像生成プロセスに異なるタイプのコンディショニングを順次適用できます。例えば、LineartとOpenPose ControlNetを組み合わせて、詳細を強化できます。
オブジェクトの形状のためのLineart:最初にLineart ControlNetを統合して、画像内のオブジェクトや要素に深度と詳細を追加します。このプロセスには、含めたいオブジェクトのラインアートまたはキャニーマップの準備が含まれます。
ポーズ制御のためのOpenPose:ラインアートのディテールに続いて、OpenPose ControlNetを利用して、画像内の個人のポーズを指示します。希望のポーズを捉えたOpenPoseマップを生成または取得する必要があります。
順次適用:これらの効果を効果的に組み合わせるには、Lineart ControlNetからの出力をOpenPose ControlNetにリンクします。この方法により、被写体のポーズとオブジェクトの形状の両方が生成プロセス中に同時に誘導され、すべての入力仕様に調和して整合する結果が生成されます。
4. IPAdapterの概要#
ComfyUIでIPAdapterを使用する方法の詳細をご確認ください。
