
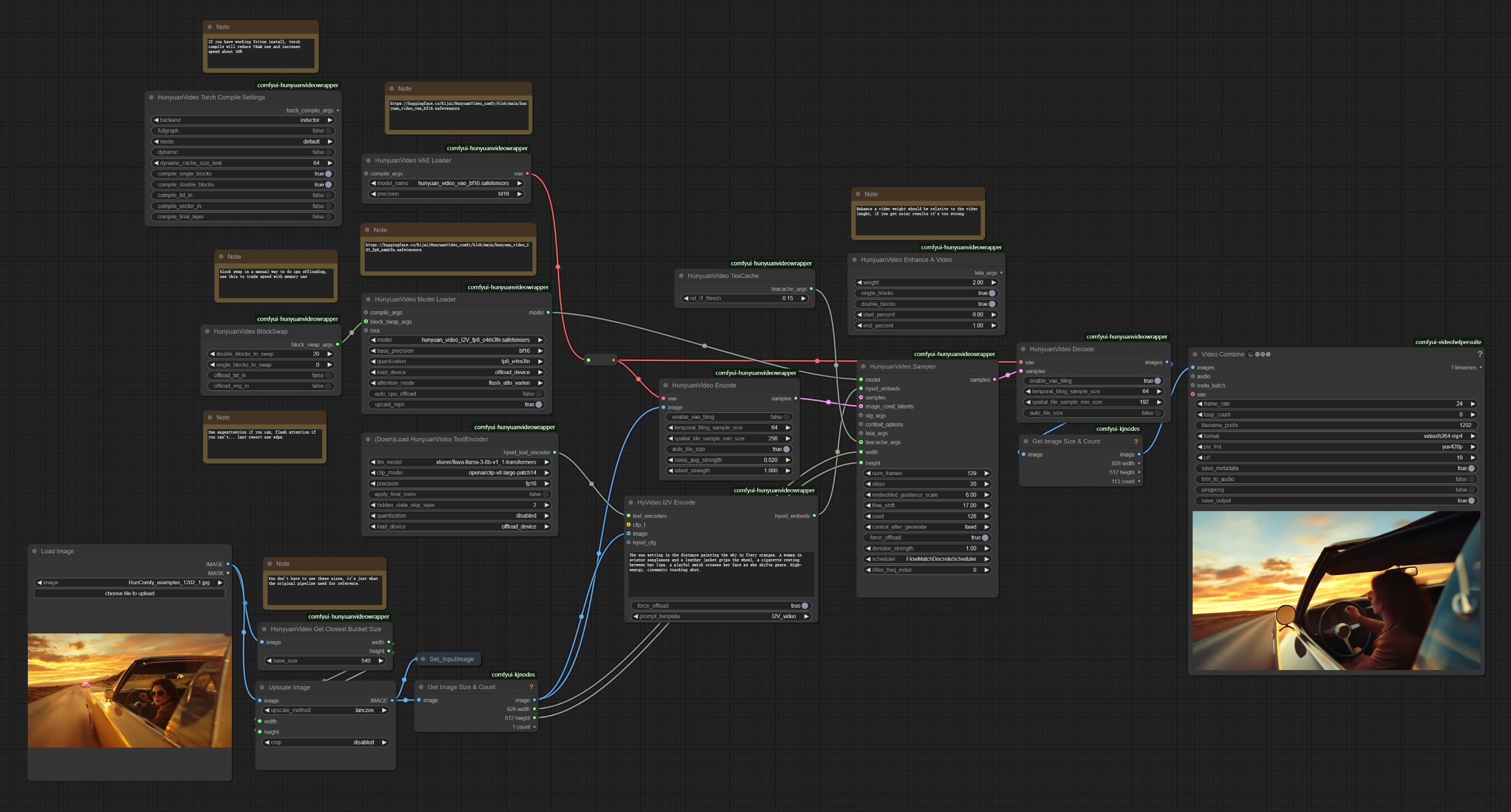
ComfyUI Hunyuan Image-to-Videoワークフローの説明#
1. Hunyuan Image-to-Videoワークフローとは?#
Hunyuan Image-to-Videoワークフローは、静止画像を自然な動きで高品質なビデオに変換するために設計された強力なパイプラインです。Tencentによって開発されたこの最先端技術は、最大720pの解像度でスムーズな24fps再生の映画のようなアニメーションを作成することを可能にします。潜在画像の連結とマルチモーダル大規模言語モデルを活用して、Hunyuan Image-to-Videoは画像コンテンツを解釈し、テキストプロンプトに基づいて一貫した動きパターンを適用します。
2. Hunyuan Image-to-Videoの利点:#
- 高解像度出力 - 最大720pで24fpsのビデオを生成
- 自然な動きの生成 - 静的画像から流れるようなリアルなアニメーションを作成
- テキストによるアニメーション - テキストプロンプトを使用して動きや視覚効果をガイド
- 映画のような品質 - 高忠実度のプロフェッショナルグレードのビデオを生成
- カスタマイズ可能な効果 - 髪の成長、表情、スタイルの調整など、LoRAトレーニングによる効果をサポート
- 最適化されたメモリ使用 - FP8ウェイトを利用してリソース管理を向上
3. Hunyuan Image-to-Videoワークフローの使用方法#
3.1 Hunyuan Image-to-Videoによる生成方法#
ワークフロー例:#
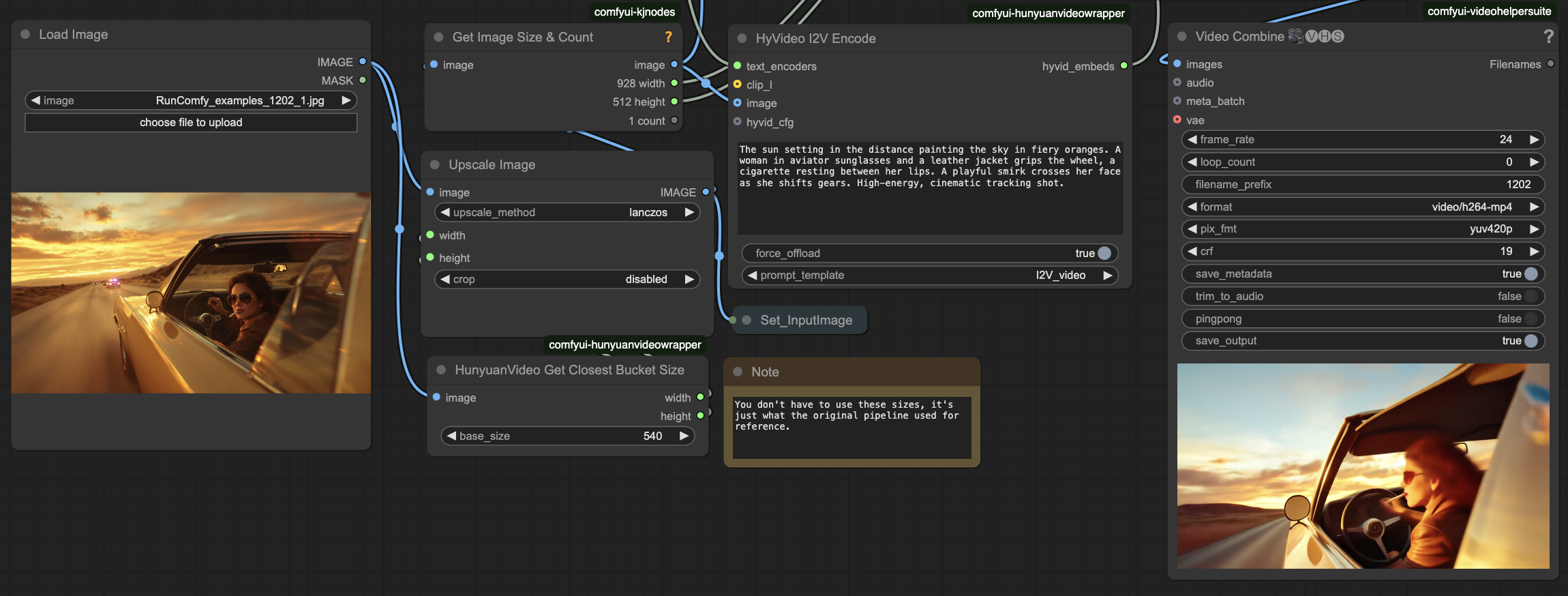
- 入力の準備
- Load Imageでソース画像をアップロード
- 動きの説明を入力
- HyVideo I2V Encodeで希望する動きの説明的なテキストプロンプトを入力
- 精緻化(オプション)
- HunyuanVideo Samplerで
framesを調整してビデオの長さを制御(デフォルト:129フレーム ≈ 5秒) - HunyuanVideo TeaCacheで
cache_factorを変更してメモリ使用を最適化 - HunyuanVideo Enhance A Videoで時間的一貫性とちらつきの削減を有効化
- HunyuanVideo Samplerで
- 出力
- Video Combineでプレビューを確認し、ComfyUI > Outputフォルダに保存された結果を見つける
3.2 Hunyuan Image-to-Videoのパラメータリファレンス#
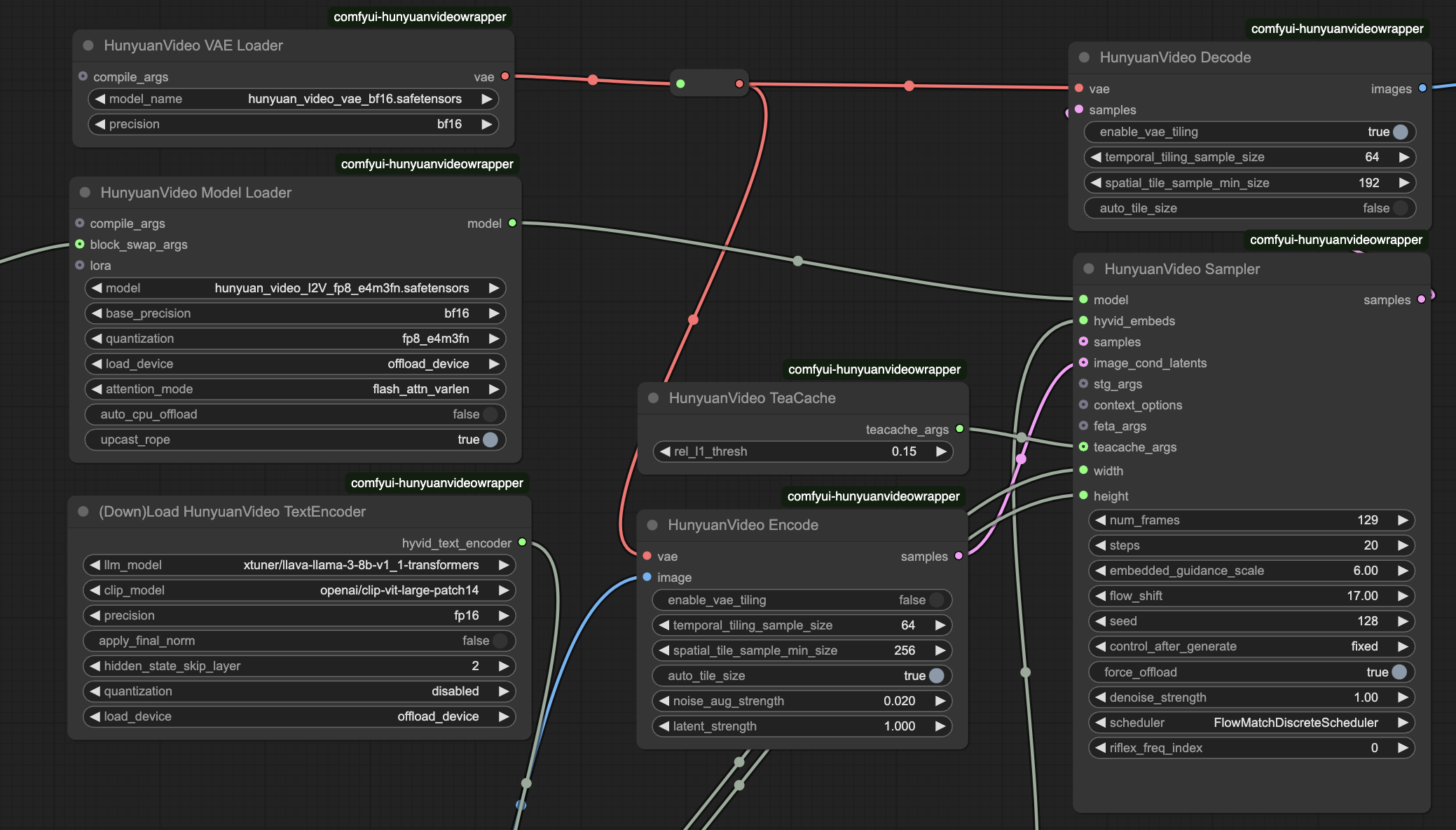
- HunyuanVideo Model Loader
model_name: hunyuan_video_I2V_fp8_e4m3fn.safetensors - 画像からビデオへの変換のためのコアモデルweight_precision: bf16 - モデルウェイトの精度レベルを定義scale_weights: fp8_e4m3fn - メモリ使用を最適化attention_implementation: flash_attn_varlen - 注意処理効率を制御
- HunyuanVideo Sampler
frames: 129 - フレーム数(24fpsで5.4秒)steps: 20 - サンプリングステップ(高い値は品質を向上)cfg: 6 - プロンプトの遵守強度を制御seed: varies - 生成の一貫性を確保
- HyVideo I2V Encode
prompt: [text field] - 動きとスタイルの説明的なプロンプトadd_prepend: true - 自動テキストフォーマットを有効にする
3.3 Hunyuan Image-to-Videoによる高度な最適化#
- メモリ最適化
- HunyuanVideo BlockSwap: VRAM効率のためのCPUオフロード
- HunyuanVideo TeaCache: メモリ対速度のバランスをとるキャッシュ動作を制御
- scale_weights: メモリ削減のためのFP8ウェイト(
e4m3fn format)
- 速度最適化
- HunyuanVideo Torch Compile Settings: 処理速度を向上させるためにTorchコンパイルを有効化
- attention_implementation: パフォーマンス向上のための効率的な注意メカニズムを選択
- offload_device: GPU/CPUメモリ管理を設定
詳細情報#
Hunyuan Image-to-Videoワークフローの詳細については、Tencent's HunyuanVideo-I2V repositoryをご覧ください。
謝辞#
このワークフローは、Tencentによって開発されたHunyuan Image-to-Videoによって提供されています。ComfyUIの統合には、Kijaiによって作成されたラッパーノードが含まれており、コンテキストウィンドウや直接画像埋め込みサポートなどの高度な機能を可能にしています。Hunyuan Image-to-Videoワークフローに対する貢献のすべてのクレジットは、オリジナルのクリエーターに帰属します!
