






フラックスコンテクストズームアウト LoRA | ComfyUIワークフロー#
このComfyUIワークフローは、キャンバスを拡張し、被写体の位置と外観を維持しながらシーンを自然に継続することで、入力画像のクリーンなズームアウトビューを作成します。これはフラックスコンテクストと目的に特化したLoRAを中心に構築されており、顔、テクスチャ、視点を歪めることなく「カメラを引く」ことができます。サムネイル、製品写真、ポートレート、シネマティックなスチルのフレーミングを拡大するための迅速で信頼性のある方法を求める場合、このフラックスコンテクストズームアウトLoRAワークフローが最適です。
その核心では、グラフがフラックスコンテクストUNetをロードし、フラックスコンテクストズームアウトLoRAを適用し、画像を参照潜在変数にエンコードし、ズームアウトの整合性のために明示的に設計されたプロンプトでガイドされた広い構図をサンプリングします。結果は、オリジナルのライティング、スタイル、幾何学にマッチしたシームレスな拡張です。
ComfyuiフラックスコンテクストズームアウトLoRAワークフローの主要モデル#
- フラックス1コンテクストUNet。ここで使用される拡散バックボーンは、ComfyUI用に準備されたコンテクスト対応フラックス1バリアントです (
flux1-dev-kontext_fp8_scaled.safetensors)。リアルなアウトペインティングに必要な長距離構造とシーンレイアウトをキャプチャします。モデルパック: Comfy-Org/flux1-kontext-dev_ComfyUI。 - フラックスコンテクストズームアウトLoRA。モデルが境界を説得力を持って拡張し、可視の被写体を変更せずに保つための軽量アダプタです。リポジトリ: reverentelusarca/flux-kontext-zoom-out-lora。
- フラックス用デュアルテキストエンコーダ。グラフは、プロンプトを高い忠実度で解釈するために、フラックス用に調整されたCLIP-LとT5-XXLエンコーダを使用します。テキストエンコーダ: comfyanonymous/flux_text_encoders。
- AE VAE。エンコード/デコードステップで使用される高速かつ高品質のオートエンコーダです (
ae.safetensors)。ソース: Comfy-Org/Lumina_Image_2.0_Repackaged。
ComfyuiフラックスコンテクストズームアウトLoRAワークフローの使用方法#
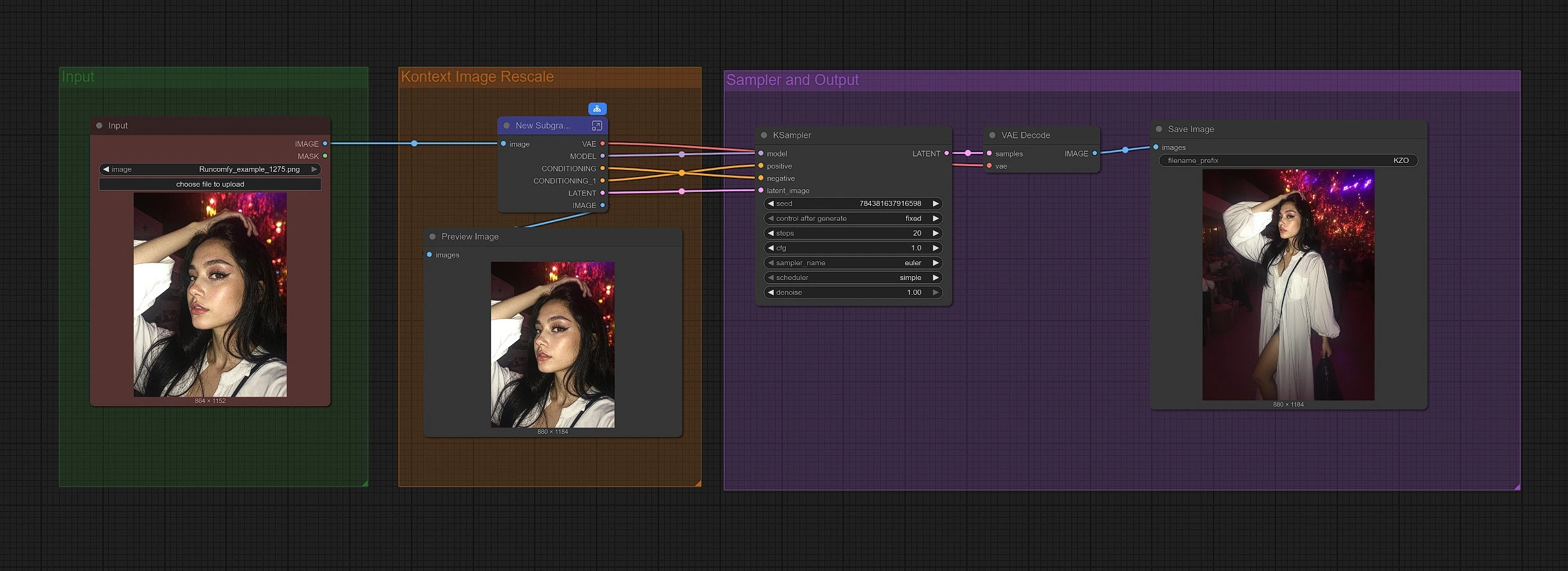
このワークフローは3つのグループに編成されています。最初に画像をロードし、次にグラフがコンテクストズームアウトのためにリスケールし、最後にサンプリングが広いフレームを再構築して結果を保存します。
グループ: 入力#
LoadImage (#190)でソース画像をロードします。CLIP Text Encode (Positive Prompt) (#6)のデフォルトのポジティブプロンプトは、被写体を維持し、キャンバスを均等に拡張するように作成されています。忠実なズームアウトのためにそのプロンプトをそのままにしておくか、シーンのスタイルに軽く調整することができます。DualCLIPLoader (#38)は、CLIP-LとT5-XXLで事前に配線されているため、テキスト条件付けがすぐに使用可能です。
グループ: コンテクスト画像リスケール#
FluxKontextImageScale (#42)は、コンテクストモデルが優雅に扱うように画像をリサイズしてパディングすることで、ズームアウトの準備をします。このステージングステップは、モデルがコンテンツを拡張する場所と視点とライティングを一貫して保つ方法を理解するのを助けます。スケーリングされた画像はVAEEncode (#124)によってエンコードされ、その後サンプラーが元のフレーミングを「記憶する」潜在変数から作業します。
グループ: サンプラーと出力#
モデルスタックはUNETLoader (#37)とLoraLoaderModelOnly (#191)によって組み立てられ、FluxコンテクストズームアウトLoRAがベースモデルに適用されます。ReferenceLatent (#177)は、構造的アンカーとしてエンコードされた画像を使用し、境界が拡大しても被写体が変更されないようにします。FluxGuidance (#35)は、参照が生成をどの程度強くガイドするかを形作ります。高い値は忠実度を高め、低い値は少し新しいフィルを許可します。KSampler (#31)が実際の拡散パスを実行し、VAEDecode (#8)、PreviewImage (#173)、SaveImage (#136)が最終的なズームアウト画像を表示および保存します。
ComfyuiフラックスコンテクストズームアウトLoRAワークフローの主要ノード#
FluxKontextImageScale (#42)#
コンテクスト対応のアウトペインティングのために入力をスケーリングおよびフレーミングして準備します。追加したいキャンバスの量を変更する唯一の場所として使用します。より多くの余裕が必要な場合は、スケールアウト量を増やし、エッジが新しすぎる場合は、それを減らして元のピクセルを多く保ちます。
LoraLoaderModelOnly (#191)#
kontext/zoomout-fal-v1.safetensorsをフラックス1コンテクストUNetにロードして適用します。出力が偏っている場合は、ここでLoRAの強度を調整してください。変更は控えめにして、ズームアウトLoRAの意図した動作を維持します。
ReferenceLatent (#177)#
VAEエンコードされたオリジナルをサンプラーに条件付けすることで、構図とアイデンティティをロックします。被写体のポーズやスケールに微妙なドリフトが見られる場合は、提供されたとおりにこのノードを経由して条件付けし、削除を避けてください。中立的または最小限のプロンプトとペアリングすると、忠実度が最大化されます。
FluxGuidance (#35)#
参照とプロンプトがサンプラーをどの程度ガイドするかを制御します。拡張された領域がライティングや視点と一致しない場合はガイダンスを上げ、もう少し創造的な背景フィルを望む場合は下げてください。厳密な保存と有機的な継続の間のバランスノブとして扱います。
オプションの追加#
- ポジティブプロンプトを最小限に保ちます。このフラックスコンテクストズームアウトLoRAに調整されたプロンプトは通常編集を必要としません。
- 境界に小さな継ぎ目が見られる場合は、
FluxKontextImageScaleでのスケールアウトを小さくするか、FluxGuidanceを少し高めにしてください。 - スタイリッシュなシーンの場合、トーンや媒体を説明する単語を1〜2語追加し、メインフィギュアを変更しないようにしてください。
- シードのみを変更して反復的なバリアントを保存します。これにより、構図を変更せずに最もクリーンな継続を選ぶことができます。
謝辞#
このワークフローは、以下の作品とリソースを実装および構築しています。reverentelusarca による フラックスコンテクストズームアウトLoRA の貢献とメンテナンスに感謝します。詳しい情報については、以下にリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- reverentelusarca/フラックスコンテクストズームアウトLoRA
- Hugging Face: フラックスコンテクストズームアウトLoRA
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者および管理者によって提供されたライセンスおよび条件の対象となります。

