
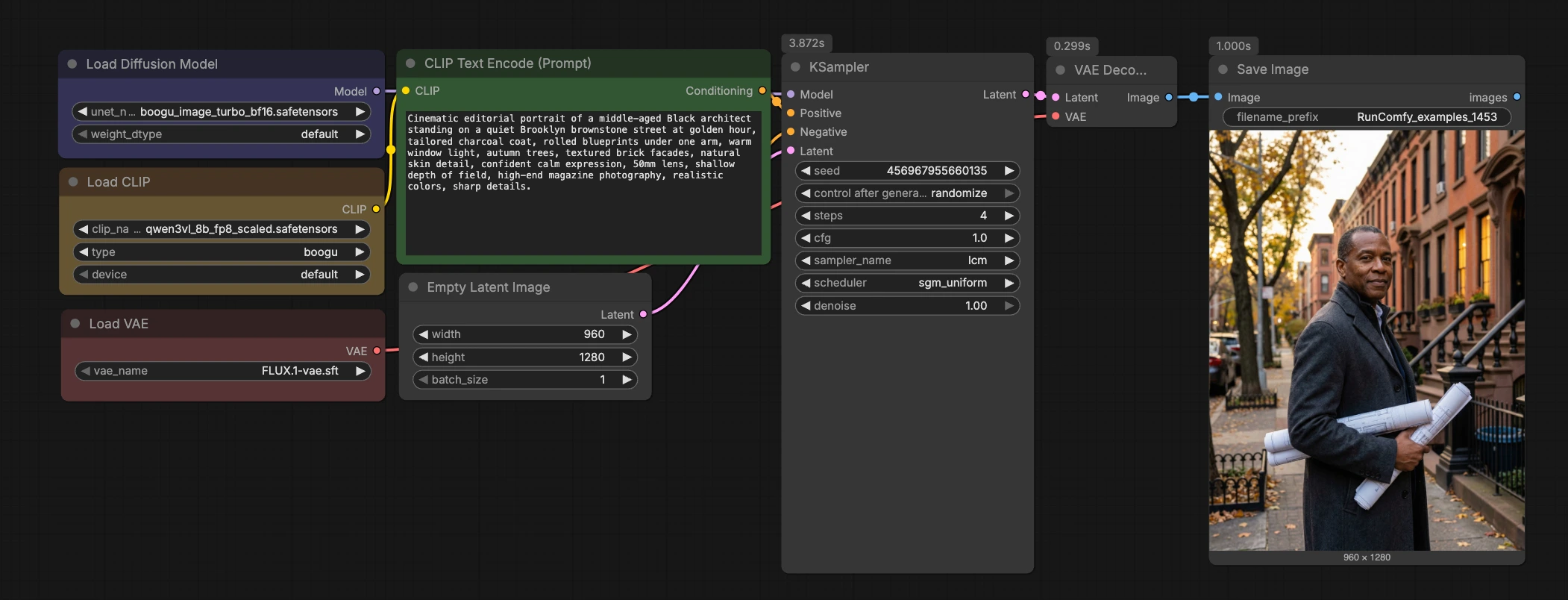






Boogu Turbo text-to-image ComfyUI ワークフロー#
この Boogu Turbo text-to-image ComfyUI ワークフローは、プロンプトから画像へのクリーンで高速なパスを提供し、Boogu-Image-0.1-Turbo チェックポイントと4ステップの LCM サンプリングを使用します。Qwen3-VL テキストエンコーダと FLUX.1 VAE を組み合わせて、グラフを最小限に保ちながら迅速に反復できます。
急速なビジュアル探索のために設計されたワークフローは、映画的な環境、アニメスタイルの背景、雰囲気のある風景、創造的な製品マシン、建築シーンで優れています。RunComfy-ready で簡単に検査できる軽量な Boogu Turbo text-to-image ComfyUI ワークフローをお探しの場合、このテンプレートは強力なスタートポイントです。
Comfyui Boogu Turbo text-to-image ComfyUI ワークフローの主要モデル#
- Boogu-Image-0.1-Turbo。蒸留された Turbo バリアントは、典型的な3〜4ステップの推論とガイダンススケールが1.0に近い、迅速でフォトリアリスティックな text-to-image のために構築されています。公式モデルの重みと指示は Hugging Face で利用可能で、Comfy-Org によって提供される ComfyUI-ready 再パッケージファイルがあります。Boogu/Boogu-Image-0.1-Turbo-fp8 と Comfy-Org/Boogu-Image のキュレーションされた ComfyUI パックを参照してください。
- Qwen3-VL 8B テキストエンコーダ。ここでは、ディフュージョンモデルの強力なプロンプト埋め込みを生成するためのテキストエンコーダとして純粋に使用されます。ComfyUI にパッケージされたエンコーダは Comfy-Org/Qwen3-VL にホストされており、公式リポジトリは QwenLM/Qwen3-VL です。
- FLUX.1 VAE。Black Forest Labs からのオートエンコーダは、ピクセルと潜在空間の間で画像をエンコードおよびデコードし、色とコントラストの忠実性を保持するのに役立ちます。参照ウェイトとドキュメントは black-forest-labs/FLUX.1-dev にあります。
Comfyui Boogu Turbo text-to-image ComfyUI ワークフローの使用方法#
一目で、ワークフローはプロンプトをエンコードし、潜在キャンバスを初期化し、Boogu-Image-0.1-Turbo を介して高速 LCM サンプラーを実行し、FLUX.1 VAE でデコードし、結果を保存します。グラフは意図的にコンパクトで、他のプロジェクトに簡単に組み込んだり、LoRAs、ControlNets、またはポストプロセッシングチェーンで拡張したりできます。
Qwen3-VL によるプロンプトエンコーディング (CLIPLoader (#7) → CLIPTextEncode (#11))#
このステージでは、Qwen3-VL エンコーダをロードし、テキストプロンプトをコンディショニングベクトルに変換します。CLIPTextEncode (#11) に自然言語でプロンプトを入力します。レンズ、ライティング、時間帯、テクスチャなどの詳細な写真のヒントが効果的です。ネガティブ入力は ConditioningZeroOut (#9) によって意図的にゼロにされており、Turbo の低ガイダンス体制で結果を安定させます。明確なネガティブを好む場合は、ConditioningZeroOut を削除し、2番目の CLIPTextEncode を使用してネガティブプロンプトを提供します。ここでの良いプロンプトの衛生管理は、高い CFG や追加ステップの必要性を減らします。
潜在セットアップとモデルのロード (EmptyLatentImage (#8) + UNETLoader (#2))#
EmptyLatentImage (#8) は潜在キャンバスを作成します。デフォルトの960×1280の縦長アスペクトは、人、インテリア、高さのある製品ショットのためのバランスの取れたスタートポイントです。正方形またはワイドのサイズを設定することもできます。UNETLoader (#2) は、Comfy-Org パックから Boogu Turbo ディフュージョンの重みをロードし、選択したエンコーダと VAE にモデルを合わせます。VRAM とスループットのバランスを取る必要がある場合、BF16 と FP8 バリアントの交換は簡単です。プロジェクト全体でモデル選択を一貫させて、スタイルの連続性を維持してください。
高速 LCM サンプリング (KSampler (#32) with sampler lcm)#
KSampler は、Latent Consistency Models を用いて約4ステップで高品質を達成するように構成されています。LCM 蒸留は非常に低いガイダンス値をターゲットにしているため、この Boogu Turbo text-to-image ComfyUI ワークフローは、CFG が1.0に近い状態で安定して動作し、プロンプトの順守を維持します。微細なディテールをもう少し追加したい場合は、ステップをわずかに増やし、A/B 比較のためにシードを固定します。スタイルや構成の変更には、シードを再ロールし、ステップを過度に高くするのではなくプロンプトを調整します。LCM の数ステップ推論に関する背景理論は、オリジナルの論文 Latent Consistency Models に記載されています。
デコードと保存 (VAELoader (#5) → VAEDecode (#3) → SaveImage (#58))#
VAELoader (#5) にロードされた FLUX.1 VAE は、VAEDecode (#3) において潜在を RGB にデコードします。VAE ファミリーをディフュージョンバックボーンに一致させることは、より忠実な色とテクスチャを生成する傾向があるため、このグラフには FLUX.1 VAE が付属しています。SaveImage (#58) は、結果をディスクに保存します。出力プレフィックスを変更して、プロンプト、シード、またはアスペクト比で実験を整理します。後でアップスケーラーやポストエフェクトをチェーン化する場合、VAEDecode の Image 出力から分岐して、クリーンな履歴を保持します。
Comfyui Boogu Turbo text-to-image ComfyUI ワークフローの主要ノード#
CLIPTextEncode (#11)#
このノードには、主なテキストプロンプトが格納されており、サンプラーによって使用されるポジティブなコンディショニングを生成します。プロンプトは簡潔に保ち、カメラの焦点距離、時間帯、素材の形容詞などのシーンクエを追加します。ネガティブプロンプトを使用したい場合は、2番目の CLIPTextEncode を作成し、サンプラーのネガティブ入力に接続し、ConditioningZeroOut (#9) を削除します。
ConditioningZeroOut (#9)#
このノードは、ゼロベクトルをサンプラーのネガティブポートに供給することでネガティブコンディショニングを無効にします。Turbo の低ガイダンス構成では、これをそのままにしておくのが良いデフォルトです。ネガティブプロンプトが必要で、それを明確に表現できる場合にのみ削除します。
EmptyLatentImage (#8)#
出力寸法とバッチサイズを制御します。ポートレートには960×1280、広い環境には1280×960を開始点として使用します。被写体とメモリ予算に基づいて調整します。より大きな潜在画像は、詳細なキャンバスを提供しますが、VRAM 使用量とデコード時間が増加します。
UNETLoader (#2)#
生成に使用する Boogu-Image-0.1-Turbo チェックポイントを選択します。高性能な GPU で最高の忠実度を得るために BF16 バリアントを使用するか、VRAM を削減し高速な読み込みを実現するために FP8 バリアントを使用します。Comfy-Org パッケージで利用可能です。モデルファイルとそのフォルダのドキュメントは Comfy-Org/Boogu-Image にあります。
KSampler (#32)#
lcm サンプラーを使用してディフュージョンプロセスを実行し、数ステップの推論を行います。主要なレバーはシード、ステップ数、CFG です。Turbo は非常に低いガイダンスで少ないステップで動作するように設計されており、品質を維持します。公式の Turbo 設定は、Boogu/Boogu-Image-0.1-Turbo-fp8 のモデルカードに反映されています。制御された探索には、シードを固定し、ステップやプロンプトの言い回しを一度に一つずつ変更します。
VAELoader (#5) および VAEDecode (#3)#
FLUX.1 VAE をロードして適用します。FLUX.1 ファミリーを使用することで、UNet のトレーニング設定と一致した色、コントラスト、テクスチャの動作が一貫します。VAE のミックスは可能ですが、色調や彩度が微妙に変わる可能性があるため、新しいルックにコミットする前にテストしてください。参照ウェイト: black-forest-labs/FLUX.1-dev。
SaveImage (#58)#
出力の命名と保存先を制御します。プロジェクト名、アスペクトタグ、またはシードなどの意味のあるプレフィックスを使用して、実行を整理します。パイプラインを拡張する際には、ここから分岐してアップスケーラー、色補正、キャプショナーを追加し、ベースの保存を妨げることなく行います。
オプションの追加#
- 最速の反復のために CFG を1.0に近く、ステップを約4に保ちます。少しのテクスチャや安定性が必要な場合のみ6〜8ステップに移行します。
- 構成を探るためにシードを再ロールし、スタイルと微細なディテールを調整するためにシードを固定します。
- 高メモリの GPU で最高の品質を得るために BF16 ウェイトを使用し、読み込みを高速化し VRAM を削減するために FP8 に切り替えます。
- 画像内のテキストの可読性を向上させるために、わずかに高い解像度を試し、プロンプトに明示的なタイポグラフィキューを含めます。
- この Boogu Turbo text-to-image ComfyUI ワークフローでは、小さなプロンプトの微調整で数秒で意味のある異なるシーンを生成できるため、途中のお気に入りを頻繁に保存します。
謝辞#
このワークフローは、以下の作品とリソースを実装および構築しています。ワークフロー参照のための RunningHub、Boogu-Image リポジトリと Boogu-Image-0.1-Turbo モデルのための Boogu、Boogu ComfyUI 重みのための Comfy-Org、Boogu チュートリアルのための ComfyUI の貢献とメンテナンスに心から感謝します。権威ある詳細については、以下にリンクされたオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- RunningHub/Workflow reference
- Docs / Release Notes: RunningHub post
- Boogu/Project site
- Docs / Release Notes: boogu.org
- Boogu/Boogu Image repository
- GitHub: boogu-project/Boogu-Image
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- Boogu/Boogu-Image-0.1-Turbo model
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- GitHub: boogu-project/Boogu-Image
- Comfy-Org/Boogu ComfyUI weights
- Hugging Face: Comfy-Org/Boogu-Image
- ComfyUI/Boogu tutorial
- Docs / Release Notes: ComfyUI tutorial
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者および管理者によって提供されたライセンスおよび条件に従います。



