
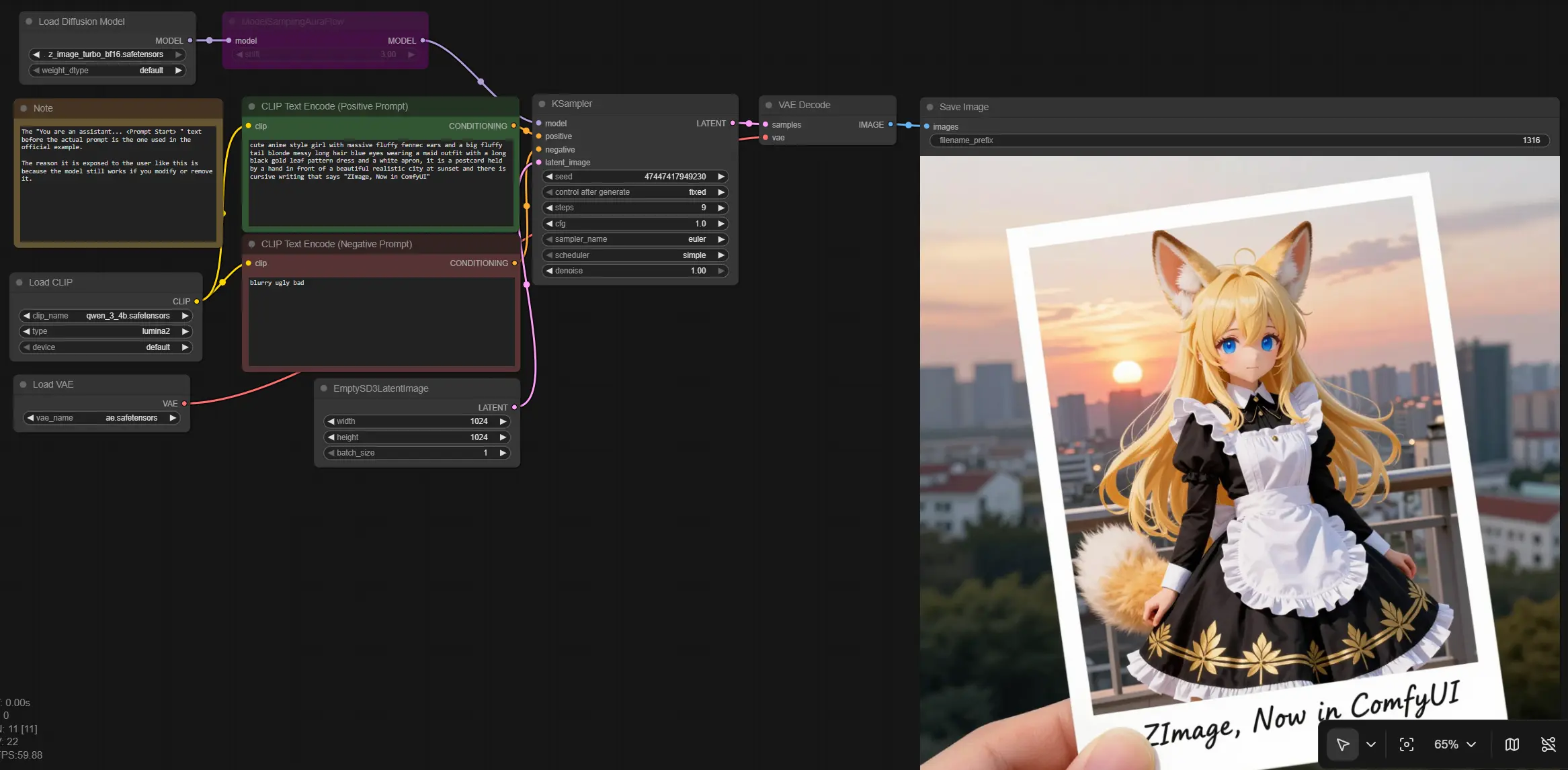







Z Image Turbo per ComfyUI: testo veloce in immagine con iterazione quasi in tempo reale#
Questo workflow porta Z Image Turbo in ComfyUI così puoi generare immagini ad alta risoluzione, fotorealistiche con pochissimi passaggi e stretta aderenza al prompt. È progettato per i creatori che necessitano di rendering rapidi e coerenti per concept art, composizioni pubblicitarie, media interattivi e test rapidi A/B.
Il grafico segue un percorso pulito dai prompt di testo a un'immagine: carica il modello Z Image e i componenti di supporto, codifica i prompt positivi e negativi, crea una tela latente, campiona con un programma AuraFlow, quindi decodifica in RGB per il salvataggio. Il risultato è una pipeline Z Image snella che privilegia la velocità senza sacrificare i dettagli.
Modelli chiave nel workflow Z Image di ComfyUI#
- Tongyi-MAI Z Image Turbo. Il generatore principale che esegue la denoising in modo distillato ed efficiente in termini di passaggi. Mira al fotorealismo, a texture nitide e a una composizione fedele mantenendo bassa la latenza. Model card
- Qwen 4B text encoder (qwen_3_4b.safetensors). Fornisce il condizionamento linguistico per il modello in modo che stile, soggetto e composizione nel tuo prompt guidino la traiettoria di denoising.
- Autoencoder AE (ae.safetensors). Traduce tra lo spazio latente e i pixel in modo che il risultato finale di Z Image possa essere visualizzato ed esportato.
Come usare il workflow Z Image di ComfyUI#
A un livello alto, il percorso va dal prompt al condizionamento, attraverso il campionamento Z Image, quindi decodificando in un'immagine. I nodi sono raggruppati in fasi per mantenere l'operazione semplice.
Caricatori di modelli: UNETLoader (#16), CLIPLoader (#18), VAELoader (#17)#
Questa fase carica il checkpoint principale Z Image Turbo, il codificatore di testo e l'autoencoder. Scegli il checkpoint BF16 se lo hai, poiché bilancia velocità e qualità per GPU consumer. Il codificatore di stile CLIP assicura che le tue parole controllino la scena e lo stile. L'AE è necessario per convertire i latenti in RGB una volta terminato il campionamento.
Prompting: CLIP Text Encode (Positive Prompt) (#6) e CLIP Text Encode (Negative Prompt) (#7)#
Scrivi ciò che desideri nel prompt positivo usando nomi concreti, suggerimenti di stile, accenni di fotocamera e illuminazione. Usa il prompt negativo per sopprimere artefatti comuni come sfocatura o oggetti indesiderati. Se vedi un'intestazione di prompt come un'intestazione di istruzioni da un esempio ufficiale, puoi mantenerla, modificarla o rimuoverla e il workflow funzionerà comunque. Insieme, questi codificatori producono il condizionamento che guida Z Image durante il campionamento.
Latente e scheduler: EmptySD3LatentImage (#13) e ModelSamplingAuraFlow (#11)#
Scegli la tua dimensione di output impostando la tela latente. Il nodo scheduler passa il modello a una strategia di campionamento in stile AuraFlow che si allinea bene con modelli distillati efficienti in termini di passaggi. Ciò mantiene stabili le traiettorie a bassi conteggi di passaggi preservando i dettagli fini. Una volta impostati la tela e il programma, la pipeline è pronta per il denoising.
Campionamento: KSampler (#3)#
Questo nodo esegue il vero denoising utilizzando il modello Z Image caricato, lo scheduler selezionato e il tuo condizionamento del prompt. Regola il tipo di campionatore e il conteggio dei passaggi per scambiare velocità con dettagli quando necessario. La scala di guida controlla la forza del prompt rispetto al precedente; i valori moderati di solito danno il miglior equilibrio tra fedeltà e variazione creativa. Randomizza il seed per l'esplorazione o fissalo per risultati ripetibili.
Decodifica e salvataggio: VAEDecode (#8) e SaveImage (#9)#
Dopo il campionamento, l'AE decodifica i latenti in un'immagine. Il nodo di salvataggio scrive i file nella tua directory di output in modo da poter confrontare le iterazioni o alimentare i risultati in attività a valle. Se prevedi di ingrandire o post-elaborare, mantieni la decodifica alla risoluzione di lavoro desiderata ed esporta formati lossless per la migliore ritenzione della qualità.
Nodi chiave nel workflow Z Image di ComfyUI#
UNETLoader (#16)#
Carica il checkpoint Z Image Turbo (z_image_turbo_bf16.safetensors). Usa questo per passare tra varianti di precisione o pesi aggiornati man mano che diventano disponibili. Mantieni il modello coerente durante una sessione se desideri che i seed e i prompt rimangano confrontabili. Cambiare il modello di base cambierà aspetto, risposta del colore e densità del dettaglio.
ModelSamplingAuraFlow (#11)#
Imposta la strategia di campionamento su un programma in stile AuraFlow adatto alla rapida convergenza. Questo è il segreto per rendere Z Image efficiente a bassi conteggi di passaggi preservando dettagli e coerenza. Se cambi programmi successivamente, ricontrolla conteggi di passaggi e guida per mantenere caratteristiche di output simili.
KSampler (#3)#
Controlla algoritmo del campionatore, passaggi, guida e seed. Usa meno passaggi per una rapida ideazione e aumenta solo quando hai bisogno di più micro-dettagli o di un'aderenza più rigorosa al prompt. Diversi campionatori favoriscono diversi aspetti; prova un paio e mantieni il resto della pipeline fisso quando confronti i risultati.
CLIP Text Encode (Positive Prompt) (#6)#
Codifica l'intento creativo che guida Z Image. Concentrati su soggetto, medium, lente, illuminazione, composizione e qualsiasi vincolo di marchio o design. Abbinalo al nodo del prompt negativo per spingere l'immagine verso l'aspetto desiderato mentre filtri artefatti noti.
Extra opzionali#
- Usa risoluzioni quadrate o quasi quadrate per il primo passaggio, quindi regola il rapporto d'aspetto una volta bloccata la composizione.
- Mantieni una libreria di frammenti di prompt riutilizzabili per soggetti, lenti e illuminazione per velocizzare l'iterazione tra i progetti.
- Per una direzione artistica coerente, fissa il seed e varia solo un singolo fattore per iterazione come il tag di stile o il suggerimento della fotocamera.
- Se gli output sembrano troppo controllati, riduci leggermente la guida o rimuovi frasi troppo prescrittive dal prompt positivo.
- Quando prepari asset per l'editing a valle, esporta PNG lossless e mantieni un record di prompt, seed e risoluzione insieme a ciascun rendering Z Image.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo Tongyi-MAI per Z-Image-Turbo per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Tongyi-MAI/Z-Image-Turbo
- Hugging Face: Tongyi-MAI/Z-Image-Turbo
Nota: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e ai termini forniti dai loro autori e manutentori.
