
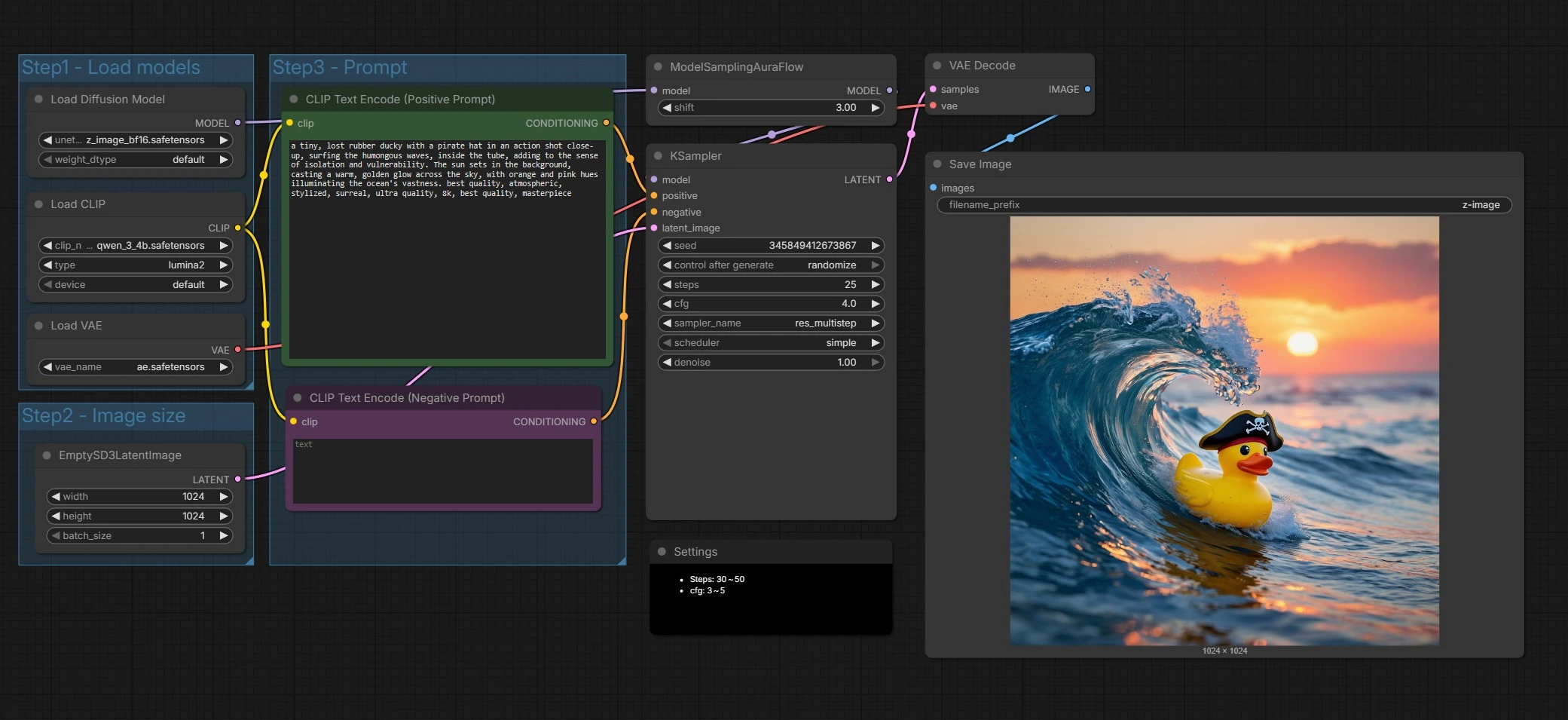
















Flusso di lavoro da testo a immagine Z-Image per ComfyUI#
Questo flusso di lavoro ComfyUI mostra Z-Image, un trasformatore di diffusione di nuova generazione progettato per una generazione di immagini veloce e ad alta fedeltà. Costruito su un'architettura a flusso singolo scalabile con circa 6 miliardi di parametri, Z-Image bilancia fotorealismo, forte aderenza al prompt e rendering del testo bilingue.
Pronto all'uso, il grafico è impostato per Z-Image Base per massimizzare la qualità rimanendo efficiente su GPU comuni. Funziona bene anche con la variante Z-Image Turbo quando la velocità è importante, e la sua struttura lo rende facile da estendere verso Z-Image Edit per compiti da immagine a immagine. Se vuoi un grafico affidabile e minimale che trasformi prompt chiari in risultati puliti, questo flusso di lavoro Z-Image è un solido punto di partenza.
Modelli chiave nel flusso di lavoro Z-Image di ComfyUI#
- Trasformatore di diffusione Z-Image Base (bf16). Generatore principale che denoisa i latenti in immagini con la topologia a flusso singolo di Z-Image e controllo del prompt. Model page • bf16 weights
- Codificatore di testo Qwen 3 4B. Codifica i prompt per Z-Image con una forte copertura bilingue e una chiara tokenizzazione per il rendering del testo. encoder weights
- Autoencoder VAE di Z-Image. Comprime e ricostruisce le immagini tra lo spazio pixel e lo spazio latente di Z-Image. VAE weights
Come usare il flusso di lavoro Z-Image di ComfyUI#
A un livello alto, il grafico carica i componenti di Z-Image, prepara una tela latente, codifica i tuoi prompt positivi e negativi, esegue un campionatore ottimizzato per Z-Image, quindi decodifica e salva il risultato. Principalmente fornisci il prompt e scegli la dimensione dell'output; il resto è configurato per impostazioni predefinite sensibili.
Passo 1 - Carica modelli#
Questo gruppo inizializza Z-Image UNet, il codificatore di testo Qwen 3 4B e il VAE in modo che tutti i componenti siano allineati. Il UNETLoader (#66) punta a Z-Image Base per impostazione predefinita, che favorisce fedeltà e margine di modifica. Il CLIPLoader (#62) porta il codificatore basato su Qwen che gestisce bene i prompt multilingue e i token di testo. Il VAELoader (#63) imposta l'autoencoder usato successivamente per la decodifica. Scambia i pesi qui se vuoi provare Z-Image Turbo per bozze più rapide.
Passo 2 - Dimensione immagine#
Questo gruppo imposta la tela latente tramite EmptySD3LatentImage (#68). Scegli la larghezza e l'altezza che vuoi generare, e tieni a mente il rapporto d'aspetto per la composizione. Z-Image funziona bene su dimensioni creative comuni, quindi scegli dimensioni che corrispondono ai tuoi storyboard o al formato di consegna. Dimensioni maggiori aumentano il dettaglio e il costo di calcolo.
Passo 3 - Prompt#
Qui scrivi la tua storia. Il nodo CLIP Text Encode (Positive Prompt) (#67) prende la descrizione della scena e le direttive di stile per Z-Image. Il CLIP Text Encode (Negative Prompt) (#71) aiuta a evitare artefatti o elementi indesiderati. Z-Image è ottimizzato per il rendering del testo bilingue, quindi puoi includere contenuti testuali in più lingue direttamente nel prompt quando necessario. Mantieni i prompt specifici e visivi per risultati più coerenti.
Campionare e denoisare#
ModelSamplingAuraFlow (#70) applica una politica di campionamento allineata con il design a flusso singolo di Z-Image, quindi KSampler (#69) guida il processo di denoising per trasformare il rumore in un'immagine che corrisponde ai tuoi prompt. Il campionatore combina il tuo condizionamento positivo e negativo con la tela latente per affinare iterativamente struttura e dettagli. Puoi scambiare velocità per qualità qui regolando le impostazioni del campionatore come descritto di seguito. Questa fase è dove l'aderenza al prompt e la chiarezza del testo di Z-Image si manifestano davvero.
Decodificare e salvare#
VAEDecode (#65) converte il latente finale in un'immagine RGB. SaveImage (#9) scrive file usando il prefisso impostato nel nodo così i tuoi output di Z-Image sono facili da trovare e organizzare. Questo completa un passaggio completo dal prompt ai pixel.
Nodi chiave nel flusso di lavoro Z-Image di ComfyUI#
UNETLoader (#66)#
Carica il backbone di Z-Image che esegue il denoising effettivo. Scambia con un'altra variante di Z-Image qui quando esplori casi d'uso di velocità o modifica. Se cambi varianti, mantieni il codificatore e il VAE compatibili per evitare cambiamenti di colore o contrasto.
CLIP Text Encode (Positive Prompt) (#67)#
Codifica la descrizione principale per Z-Image. Scrivi frasi concise e visive che specificano soggetto, illuminazione, fotocamera, umore e qualsiasi testo sull'immagine. Per il rendering del testo, metti le parole desiderate tra virgolette e mantienile brevi per la migliore leggibilità.
CLIP Text Encode (Negative Prompt) (#71)#
Definisce cosa evitare affinché Z-Image possa concentrarsi sui dettagli giusti. Usalo per sopprimere sfocature, arti extra, tipografia disordinata o elementi fuori stile. Mantienilo breve e tematico in modo che non vincoli eccessivamente la composizione.
EmptySD3LatentImage (#68)#
Crea la tela latente su cui Z-Image dipingerà. Scegli dimensioni adatte all'uso finale e mantienile multipli di 64 px per un uso efficiente della memoria. Tele più larghe o più alte influenzano composizione e prospettiva, quindi regola i prompt di conseguenza.
ModelSamplingAuraFlow (#70)#
Seleziona un preset del campionatore che corrisponde all'addestramento e allo spazio latente di Z-Image. Raramente è necessario cambiare questo a meno che non si stiano testando campionatori alternativi. Lascialo come fornito per risultati stabili e privi di artefatti.
KSampler (#69)#
Controlla il compromesso qualità-velocità per Z-Image. Aumenta i steps per più dettaglio e stabilità, diminuisci per bozze più veloci. Mantieni cfg moderato per bilanciare l'aderenza al prompt con trame naturali; i valori tipici in questo grafico sono steps: 30 a 50 e cfg: 3 a 5. Imposta un seed fisso per la riproducibilità o randomizzalo per esplorare variazioni.
VAEDecode (#65)#
Trasforma il latente finale da Z-Image in un'immagine RGB. Se mai cambi il VAE, mantienilo abbinato alla famiglia di modelli per preservare l'accuratezza del colore e la nitidezza.
SaveImage (#9)#
Scrive il risultato con un chiaro prefisso del nome file in modo che gli output di Z-Image siano facili da catalogare. Regola il prefisso per separare esperimenti, varianti di modelli o rapporti d'aspetto.
Extra opzionali#
- Usa Z-Image Turbo per un'ideazione rapida, quindi passa a Z-Image Base e aumenta i passi per i rendering finali.
- Per prompt bilingui e testo sull'immagine, mantieni le parole brevi e ad alto contrasto nel prompt per aiutare Z-Image a rendere una tipografia nitida.
- Blocca il seed quando confronti piccole modifiche al prompt in modo che le differenze riflettano le tue modifiche piuttosto che un nuovo rumore.
- Se vedi sovrasaturazione o aloni, riduci leggermente
cfgo rafforza il prompt negativo per recuperare l'equilibrio.
Riconoscimenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo Comfy-Org per il modello di flusso di lavoro Z-Image Day-0 ComfyUI per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Comfy-Org/Z-Image Day-0 support in ComfyUI
- GitHub: Comfy-Org/workflow_templates
- Docs / Release Notes: Source
Nota: L'uso dei modelli, dei set di dati e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.
