
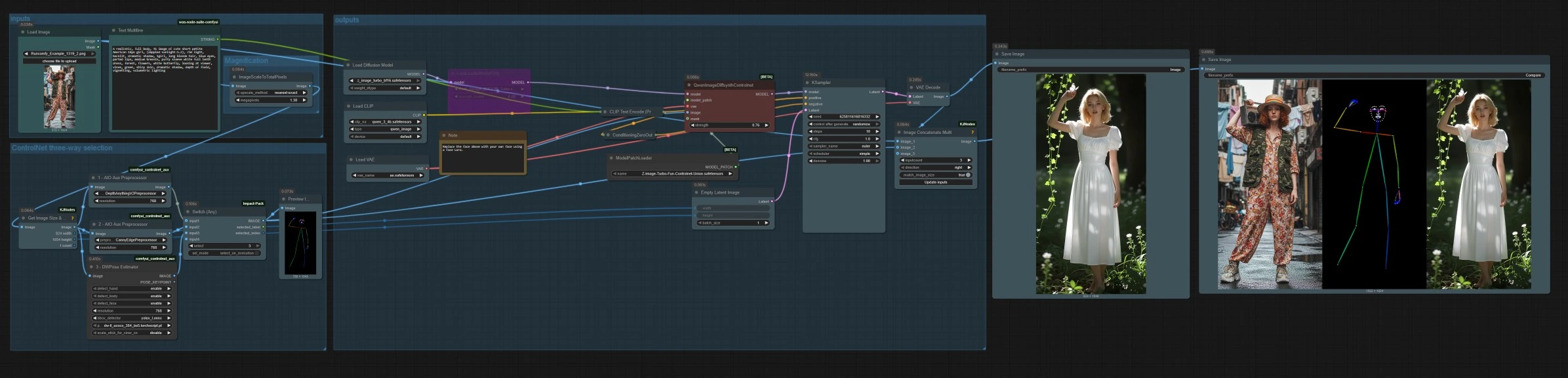








Workflow di Z Image ControlNet per la generazione di immagini guidata dalla struttura in ComfyUI#
Questo workflow porta Z Image ControlNet in ComfyUI così puoi guidare Z-Image Turbo con una struttura precisa da immagini di riferimento. Combina tre modalità di guida in un grafico profondità, bordi canny, e posa umana e ti consente di passare tra di esse per adattarsi al tuo compito. Il risultato è una generazione di testo o immagine di alta qualità e veloce dove layout, posa e composizione rimangono sotto controllo mentre iteri.
Progettato per artisti, designer concettuali e pianificatori di layout, il grafico supporta suggerimenti bilingue e uno stile opzionale LoRA. Ottieni un'anteprima pulita del segnale di controllo scelto più una striscia di confronto automatica per valutare profondità, canny o posa rispetto al risultato finale.
Modelli chiave nel workflow di Comfyui Z Image ControlNet#
- Modello di diffusione Z-Image Turbo 6B parametri. Generatore principale che produce immagini fotorealistiche rapidamente da suggerimenti e segnali di controllo. alibaba-pai/Z-Image-Turbo
- Patch Z Image ControlNet Union. Aggiunge controllo multi-condizione a Z-Image Turbo e consente guida di profondità, bordo e posa in una patch di modello. alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
- Depth Anything v2. Produce mappe di profondità dense utilizzate per la guida di struttura in modalità profondità. LiheYoung/Depth-Anything-V2 on GitHub
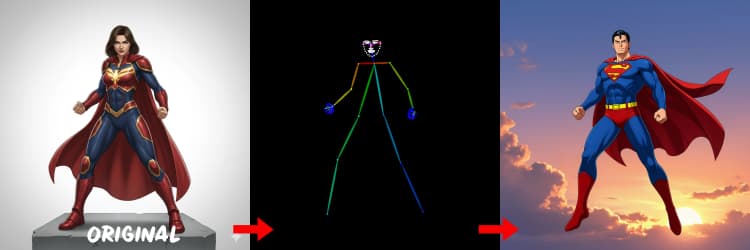
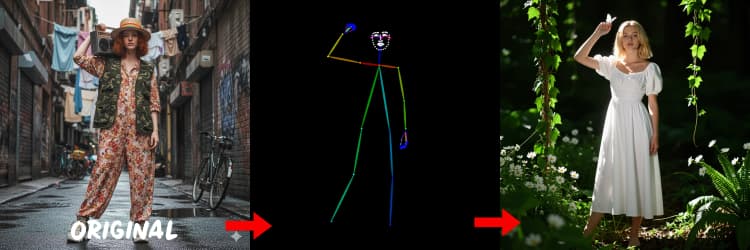
- DWPose. Stima i punti chiave umani e la posa corporea per la generazione guidata dalla posa. IDEA-Research/DWPose
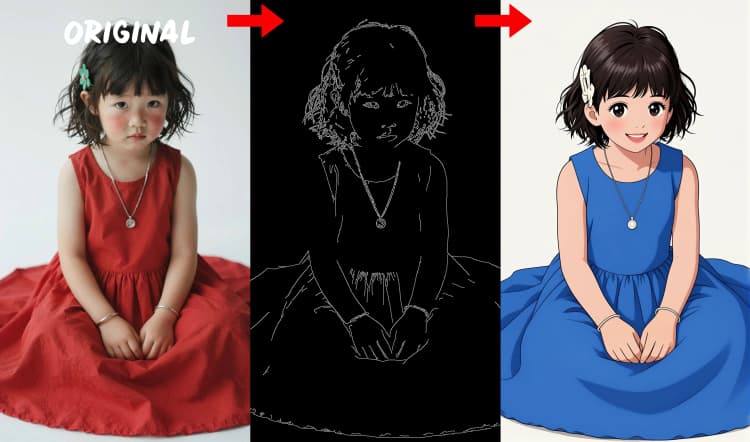
- Rilevatore di bordi Canny. Estrae linee pulite e confini per il controllo guidato dal layout.
- Preprocessori ControlNet Aux per ComfyUI. Fornisce wrapper unificati per profondità, bordi e posa utilizzati da questo grafico. comfyui_controlnet_aux
Come utilizzare il workflow di Comfyui Z Image ControlNet#
A livello generale, carichi o carichi un'immagine di riferimento, selezioni una modalità di controllo tra profondità, canny o posa, quindi generi con un suggerimento testuale. Il grafico ridimensiona il riferimento per un campionamento efficiente, costruisce un latente con proporzioni corrispondenti e salva sia l'immagine finale che una striscia di confronto affiancata.
input#
Usa LoadImage (#14) per scegliere un'immagine di riferimento. Inserisci il tuo suggerimento testuale in Text Multiline (#17) lo stack Z-Image supporta suggerimenti bilingue. Il suggerimento è codificato da CLIPLoader (#2) e CLIPTextEncode (#4). Se preferisci un'immagine guidata puramente dalla struttura, puoi lasciare il suggerimento minimo e fare affidamento sul segnale di controllo selezionato.
Selezione a tre vie ControlNet#
Tre preprocessori convertono il tuo riferimento in segnali di controllo. AIO_Preprocessor (#45) produce profondità con Depth Anything v2, AIO_Preprocessor (#46) estrae bordi canny, e DWPreprocessor (#56) stima la posa del corpo intero. Usa ImpactSwitch (#58) per selezionare quale segnale guida Z Image ControlNet, e controlla PreviewImage (#43) per confermare la mappa di controllo scelta. Scegli profondità quando desideri la geometria della scena, canny per layout nitidi o scatti di prodotto, e posa per lavori sui personaggi.
Suggerimenti per OpenPose: 1. Migliore per Corpo Intero: OpenPose funziona meglio (~70-90% di accuratezza) quando includi "corpo intero" nel tuo suggerimento. 2. Evitare per Primi Piani: L'accuratezza cala significativamente sui volti. Usa Profondità o Canny (bassa/media intensità) per primi piani invece. 3. I Suggerimenti Contano: I suggerimenti influenzano fortemente ControlNet. Evita suggerimenti vuoti per prevenire risultati confusi.
Ingrandimento#
ImageScaleToTotalPixels (#34) ridimensiona il riferimento a una risoluzione pratica di lavoro per bilanciare qualità e velocità. GetImageSizeAndCount (#35) legge la dimensione ridimensionata e passa avanti larghezza e altezza. EmptyLatentImage (#6) crea una tela latente che corrisponde all'aspetto del tuo input ridimensionato così la composizione rimane coerente.
output#
QwenImageDiffsynthControlnet (#39) fonde il modello base con la patch union Z Image ControlNet e l'immagine di controllo selezionata, poi KSampler (#7) genera il risultato guidato dal tuo condizionamento positivo e negativo. VAEDecode (#8) converte il latente in un'immagine. Il workflow salva due output SaveImage (#31) scrive l'immagine finale, e SaveImage (#42) scrive una striscia di confronto tramite ImageConcatMulti (#38) che include la sorgente, la mappa di controllo, e il risultato per un rapido controllo qualità.
Nodi chiave nel workflow di Comfyui Z Image ControlNet#
ImpactSwitch (#58)#
Sceglie quale immagine di controllo guida la generazione profondità, canny, o posa. Cambia modalità per confrontare come ogni vincolo modella composizione e dettaglio. Usalo durante l'iterazione dei layout per testare rapidamente quale guida si adatta meglio al tuo obiettivo.
QwenImageDiffsynthControlnet (#39)#
Collega il modello base, la patch union Z Image ControlNet, il VAE, e il segnale di controllo selezionato. Il parametro strength determina quanto rigorosamente il modello segue l'input di controllo rispetto al suggerimento. Per un abbinamento stretto del layout, aumenta la forza per maggiore variazione creativa, riducila.
AIO_Preprocessor (#45)#
Esegue la pipeline Depth Anything v2 per creare mappe di profondità dense. Aumenta la risoluzione per una struttura più dettagliata o riduci per anteprime più rapide. Si abbina bene con scene architettoniche, scatti di prodotto, e paesaggi dove la geometria è importante.
DWPreprocessor (#56)#
Genera mappe di posa adatte per persone e personaggi. Funziona meglio quando gli arti sono visibili e non pesantemente occultati. Se mani o gambe mancano, prova un riferimento più chiaro o un diverso fotogramma con maggiore visibilità del corpo completo.
LoraLoaderModelOnly (#54)#
Applica un LoRA opzionale al modello base per indizi di stile o identità. Regola strength_model per fondere il LoRA dolcemente o fortemente. Puoi sostituire un LoRA facciale per personalizzare i soggetti o usare un LoRA di stile per fissare un look specifico.
KSampler (#7)#
Esegue il campionamento di diffusione utilizzando il tuo suggerimento e controllo. Regola seed per la riproducibilità, steps per il budget di affinamento, cfg per l'aderenza al suggerimento, e denoise per quanto l'output può deviare dal latente iniziale. Per modifiche immagine-su-immagine, abbassa il denoise per preservare la struttura valori più alti consentono cambiamenti maggiori.
Extra opzionali#
- Per stringere la composizione, usa la modalità profondità con un riferimento pulito e uniformemente illuminato canny favorisce un forte contrasto, e la posa favorisce scatti a corpo intero.
- Per modifiche sottili da un'immagine sorgente, mantieni il denoise modesto e aumenta la forza di ControlNet per una struttura fedele.
- Aumenta i pixel target nel gruppo Ingrandimento quando hai bisogno di più dettagli, poi riduci nuovamente per bozze rapide.
- Usa l'output di confronto per test A/B rapido tra profondità vs canny vs posa e scegliere il controllo più affidabile per il tuo soggetto.
- Sostituisci l'esempio LoRA con il tuo LoRA facciale o di stile per incorporare identità o direzione artistica senza riaddestramento.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Riconosciamo con gratitudine Alibaba PAI per Z Image ControlNet per i loro contributi e manutenzione. Per dettagli autorevoli, fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Alibaba PAI/Z Image ControlNet
- Hugging Face: alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e condizioni fornite dai loro autori e manutentori.

