
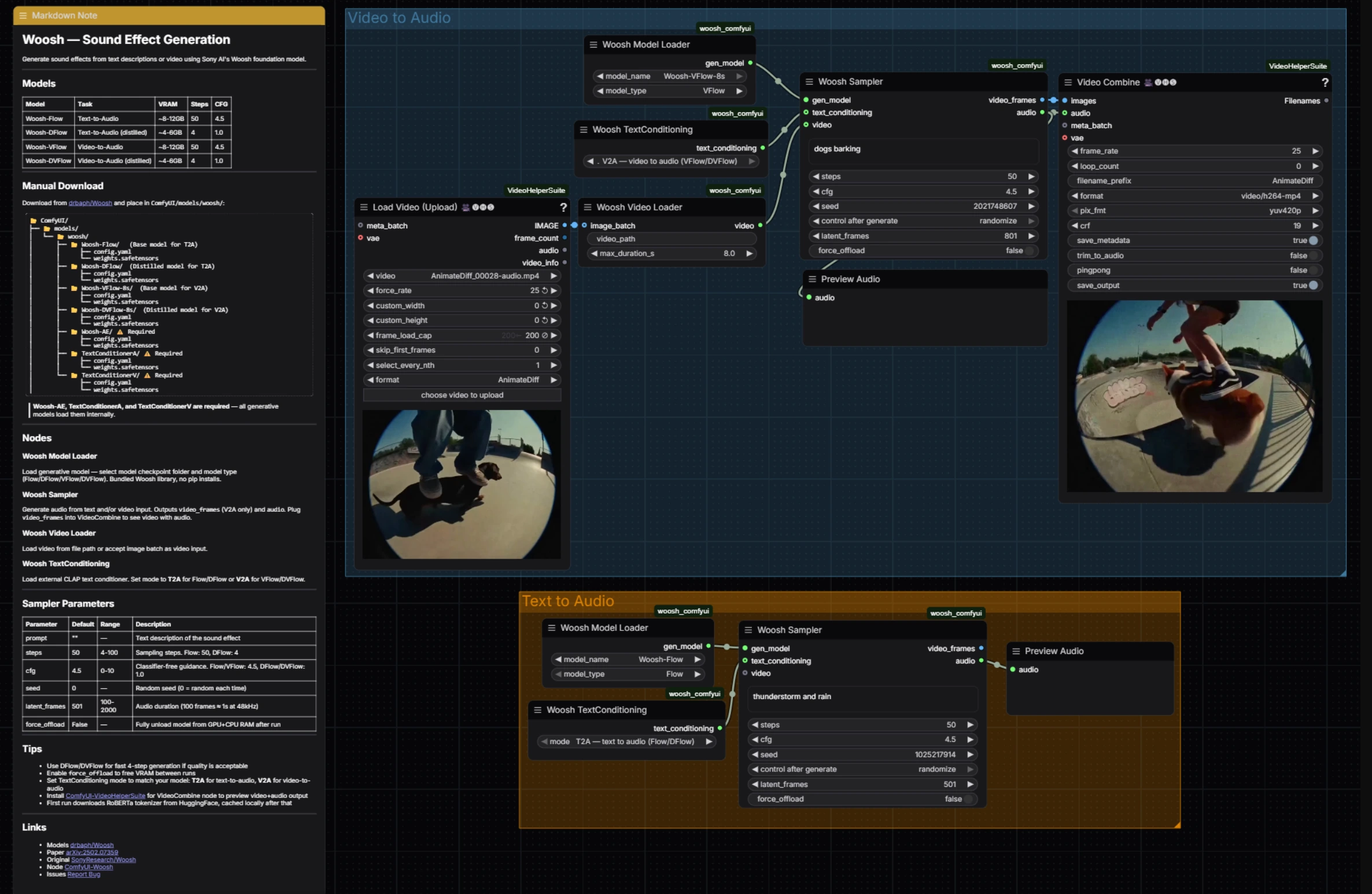
Generazione Effetto Sonoro Woosh: audio condizionato da prompt e video in ComfyUI#
La Generazione Effetto Sonoro Woosh è un flusso di lavoro di ComfyUI che trasforma suggerimenti testuali o clip video in effetti sonori rifiniti utilizzando il modello di base Woosh di Sony Research. È costruito per creatori che necessitano di un unico luogo per Foley basato su prompt, sound design strettamente abbinato ai video e passaggi rapidi tra varianti distillate ad alta qualità e veloci.
Il flusso di lavoro espone entrambe le famiglie di modelli Woosh: Flow/DFlow per text-to-audio e VFlow/DVFlow per video-to-audio. Un campionatore condiviso guida la generazione in entrambi i percorsi, producendo audio per un'anteprima immediata e, nel percorso video, anteprime dei fotogrammi che vengono ricombinate per giornaliere rapide. Dietro le quinte si basa sui nodi ufficiali di ComfyUI Woosh e VideoHelperSuite per un IO video senza soluzione di continuità, quindi la Generazione Effetto Sonoro Woosh resta veloce e semplice pur rimanendo flessibile. Riferimenti: SonyResearch/Woosh, drbaph/Woosh su Hugging Face, paper, ComfyUI-Woosh, ComfyUI-VideoHelperSuite.
Modelli chiave nel flusso di lavoro Generazione Effetto Sonoro Woosh di ComfyUI#
- Sony Research Woosh — Flow: generatore core text-to-audio utilizzato per Foley e ambienti ad alta fedeltà, addestrato con obiettivi di abbinamento di flusso. Vedi SonyResearch/Woosh e il paper.
- Sony Research Woosh — DFlow: modello text-to-audio distillato ottimizzato per la velocità con molti meno passaggi di campionamento, ideale per iterazioni rapide. I pesi sono disponibili tramite drbaph/Woosh.
- Sony Research Woosh — VFlow‑8s: generatore condizionato dal video che sincronizza inizio e texture audio ai segnali di movimento visivo per video-to-audio. Vedi SonyResearch/Woosh.
- Sony Research Woosh — DVFlow‑8s: modello video-to-audio distillato per flussi di lavoro in tempo reale e anteprime rapide. Pesi: drbaph/Woosh.
- Woosh‑AE: l'autoencoder audio utilizzato per ricostruire le forme d'onda dai latenti del modello; richiesto da tutti i generatori. Pesi: drbaph/Woosh.
- TextConditionerA e TextConditionerV: moduli di condizionamento del testo che inseriscono i suggerimenti in modo appropriato per esecuzioni text-to-audio o video-to-audio. Dettagli e utilizzo sono documentati in ComfyUI-Woosh e nel paper.
Come utilizzare il flusso di lavoro Generazione Effetto Sonoro Woosh di ComfyUI#
Questo flusso di lavoro ha due gruppi paralleli che puoi eseguire indipendentemente: Video to Audio per sound design abbinato visivamente e Text to Audio per Foley basato solo su prompt. Entrambi convergono sulla stessa logica del campionatore e su un'anteprima audio rapida, rendendo la Generazione Effetto Sonoro Woosh coerente da operare indipendentemente dall'input.
Video to Audio#
Il gruppo Video to Audio carica una clip, allinea i fotogrammi e il condizionamento, quindi genera suono sincronizzato. Inizia alimentando la tua clip in VHS_LoadVideo (#34); estrae i fotogrammi alla tua velocità scelta in modo che i nodi a valle vedano una sequenza pulita e delimitata. Quei fotogrammi sono confezionati come un flusso di condizionamento video da WooshLoadVideo (#37), che standardizza la durata in modo che il generatore riceva finestre stabili.
Scegli un modello condizionato dal video in WooshLoadFlow (#7), tipicamente VFlow per fedeltà o DVFlow per velocità. Fornisci un breve suggerimento descrittivo nel campionatore (per stile o intento) e imposta WooshTextEncode (#19) su V2A in modo che il testo sia inserito con il corretto ramo di condizionamento. Esegui WooshSample (#38) per sintetizzare l'audio; emette sia audio per PreviewAudio (#9) sia video_frames che fluiscono in VHS_VideoCombine (#33) per una rapida anteprima cucita, mantenendo la Generazione Effetto Sonoro Woosh stretta per la revisione editoriale.
Text to Audio#
Il gruppo Text to Audio si concentra sulla generazione pulita guidata da prompt. Seleziona un modello in WooshLoadFlow (#40), usando Flow quando desideri la massima qualità e DFlow quando hai bisogno di passaggi molto rapidi e iterativi. Imposta WooshTextEncode (#41) su T2A in modo che il tuo prompt sia inserito per la generazione solo di testo. Inserisci la tua descrizione in WooshSample (#39) ed esegui; il risultato viene inviato a PreviewAudio (#43) per un ascolto immediato. Questo percorso mantiene la Generazione Effetto Sonoro Woosh leggera quando stai creando librerie o stratificando effetti senza immagine.
Nodi chiave nel flusso di lavoro Generazione Effetto Sonoro Woosh di ComfyUI#
WooshSample (#38)#
Campionatore centrale per la generazione condizionata dal video. Regola il prompt per indirizzare lo stile e gli inizi, quindi regola steps per il compromesso qualità-velocità (usa meno passaggi quando esegui DVFlow). cfg controlla l'aderenza al prompt, e latent_frames determina la lunghezza dell'output in modo che corrisponda o si distacchi intenzionalmente dalla clip. Imposta seed per riprodurre i take, e abilita force_offload quando hai bisogno di liberare memoria tra lunghe esecuzioni. L'implementazione del nodo e il comportamento seguono l'ufficiale ComfyUI-Woosh.
WooshSample (#39)#
Campionatore per text-to-audio con gli stessi controlli e comportamento, meno il flusso video. Per ideazione rapida scegli DFlow e pochi steps; per finali passa a Flow e aumenta steps per il dettaglio. Mantieni cfg moderato per texture naturali, spingilo più in alto per risultati stilizzati e bloccati al prompt. Usa latent_frames per impostare la durata con precisione quando costruisci asset per librerie o timeline DAW.
WooshLoadFlow (#7)#
Selettore modello per il percorso Video to Audio. Scegli VFlow per il massimo allineamento della fedeltà al movimento, o DVFlow quando hai bisogno di anteprime quasi in tempo reale. Assicurati che WooshTextEncode sia impostato su V2A in modo che gli embed corrispondano alla famiglia di modelli scelta. Vedi drbaph/Woosh per varianti del modello.
WooshLoadFlow (#40)#
Selettore modello per il percorso Text to Audio. Scegli Flow per dettagli ricchi e maggiore varietà di texture, o DFlow per iterazioni rapide con passaggi minimi. Abbinalo a WooshTextEncode in modalità T2A per evitare disallineamenti di condizionamento. Il comportamento e le opzioni del nodo seguono l'ufficiale ComfyUI-Woosh.
VHS_VideoCombine (#33)#
Utilità per assemblare l'audio generato con l'anteprima video_frames dal campionatore per produrre una clip revisionabile. Usalo per individuare la sincronizzazione, valutare le transizioni e condividere giornaliere senza lasciare ComfyUI. Parte di ComfyUI-VideoHelperSuite.
Extra opzionali#
- Usa DVFlow/DFlow per passaggi di esplorazione rapidi, quindi passa a VFlow/Flow per finali quando la Generazione Effetto Sonoro Woosh deve brillare.
- Mantieni la tua clip di input entro la finestra del modello selezionato (ad esempio, le varianti VFlow di 8 secondi) e processa scene più lunghe in segmenti sovrapposti che puoi dissolvere incrociando.
- Mantieni un frame rate costante da
VHS_LoadVideoaVHS_VideoCombineper ridurre la deriva tra audio e immagine. - Per i prompt, abbina parole d'azione a contesto di texture e acustico (ad esempio, "veloce sibilo metallico in una scala di cemento") per ottenere risultati prevedibili.
- Attiva
force_offloadnel campionatore tra esecuzioni pesanti se la memoria GPU è limitata.
Riconoscimenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo sentitamente Sony Research per Woosh (progetto e paper), Saganaki22 per ComfyUI-Woosh (nodo ComfyUI) e Kosinkadink per ComfyUI-VideoHelperSuite per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Saganaki22/ComfyUI-Woosh
- GitHub: Saganaki22/ComfyUI-Woosh
- drbaph/Woosh
- Hugging Face: drbaph/Woosh
- SonyResearch/Woosh
- GitHub: SonyResearch/Woosh
- Sony Research/Woosh (paper)
- arXiv: 2502.07359
- Kosinkadink/ComfyUI-VideoHelperSuite
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.