
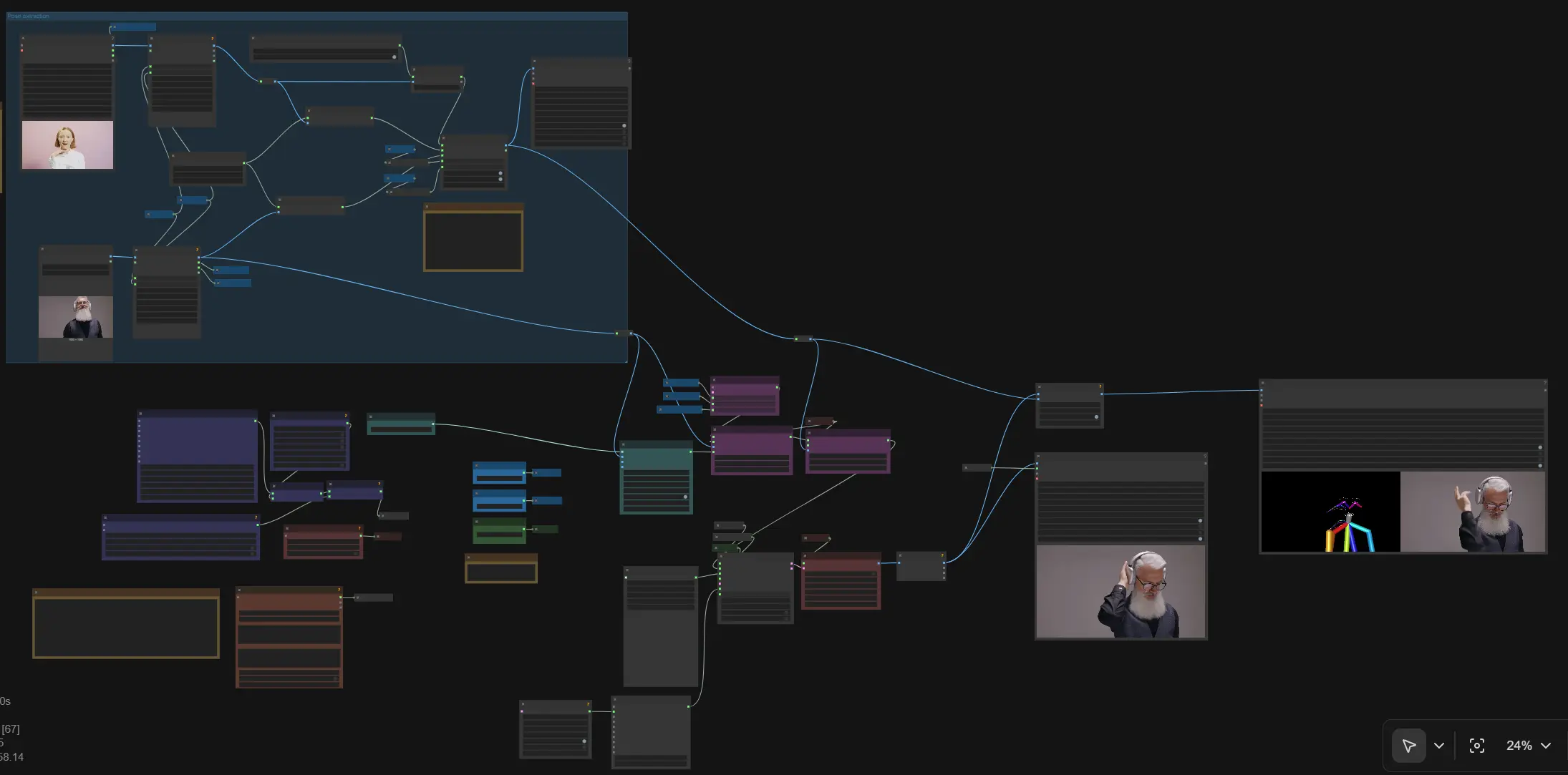
Animazione di personaggi guidata da pose SCAIL in ComfyUI#
Questo flusso di lavoro porta SCAIL in ComfyUI per animazioni di personaggi guidate da pose e basate su riferimenti. Combinando un'unica immagine di riferimento con pose umane estratte, SCAIL mantiene l'identità del soggetto, la struttura corporea e il movimento coerente tra i fotogrammi mentre controlli lo stile con i prompt. Supporta un video di input per il trasferimento del movimento o immagini più pose renderizzate per la coreografia, quindi produce video multi-frame con passaggio audio opzionale.
Usa questo flusso di lavoro SCAIL per il trasferimento di movimento di danza e azione, animazione di personaggi stilizzati e sequenze multi-shot coerenti dove la stabilità temporale e le pose accurate sono importanti. Sotto il cofano funziona su WanVideo per la generazione di video con diffusione-trasformatore, aumenta l'identità tramite visione CLIP e guida la struttura con segnali di pose NLF e ViTPose/DWPose, tutto cablato per un campionamento efficiente di sequenze lunghe.
Nota: A causa di limitazioni di compatibilità, la macchina 2XL non può essere utilizzata con l'attuale flusso di lavoro ComfyUI.
Modelli chiave nel flusso di lavoro SCAIL di ComfyUI#
- SCAIL: Animazione di personaggi di livello studio tramite iniezione di pose a contesto completo e una rappresentazione di pose 3D coerente; il cuore della conservazione dell'identità e della fedeltà delle pose di questo flusso di lavoro. GitHub, arXiv
- Wan 2.x Image-to-Video backbone: grandi modelli di diffusione video usati qui come backbone per il campionamento condizionato da SCAIL; supporta attività di I2V e animazione di alta qualità. Esempi: Wan-AI/Wan2.1-I2V-14B-480P, Wan-AI/Wan2.2-Animate-14B
- UMT5-XXL text encoder: variante multilingue T5 utilizzata dalle pipeline Wan per trasformare i prompt in embedding di condizionamento. Hugging Face
- CLIP ViT-H/14 vision encoder: estrae caratteristiche robuste dell'immagine di riferimento per ancorare l'identità durante la sintesi video. GitHub
- ViTPose (Whole-Body): stimatore di pose umane 2D di alta qualità che fornisce punti chiave densi per corpo, mani e viso utilizzati dalle utilità di allineamento e disegno di SCAIL. GitHub
- DWPose: formato di punti chiave per tutto il corpo e modelli sfruttati per dettagli opzionali di viso/mani e allineamento delle pose. GitHub
- NLF (Neural Localizer Fields): predice segnali continui di pose/forme umane che vengono resi nelle immagini di pose 3D-consapevoli di SCAIL utilizzate per un forte controllo strutturale. GitHub
- YOLOv10: rilevatore veloce utilizzato nella catena di pre-elaborazione delle pose per la localizzazione delle persone. GitHub
Come usare il flusso di lavoro SCAIL di ComfyUI#
Flusso generale: carica un'immagine di riferimento e un video di guida opzionale; estrai e renderizza le pose; codifica il riferimento con la visione CLIP; aggiungi embedding di riferimento SCAIL e pose SCAIL; assembla il condizionamento del testo; campiona i fotogrammi con WanVideo; decodifica ed esporta il video. Il grafico include variabili pubbliche "Set_" così larghezza, altezza, CFG e conteggio dei fotogrammi propagano automaticamente.
- Input e dimensionamento
- Carica un'immagine di riferimento del personaggio o un video per il trasferimento del movimento. Il flusso di lavoro ridimensiona il riferimento alla dimensione di generazione e garantisce che le dimensioni target siano divisibili per 32. Se carichi un video, il suo audio è disponibile per il passaggio all'esportazione finale.
- Imposta larghezza, altezza e conteggio dei fotogrammi una volta; i valori alimentano il campionatore, il decodificatore e l'esportatore tramite getter e setter condivisi. Mantieni il rapporto di aspetto coerente tra riferimento e output per minimizzare gli artefatti di stiramento.
- Estrazione delle pose (gruppo: Estrazione delle pose)
- I fotogrammi video di input o le immagini vengono ridimensionati per l'analisi e alimentati a un predittore di pose NLF e a un rilevatore ViTPose. L'output di ViTPose viene convertito nel formato DWPose per dettagli opzionali di viso/mani e per allineare la posa globale al soggetto di riferimento.
- Le immagini di pose SCAIL renderizzate vengono prodotte a metà della risoluzione di generazione internamente per efficienza, quindi composte alla dimensione target, preservando segnali di profondità e occlusioni. Il disegno di viso/mani può essere attivato mentre si utilizza ancora l'allineamento; scollega DWPose se vuoi disabilitare l'allineamento delle pose.
- Codifica dell'identità di riferimento
- L'immagine di riferimento è codificata con CLIP ViT-H/14 e convertita in embedding di immagini WanVideo. Questi embedding catturano colore, texture e struttura locale così che SCAIL possa mantenere il personaggio coerente attraverso movimenti impegnativi.
- Se l'identità deriva in scatti lunghi o stilizzati, mantieni un riferimento pulito e frontale ed evita tagli pesanti; questo rafforza il segnale CLIP utilizzato a valle.
- Condizionamento delle pose SCAIL
- Le pose SCAIL renderizzate sono iniettate come embedding di immagini aggiuntivi. Agiscono come una forte guida strutturale che impone il posizionamento degli arti, l'ordinamento della profondità e la stabilità della silhouette tra i fotogrammi.
- Puoi scambiare la sorgente di guida in questa fase: usa pose estratte da un video per il trasferimento del movimento o alimenta immagini di pose SCAIL pre-renderizzate per coreografare sequenze senza un driver.
- Condizionamento dei prompt di testo
- I prompt sono codificati in embedding di testo che influenzano stile, guardaroba, illuminazione e ambiente. Usa descrittori concisi che completano l'immagine di riferimento; il testo negativo può ridurre la sovrasaturazione, gli artefatti o il disordine.
- I prompt sono opzionali quando vuoi che l'output segua da vicino l'aspetto del riferimento sotto il controllo di SCAIL.
- Campionamento e pianificazione
- Il campionatore WanVideo esegue la diffusione-trasformatore con modello, scheduler, embedding di immagini (riferimento + pose SCAIL), embedding di testo e guida CFG. Un nodo di opzioni di contesto può suddividere lunghe sequenze per una generazione a memoria economica mantenendo la continuità temporale.
- Se noti sfarfallio o bordi morbidi, considera uno scheduler più lento o un CFG leggermente più forte; se il movimento sembra troppo vincolato, riduci la guida generale così che i segnali di struttura e aspetto di SCAIL si bilancino naturalmente.
- Decodifica ed esportazione
- I latenti sono decodificati in fotogrammi usando il Wan VAE e il video è scritto con il tuo tasso di fotogrammi e prefisso del nome file scelti. Il flusso di lavoro può concatenare i visual per fette A/B e passa l'audio quando collegato.
- Ispeziona l'output; se braccia o gambe si incastrano durante le curve veloci, rivedi la qualità dell'estrazione delle pose o gli input di allineamento, quindi riprogramma con gli stessi semi per un'iterazione controllata.
Nodi chiave nel flusso di lavoro SCAIL di ComfyUI#
WanVideoAddSCAILReferenceEmbeds(#350)- Aggiunge condizionamento di identità e aspetto dall'immagine di riferimento nel flusso di embedding delle immagini. Aumenta la sua influenza quando il volto o l'abbigliamento del personaggio deriva; diminuisci se il modello si rifiuta di adattarsi a grandi rotazioni del corpo o illuminazioni drammatiche.
WanVideoAddSCAILPoseEmbeds(#324)- Inietta immagini di pose SCAIL renderizzate come guida strutturale. Aumenta la sua influenza per un posizionamento più rigoroso degli arti e stabilità della silhouette; abbassa se il movimento sembra troppo rigido o se vuoi più libertà per i prompt di stile per piegare leggermente la posa.
RenderNLFPoses(#362)- Rende previsioni continue NLF in immagini di pose in stile SCAIL, sovrapponendo opzionalmente viso/mani DWPose e eseguendo l'allineamento pose-riferimento. Mantieni il rendering interno delle pose a metà della risoluzione target per adattarsi al design di SCAIL ed evitare aliasing; scollega DWPose per rimuovere l'allineamento.
WanVideoSamplerv2(#348)- Guida il campionamento principale della diffusione con modello, embedding di immagini/testo, scheduler, argomenti extra e
cfg. Se vedi oscillazione temporale, usa uno scheduler più stabile o più passaggi; se i dettagli superano il riferimento, abbassacfgcosì che i segnali di identità di SCAIL guidino.
- Guida il campionamento principale della diffusione con modello, embedding di immagini/testo, scheduler, argomenti extra e
WanVideoSchedulerv2(#349)- Controlla il comportamento del programma di denoising. Scegli programmi che bilanciano dettaglio e stabilità; i programmi più lenti spesso migliorano la coerenza temporale per movimenti ampi e lunghe sequenze.
WanVideoClipVisionEncode(#327)- Codifica l'immagine di riferimento con ViT-H/14 e produce embedding di immagini CLIP per l'identità. Usa riferimenti di alta qualità e ben illuminati; le viste frontali o a 3/4 tendono ad ancorare meglio volti e capelli.
Extra opzionali#
- Le dimensioni devono essere divisibili per 32. Mantieni allineati i rapporti di aspetto di riferimento e output per evitare distorsioni.
- SCAIL si aspetta render di pose a metà della risoluzione di generazione; questo flusso di lavoro lo calcola automaticamente quindi non è necessario gestirlo manualmente.
- Per mani ed espressioni precise, mantieni DWPose collegato per abilitare segnali di viso/mani; per disabilitare solo l'allineamento, scollega il collegamento DWPose ma mantieni le immagini di pose renderizzate.
- Lunghe sequenze: usa il nodo di opzioni di contesto per suddividere la generazione per efficienza di memoria mantenendo sovrapposizioni per transizioni fluide.
- Se usi i pesi di anteprima SCAIL ripacchettati per ComfyUI, prelevali dalle distribuzioni della comunità quando necessario. Esempio di pacchetto di anteprima: Kijai/WanVideo_comfy SCAIL e Kijai/WanVideo_comfy_fp8_scaled SCAIL.
Riconoscimenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine Ai Verse Z.ai (zai-org) per SCAIL (implementazione ufficiale) e teal024 per la pagina del progetto SCAIL per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione e ai repository originali collegati di seguito.
Risorse#
- zai-org/SCAIL
- GitHub: zai-org/SCAIL
- Hugging Face: zai-org/SCAIL-Preview
- arXiv: arXiv:2512.05905
- teal024/SCAIL Project Page
- Documenti / Note di rilascio: Pagina del Progetto
- GitHub: zai-org/SCAIL
- Hugging Face: zai-org/SCAIL-Preview
- arXiv: arXiv:2512.05905
Nota: L'uso dei modelli, dei set di dati e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.

