
Pose Control LipSync con Wan2.2 S2V: immagine‑a‑video controllato da audio e pose per avatar espressivi#
Pose Control LipSync con Wan2.2 S2V trasforma un'immagine singola, una clip audio e un video di riferimento di posa in una performance parlante sincronizzata. Il personaggio nella tua immagine di riferimento segue il movimento corporeo del video di riferimento mentre i movimenti labiali corrispondono all'audio. Questo flusso di lavoro ComfyUI è ideale per avatar, scene narrative, trailer, video esplicativi e video musicali in cui desideri un controllo preciso su posa, espressione e tempistica del parlato.
Costruito sulla famiglia di modelli Wan 2.2 S2V 14B, il flusso di lavoro fonde prompt testuali, funzionalità vocali pulite e mappe di posa per generare movimento cinematografico con identità stabile. È progettato per essere semplice da utilizzare mentre offre ai creatori un controllo fine su aspetto, ritmo e inquadratura.
Modelli chiave nel flusso di lavoro Comfyui Pose Control LipSync con Wan2.2 S2V#
- Wan2.2‑S2V‑14B. Il generatore core da parlato a video che trasforma un'immagine statica più audio in video, con condizionamento opzionale della posa per la guida del movimento. Consulta il repository ufficiale e la scheda del modello per capacità e note d'uso: Wan‑Video/Wan2.2 e Wan‑AI/Wan2.2‑S2V‑14B.
- Wan VAE. L'autoencoder Wan codifica e decodifica latenti video con alta fedeltà ed è utilizzato in tutte le pipeline Wan 2.x. Implementazione di riferimento: pipeline Wan in Diffusers documentazione.
- Google UMT5‑XXL text encoder. Fornisce forte condizionamento testuale multilingue per controllo di intenti di scena e stile ad alto livello all'interno delle pipeline Wan. Scheda del modello: google/umt5‑xxl.
- Facebook Wav2Vec2‑Large. Estrae funzionalità vocali robuste che guidano la sincronizzazione labiale e le micro-espressioni. Scheda del modello: facebook/wav2vec2‑large‑960h.
- DWPose con rilevatore YOLOX. Genera punti chiave di posa umana e mappe di posa dal video di riferimento per guidare il movimento del corpo intero. Repos: IDEA‑Research/DWPose e Megvii‑BaseDetection/YOLOX.
- LightX2V LoRA per Wan. Una LoRA leggera utilizzata per accelerare la denoising di stile immagine‑a‑video a basso numero di passi mantenendo la qualità del movimento; Wan 2.2 supporta le LoRA nei suoi denoisers. Consulta la guida di Wan Diffusers sull'uso di LoRA in Wan pipelines.
Come utilizzare il flusso di lavoro Comfyui Pose Control LipSync con Wan2.2 S2V#
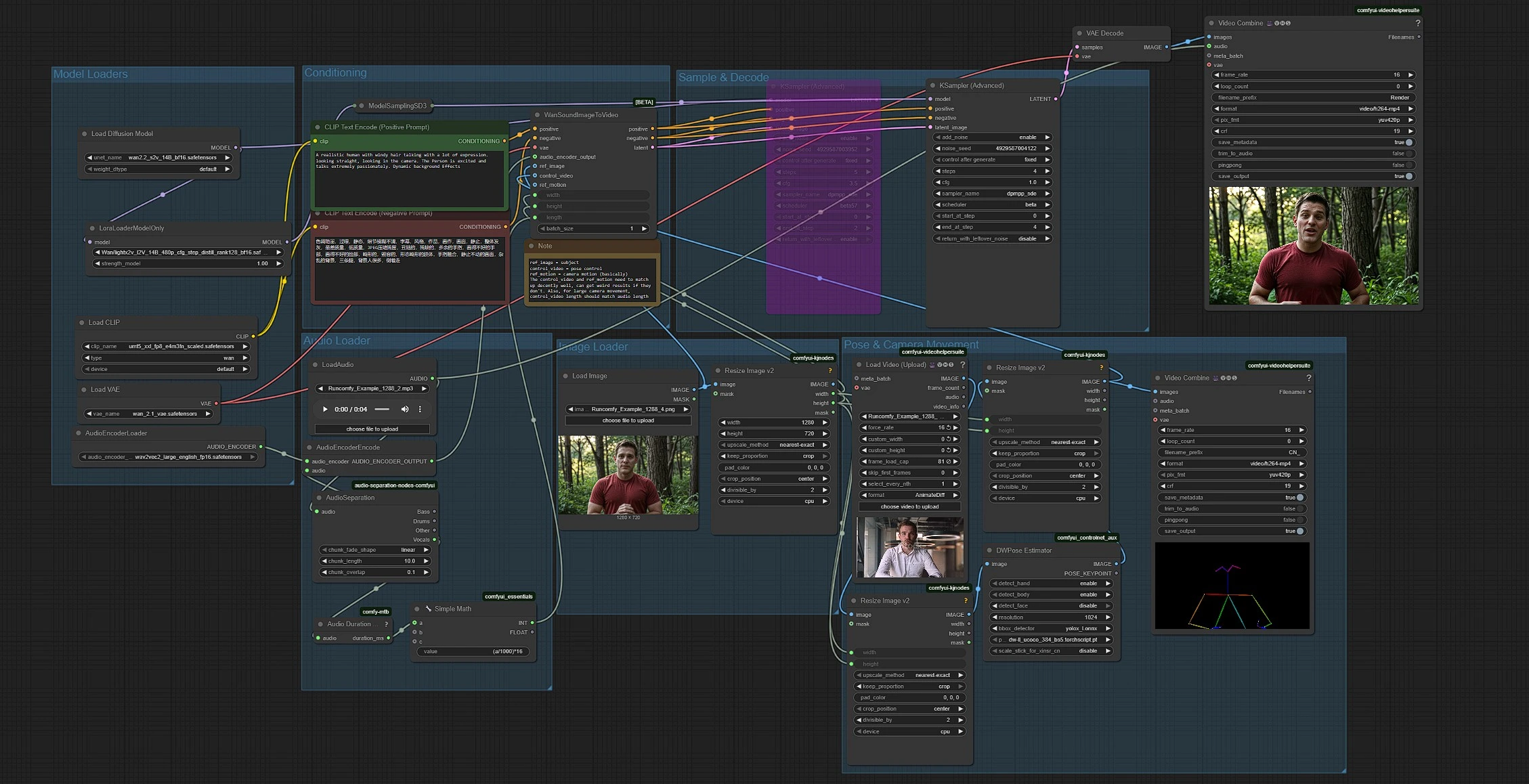
Il flusso di lavoro combina cinque parti: caricamento del modello, preparazione audio, input di immagine e posa, condizionamento e generazione. I gruppi funzionano in un flusso da sinistra a destra, con la lunghezza audio che imposta automaticamente la durata della clip a 16 fps.
Caricatori di Modelli#
Questo gruppo carica il modello Wan 2.2 S2V, il suo VAE, l'encoder di testo UMT5‑XXL e una LoRA LightX2V. Il trasformatore base è inizializzato in UNETLoader (#37) e adattato con LoraLoaderModelOnly (#61) per un campionamento a basso numero di passi più veloce. Il VAE Wan è fornito da VAELoader (#39). Gli encoder di testo sono forniti da CLIPLoader (#38) che carica i pesi UMT5‑XXL referenziati da Wan. Raramente hai bisogno di toccare questo gruppo a meno che tu non scambi file di modello.
Caricatore Audio#
Inserisci un file audio con LoadAudio (#58). AudioSeparation (#85) isola il canale vocale in modo che le labbra seguano un parlato o un canto chiaro piuttosto che strumenti di sottofondo. Audio Duration (mtb) (#70) misura la clip e SimpleMath+ (#71) converte la durata in un conteggio di fotogrammi a 16 fps in modo che la lunghezza del video corrisponda al tuo audio. AudioEncoderEncode (#56) alimenta un encoder Wav2Vec2‑Large in modo che Wan possa mappare i fonemi alle forme della bocca per una sincronizzazione labiale accurata.
Caricatore di Immagini#
LoadImage (#52) fornisce il soggetto fermo che porta l'identità, l'abbigliamento e l'impostazione della fotocamera. ImageResizeKJv2 (#69) legge le dimensioni dall'immagine in modo che la pipeline derivi costantemente larghezza e altezza target per tutte le fasi successive. Usa un'immagine nitida, frontale con una bocca non ostruita per i movimenti labiali più fedeli.
Movimento di Posa e Fotocamera#
VHS_LoadVideo (#80) importa il tuo video di riferimento di posa. ImageResizeKJv2 (#83) adatta i fotogrammi alla dimensione target, e DWPreprocessor (#78) li trasforma in mappe di posa con rilevamento YOLOX più punti chiave DWPose. Un ultimo ImageResizeKJv2 (#81) allinea i fotogrammi di posa alla risoluzione di generazione prima che siano passati avanti come video di controllo. Puoi visualizzare in anteprima le uscite di posa indirizzando a VHS_VideoCombine (#95), che aiuta a confermare che l'inquadratura e la tempistica di riferimento si adattino al tuo soggetto.
Condizionamento#
Scrivi lo stile e l'intento della scena in CLIP Text Encode (Positive Prompt) (#6) e utilizza CLIP Text Encode (Negative Prompt) (#7) per scoraggiare artefatti indesiderati. I prompt guidano l'estetica ad alto livello e il movimento di sfondo, mentre l'audio guida i movimenti delle labbra e il riferimento di posa governa la dinamica del corpo. Mantieni i prompt concisi e allineati con il tuo angolo di fotocamera target e l'umore.
Campionamento e Decodifica#
WanSoundImageToVideo (#55) fonde testo, funzionalità audio, l'immagine di riferimento e il video di controllo di posa, quindi prepara una sequenza latente. KSamplerAdvanced (#64) esegue denoising a basso numero di passi adatto all'accelerazione in stile LightX2V, e VAEDecode (#8) ricostruisce i fotogrammi. VHS_VideoCombine (#62) assembla i fotogrammi in un MP4 e allega il tuo audio originale in modo che l'output sia pronto per essere rivisto o modificato.
Nodi chiave nel flusso di lavoro Comfyui Pose Control LipSync con Wan2.2 S2V#
WanSoundImageToVideo (#55)#
Il cuore del flusso di lavoro che condiziona Wan2.2‑S2V con il tuo prompt, vocali, immagine del soggetto e video di controllo di posa. Regola solo ciò che conta: imposta width, height e length per adattarsi all'immagine del soggetto e alla lunghezza audio, e collega un video di posa pre-processato per il controllo del movimento. Lascia ref_motion vuoto a meno che tu non preveda di iniettare una traccia di fotocamera separata. Il comportamento da parlato a video del modello è descritto in Wan‑AI/Wan2.2‑S2V‑14B e Wan‑Video/Wan2.2.
DWPreprocessor (#78)#
Genera mappe di posa utilizzando YOLOX per il rilevamento e DWPose per punti chiave del corpo intero. Forti indicazioni di posa aiutano Wan a seguire arti e torso mentre l'audio controlla le labbra e le espressioni. Se il tuo riferimento ha un forte movimento della fotocamera, usa un video di posa che allinei il punto di vista e la tempistica con la performance desiderata. DWPose e le sue varianti sono documentate in IDEA‑Research/DWPose.
KSamplerAdvanced (#64)#
Esegue denoising per la sequenza latente. Con una LoRA LightX2V caricata, puoi mantenere bassi i passi per anteprime veloci mantenendo la coerenza del movimento; aumenta i passi quando spingi per il massimo dettaglio. Le scelte del scheduler influenzano la fluidità del movimento rispetto alla nitidezza, e dovrebbero essere regolate insieme all'uso della LoRA come descritto per Wan nella documentazione Diffusers documentazione.
VHS_LoadVideo (#80)#
Importa e scruta il tuo riferimento di posa. Usa i suoi strumenti di selezione del fotogramma in-nodo per scegliere l'esatto segmento che corrisponde al tuo segmento audio. Mantenere l'inquadratura e la dimensione del soggetto coerenti con l'immagine di riferimento stabilizzerà il trasferimento del movimento. Il nodo fa parte di VideoHelperSuite: ComfyUI‑VideoHelperSuite.
VHS_VideoCombine (#62)#
Combina i fotogrammi generati e il tuo audio in un MP4 e salva i metadati del flusso di lavoro. Imposta il frame rate di output a 16 fps per corrispondere al conteggio dei fotogrammi calcolato dalla durata audio in questo flusso di lavoro. Disattiva o attiva il salvataggio dei metadati a seconda delle tue esigenze di gestione degli asset. Consulta la documentazione di VideoHelperSuite su ComfyUI‑VideoHelperSuite.
AudioSeparation (#85)#
Isola i vocali in modo che le funzionalità Wav2Vec2 guidino le forme delle bocche senza interferenze da strumenti o effetti. Se il tuo input è già un parlato chiaro, puoi bypassare la separazione. Per i migliori risultati, mantieni i livelli audio coerenti e minimizza il riverbero.
Extra opzionali#
- Per la migliore sincronizzazione labiale, preferisci parlato chiaro o vocali a cappella. Wav2Vec2 funziona a 16 kHz; la maggior parte delle pipeline risampla automaticamente, ma fornire file a 16 kHz aiuta.
- Usa un'immagine del soggetto ben illuminata e frontale con denti e labbra visibili. Le occlusioni riducono l'accuratezza.
- Abbina l'inquadratura e il movimento del riferimento di posa al tuo soggetto. I grandi movimenti della fotocamera funzionano meglio quando la lunghezza del video di posa corrisponde al segmento audio.
- Inizia a 480p per iterazioni rapide; passa a 720p per la qualità finale. Wan 2.2 supporta entrambe le risoluzioni in S2V.
- Mantieni i prompt brevi e coerenti con l'impostazione della fotocamera nella tua immagine e riferimento di posa per evitare conflitti.
- Se sperimenti con le LoRA, assicurati che siano compatibili con i denoisers di Wan 2.2. Consulta le note su LoRA nella Wan Diffusers documentazione.
Questo flusso di lavoro Pose Control LipSync con Wan2.2 S2V ti offre un percorso rapido dall'audio e un'immagine fissa a una performance controllabile e a ritmo che appare coesiva e sembra espressiva.
Riconoscimenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo @ArtOfficialLabs di Pose Control LipSync con Wan2.2 S2VDemo per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- YouTube/Pose Control LipSync con Wan2.2 S2VDemo
- Documenti / Note di rilascio da @ArtOfficialLabs: Pose Control LipSync con Wan2.2 S2VDemo
Nota: l'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.