
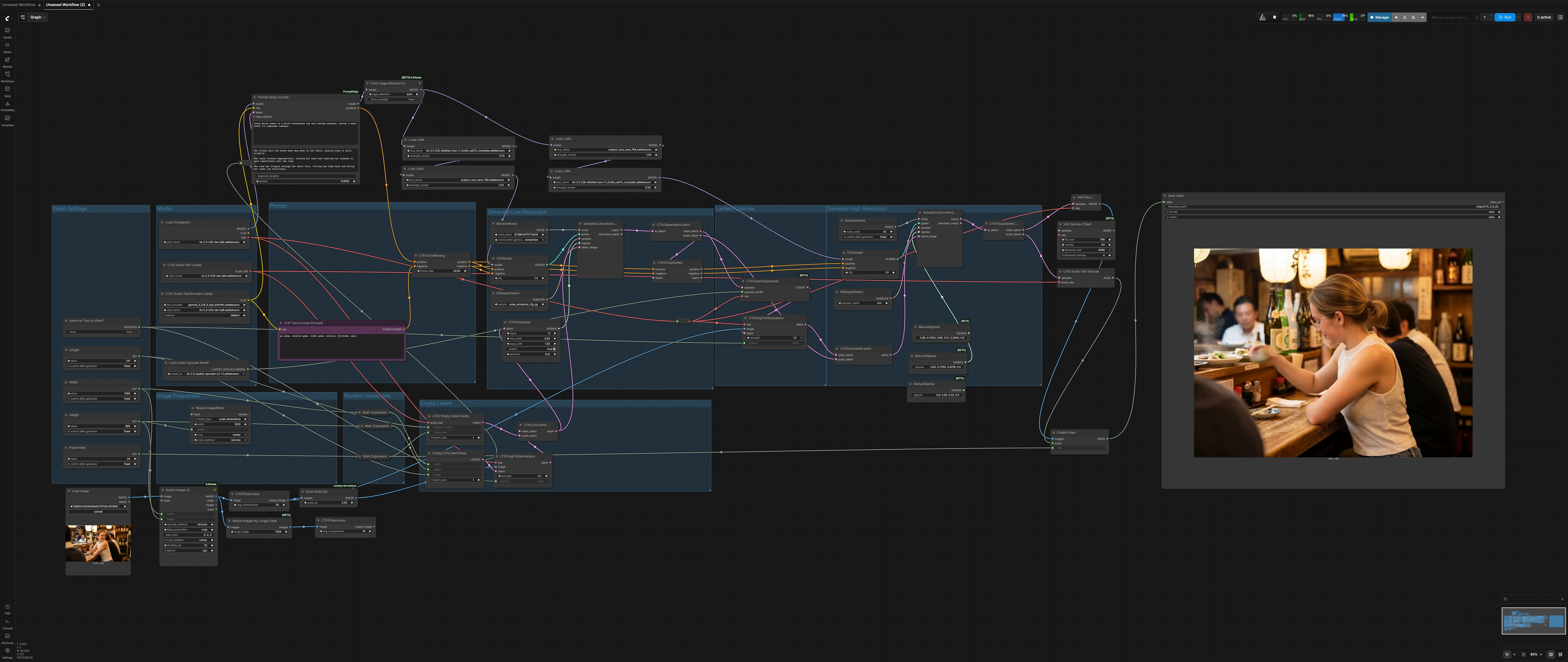
LTX 2.3 Sulphur image to video workflow: immagine a video cinematografico con movimento controllabile#
Questo LTX 2.3 Sulphur image to video workflow trasforma un singolo fermo in uno scatto cinematografico pronto per la pubblicazione con micro-espressioni naturali, movimento credibile dei personaggi e continuità atmosferica stabile. È progettato per scatti narrativi in cui desideri controllo sul feeling della telecamera, l'atmosfera e le dinamiche della scena senza perdersi nei dettagli di configurazione.
Il workflow esegue una pipeline di diffusione a due fasi attorno a LTX-2.3: un passaggio a bassa risoluzione per stabilire movimento e tempistica, seguito da un upscale latente e un passaggio di raffinamento ad alta risoluzione per i dettagli finali. Un Sulphur style LoRA guida l'aspetto e i toni della pelle, mentre la segmentazione dei prompt supporta l'evoluzione dei ritmi lungo lo scatto. Attiva un singolo interruttore per eseguire il classico image-to-video o puro text-to-video secondo le necessità.
Modelli chiave nel Comfyui LTX 2.3 Sulphur image to video workflow#
- Lightricks LTX-2.3-22B dev FP8. Il checkpoint di diffusione video di base che guida generazione e decodifica mantenendo l'uso della memoria pratico. Model card
- LTX-2.3 Spatial Upscaler x2. Un modello di super-risoluzione latente usato tra i passaggi per preservare il movimento aggiungendo fedeltà spaziale. Model page
- Gemma 3 12B instruction-tuned text encoder confezionato per LTX-2. Abilita un conditioning ricco e fondato per prompt globali e segmentati. Repository
- Sulphur style LoRA e LTX-2.3 distilled LoRA 1.1. LoRA accoppiati che stabilizzano il realismo facciale e il tono cinematografico mantenendo il controllo dei prompt.
Come usare Comfyui LTX 2.3 Sulphur image to video workflow#
Flusso generale: imposta dimensioni e lunghezza dello scatto, prepara la tua immagine statica, definisci un prompt globale più eventuali ritmi di prompt locali, quindi esegui il rendering. La fase a bassa risoluzione costruisce movimento e tempistica, l'upscaler latente solleva i dettagli, e la fase ad alta risoluzione finalizza texture e illuminazione prima della decodifica in MP4.
Impostazioni Video#
Scegli il tuo Width, Height, Length (fotogrammi) e Frame Rate target. Le dimensioni sono impostate per essere divisibili per le dimensioni della griglia di diffusione comuni per evitare artefatti. Un singolo booleano, Switch to Text to Video? (#28), controlla se l'immagine statica viene iniettata o bypassata. Mantieni il rapporto d'aspetto coerente con l'immagine di input per l'inquadratura più pulita, specialmente per volti e mani.
Preprocesso Immagine#
La tua immagine sorgente è caricata, ridimensionata e leggermente compressa per la prontezza alla diffusione usando ImageResizeKJv2 (#75) e LTXVPreprocess (#76). Una versione scalata è alimentata al passaggio a bassa risoluzione per un movimento stabile, mentre la versione a maggiore dettaglio è disponibile per il passaggio ad alta risoluzione. Usa questa sezione per allineare inquadratura e spazio extra prima della generazione. Sottile regolazioni pre-crop qui ripagano in linee degli occhi più coerenti e continuità dello sfondo.
Latente Vuoto#
EmptyLTXVLatentVideo (#21) e LTXVEmptyLatentAudio (#33) costruiscono latenti video e audio sincronizzati usando le impostazioni del tuo scatto. Sono uniti da LTXVConcatAVLatent (#32) per stabilire una struttura temporale che i nodi a valle affineranno. Il ramo audio crea una traccia silenziosa e valida in modo che l'MP4 finale venga riprodotto affidabilmente ovunque. Questi latenti ancorano anche i segmenti di prompt in modo che i cambiamenti di movimento avvengano dove previsto.
Prompt#
Scrivi la descrizione del tuo scatto in PromptRelayEncode (#80). Usa un prompt globale conciso per l'aspetto complessivo, quindi aggiungi righe specifiche per ritmo come prompt locali, separati dal carattere |, per evolvere micro-azioni lungo il clip. L'encoder di testo LTX da LTXAVTextEncoderLoader (#5) gestisce la semantica, mentre CLIPTextEncode (#41) fornisce un forte prompt negativo orientato al realismo. LTXVConditioning (#31) mescola il conditioning positivo e negativo e li sincronizza con il frame rate.
Modello#
CheckpointLoaderSimple (#44) carica la base LTX-2.3. PathchSageAttentionKJ (#67) ottimizza l'attenzione per immagini grandi. Una breve catena di LoRA applica lo stile Sulphur e una LoRA di stabilità distillata prima di ogni fase di campionamento. Questo design bilancia la coerenza dell'aspetto con la reattività del prompt in modo che l'identità del personaggio e l'illuminazione rimangano coerenti tra i passaggi.
Genera Bassa Risoluzione#
Questo primo passaggio di diffusione stabilisce il movimento. LTXVImgToVideoInplace (#22) inietta il tuo fermo preprocessato nella timeline; se Switch to Text to Video? è abilitato, il suo input bypass disabilita pulitamente l'iniezione di immagini per T2V puro. LTXVScheduler (#47) modella il programma sigma per controllare l'ampiezza del movimento e la fluidità temporale. SamplerCustomAdvanced (#9), guidato da CFGGuider (#42) e KSamplerSelect (#17), sintetizza un latente A/V coerente a bassa risoluzione. LTXVSeparateAVLatent (#35) poi divide i percorsi video e audio e inoltra le informazioni di inquadratura a LTXVCropGuides (#10) per una composizione consapevole delle guide.
Upscale Latente#
LTXVLatentUpsampler (#13) con il LTX-2.3 Spatial Upscaler solleva i dettagli spaziali nello spazio latente preservando il movimento appreso dal primo passaggio. L'upscaling qui evita di reinventare la tempistica e riduce lo sfarfallio spesso visto con la rigenerazione ingenua del secondo passaggio. Consegna un latente più nitido e coerente nel movimento alla fase finale di raffinamento.
Genera Alta Risoluzione#
La fase raffinata ricombina il latente video upscalato e il latente audio tramite LTXVConcatAVLatent (#3). CFGGuider (#8) e KSamplerSelect (#6) guidano un campionatore veloce e orientato ai dettagli in SamplerCustomAdvanced (#36) usando un programma sigma ottimizzato per la finitura. Se hai lasciato abilitata l'iniezione di immagini, un secondo LTXVImgToVideoInplace (#14) aiuta il modello a rispettare il fermo ad alta risoluzione senza perdere il movimento già stabilito. Il risultato è una sequenza cinematografica stabile con dinamiche naturali di occhi e bocca.
Output#
VAEDecode (#68) trasforma il latente video finale in fotogrammi mentre LTXVAudioVAEDecode (#23) ricostruisce la traccia audio silenziosa. CreateVideo (#38) muxa fotogrammi e audio al tuo frame rate selezionato, e SaveVideo (#45) scrive un MP4 H.264 per una revisione e condivisione immediata. Usa un prefisso di nome file descrittivo per scatto per mantenere organizzate le iterazioni.
Conversione Numerica#
Un piccolo blocco utility calcola dimensioni a metà scala per la costruzione latente per gestire VRAM e velocità. Di solito non è necessario toccarli, ma assicurano che larghezza e altezza a monte guidino tutto in modo coerente. Se cambi la risoluzione di base, questi si adattano automaticamente.
Nodi chiave nel Comfyui LTX 2.3 Sulphur image to video workflow#
PromptRelayEncode(#80). Centralizza un prompt globale e prompt locali ritmo per ritmo allineati alla timeline. Usalo per sceneggiare micro-espressioni e piccole rivelazioni di telecamera lungo lo scatto. Mantieni i prompt locali brevi e specifici in modo che completino piuttosto che combattano l'aspetto globale.LTXVImgToVideoInplace(#22, #14). Inietta l'immagine ferma nei latenti a bassa e alta risoluzione. Aumentastrengthquando vuoi che il finale aderisca strettamente al fotogramma di riferimento; riducilo per maggiore libertà. L'inputbypassè collegato all'interruttore Text-to-Video in modo da poter disabilitare l'iniezione di immagini pulitamente per le esecuzioni T2V.LTXVScheduler(#47). Controlla come i livelli di rumore evolvono durante il passaggio a bassa risoluzione, che influisce direttamente sull'intensità e fluidità del movimento. Usalo per domare scatti eccessivamente attivi o per aggiungere una spinta sottile quando le cose sembrano statiche. Le regolazioni qui sono più evidenti su volti, capelli ed energia della telecamera simile a quella a mano libera.LTXVLatentUpsampler(#13). Esegue un upscaling latente x2 con l'upscaler spaziale di LTX, preservando i segnali di movimento appresi nel primo passaggio. Usalo per aggiungere texture nitide e definizione dei bordi prima della raffinazione ad alta risoluzione senza riavvolgere la tempistica.CFGGuider(#42, #8). Bilancia quanto fortemente il modello segue i tuoi prompt rispetto ai suoi priors appresi. Se i volti si spostano o lo stile si indebolisce, aumenta la guida; se i dettagli sembrano forzati o plastici, riducila. Abbina le modifiche a uno sguardo rapido al prompt negativo per mantenere il realismo.KSamplerSelect(#17, #6). Ti consente di scegliere l'algoritmo di campionamento per fase. Favorisci un campionatore robusto ed espressivo per il passaggio a bassa risoluzione e un'opzione veloce e orientata ai dettagli per il passaggio finale. Mantieni la scelta coerente tra le iterazioni quando confronti gli aspetti.
Extra opzionali#
- Per un comportamento deliberato della telecamera, puoi aggiungere una LoRA di controllo della telecamera come Dolly-Left dalla famiglia LTX alla tua catena di caricamento LoRA quando desideri una spinta laterale coerente. Model page
- Mantieni larghezza e altezza divisibili per 32 per evitare disallineamenti nelle operazioni latenti e mantenere l'efficienza VRAM.
- Usa verbi brevi e attivi nei prompt locali per coreografare i ritmi, ad esempio stringi la presa, guarda altrove, ammorbidisci il sorriso.
- Se miri a dimensioni di output molto elevate, considera la possibilità di sostituire
VAEDecodeconVAEDecodeTiled(#43) per decodificare i fotogrammi in modo più efficiente in termini di memoria. - Quando i volti sono più importanti, itera modificando solo il testo del prompt e
CFGGuiderprima di cambiare campionatore o risoluzione. Questo mantiene i confronti significativi e fa emergere la migliore formulazione per il LTX 2.3 Sulphur image to video workflow.
Ringraziamenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine RunningHub per il riferimento al workflow, Lightricks per la famiglia LTX 2.3 (modello, upscaler spaziale e LoRA di controllo della telecamera), e Comfy-Org per l'encoder di testo LTX per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- RunningHub/RunningHub workflow reference
- Docs / Release Notes: runninghub.ai post
- Lightricks/LTX 2.3 model source
- Hugging Face: Lightricks/LTX-2.3-fp8
- Lightricks/LTX 2.3 spatial upscaler source
- Hugging Face: Lightricks/LTX-2.3
- Lightricks/LTX camera-control LoRA source
- Hugging Face: Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Comfy-Org/LTX text encoder source
- Hugging Face: Comfy-Org/ltx-2
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.
