
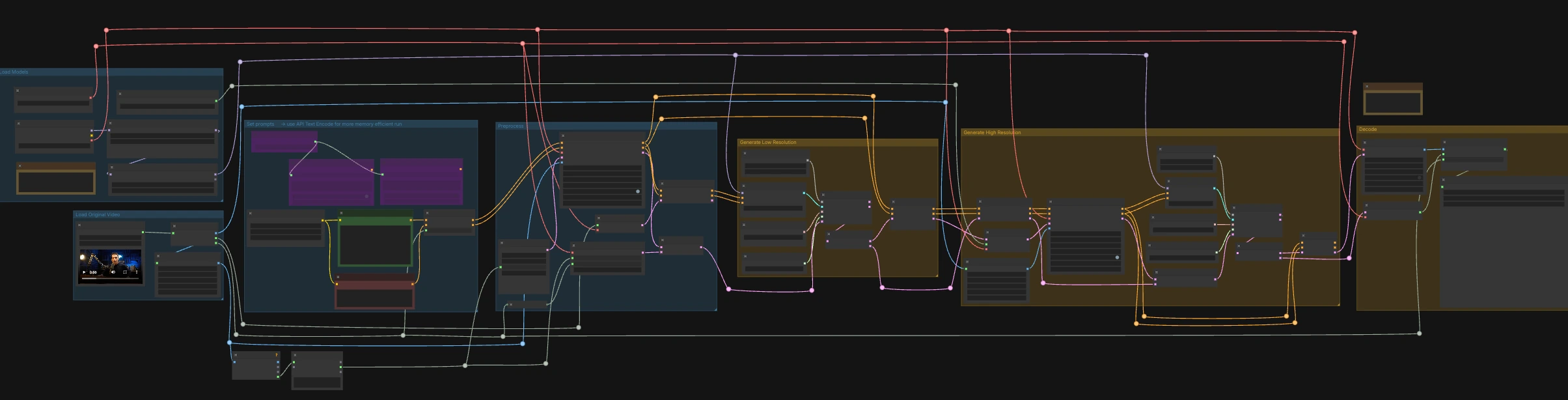
LTX-2.3 ICLoRA LipDub per ComfyUI#
LTX-2.3 ICLoRA LipDub è un workflow a due passaggi, controllato da video e audio, per ComfyUI, che doppia una persona parlante mantenendo costanti identità e movimento. Combina il conditioning di testo e video Lightricks LTX-2.3 con il LipDub IC-LoRA per allineare con precisione il movimento delle labbra al discorso fornito, quindi affina il risultato a risoluzione più alta per dettagli nitidi. Il grafico è preparato per RunComfy con nomi di input/output standardizzati in modo da poter scambiare media e ripetere le esecuzioni in modo affidabile.
Questo workflow ComfyUI LTX-2.3 ICLoRA LipDub è ideale per i creatori che necessitano di doppiaggio multilingue, riformulazioni o correzioni simili all'ADR mantenendo la performance originale. Fornisci un video sorgente che includa già il discorso target, descrivi la scena e ciò che la persona dovrebbe dire, e il workflow sintetizzerà visivi e audio sincronizzati in un clip finito.
Modelli chiave nel workflow ComfyUI LTX-2.3 ICLoRA LipDub#
- Modello video base LTX-2.3 22B. Il modello di diffusione di base che genera il video e governa come i prompt influenzano l'aspetto, il movimento e lo stile.
- LTX-2.3 IC-LoRA LipDub. Un LoRA specializzato per il doppiaggio labiale che condiziona il modello a seguire il discorso fornito e ad allineare le forme delle labbra ai fonemi mantenendo identità e movimento della testa. Scheda del modello
- LTX-2.3 Audio VAE. Codifica il discorso di input in un latente audio che può essere iniettato nel conditioning del testo e successivamente decodificato di nuovo in forma d'onda, garantendo che il timing rimanga bloccato ai fotogrammi.
- LTX-2.3 Spatial Upscaler x2. Aumenta la risoluzione spaziale dei latenti video prima del passaggio di raffinamento ad alta risoluzione, migliorando la texture senza cambiare il movimento.
- LTX-2.3 Distilled LoRA (384). Un LoRA di potenziamento utilizzato insieme al checkpoint di base per migliorare il dettaglio e la stabilità temporale senza adattarsi eccessivamente al fotogramma di riferimento.
Come usare il workflow ComfyUI LTX-2.3 ICLoRA LipDub#
Questo workflow si esegue in due fasi coordinate: un passaggio a bassa risoluzione per bloccare il timing e le forme labiali all'audio, seguito da un passaggio ad alta risoluzione che aumenta e affina i dettagli pur mantenendo la sincronizzazione. Inizia caricando un video sorgente che contenga già il discorso desiderato, quindi scrivi la linea di testo che vuoi che la persona dica.
Carica Video Originale#
Il nodo LoadVideo (#5002) importa il tuo clip sorgente con audio incorporato. GetVideoComponents (#5010) estrae fotogrammi, audio e frame rate; il frame rate è condiviso in tutto il grafico in modo che video e audio rimangano allineati. Due ridimensionatori, Resize Image/Mask (s1 size) (#5009) e Resize Image/Mask (s2 size) (#5003), preparano i flussi di immagini di lavoro per i passaggi a bassa e alta risoluzione. Il conteggio dei fotogrammi è misurato e arrotondato per lunghezze adatte ai campionatori in modo che la decodifica rimanga stabile.
Carica Modelli#
CheckpointLoaderSimple (#5017) carica il modello di base LTX-2.3 22B e VAE utilizzati in tutto il grafico. Due caricamenti, LoraLoaderModelOnly (#5018) e LTXICLoRALoaderModelOnly (#5012), aggiungono il LoRA distillato e l'IC-LoRA LipDub sopra il base in modo che il generatore segua il discorso mantenendo l'identità. LTXVAudioVAELoader (#4010) fornisce il VAE audio per codificare/decodificare la colonna sonora. L'uscita latent_downscale_factor del caricatore IC-LoRA è intenzionalmente non utilizzata qui perché l'addestramento LipDub presuppone fotogrammi di riferimento a piena risoluzione, in linea con la nota inclusa.
Imposta prompt#
Scrivi la descrizione della scena e la linea esatta pronunciata in CLIP Text Encode (Positive Prompt) (#2483). Usa CLIP Text Encode (Negative Prompt) (#2612) per minimizzare tratti o artefatti indesiderati. Questi alimentano LTXVConditioning (#1241), che adatta il conditioning al dominio video e trasferisce il contesto del frame-rate. Per esecuzioni a basso VRAM, il grafico include anche encoder basati su API (🅛🅣🅧 Gemma API Text Encode - POSITIVE (#4980) e ... - NEGATIVE (#4981)) regolati dalla stringa LTX API KEY (#4979); il cablaggio predefinito utilizza encoder locali.
Preprocessa#
LTXVAudioVAEEncode (#5005) converte il discorso sorgente in un latente audio, e LTXVSetAudioRefTokens (#5006) inietta quel latente nel conditioning del testo in modo che il generatore “senta” il timing e i fonemi. EmptyLTXVLatentVideo (#3059) prepara un latente video segnaposto con la corretta dimensione spaziale e un conteggio di fotogrammi allineato all'input. LTXAddVideoICLoRAGuide (#5004) attacca la guida di riferimento IC-LoRA utilizzando i fotogrammi s1, stabilendo identità e attenzione alla regione delle labbra prima del campionamento.
Genera Bassa Risoluzione#
Un ciclo di diffusione standard è formato da CFGGuider (#4828), KSamplerSelect (#4831), ManualSigmas (#4984), e SamplerCustomAdvanced (#4829). Il campionatore opera su un latente audio+video composto da LTXVConcatAVLatent (#4528), garantendo che il conditioning audio partecipi in ogni passaggio. Dopo il campionamento, LTXVSeparateAVLatent (#4845) divide il latente in modo che LTXVSetAudioRefTokens (#5013) possa congelare la stessa rappresentazione del discorso per il passaggio ad alta risoluzione. Questo stadio blocca le forme labiali al discorso e imposta la base del movimento alla dimensione s1.
Genera Alta Risoluzione#
LTXVLatentUpsampler (#4975) eleva il latente video utilizzando lo Spatial Upscaler x2, preservando il movimento mentre aggiunge capacità per dettagli spaziali. LTXAddVideoICLoRAGuide (#5014) riapplica l'IC-LoRA alla dimensione s2 utilizzando i fotogrammi ad alta risoluzione in modo che l'identità, la regione delle labbra e le caratteristiche fini siano rinforzate. Un secondo ciclo di diffusione (CFGGuider (#4964), KSamplerSelect (#4976), ManualSigmas (#4985), SamplerCustomAdvanced (#4971)) affina il latente upscalato mentre LTXVConcatAVLatent (#4969) mantiene il latente del discorso congelato in sincrono. LTXVCropGuides (#5011, #5015) gestisce ritagli sicuri e guide di regione in modo che il viso rimanga correttamente inquadrato attraverso entrambi i passaggi.
Decodifica#
LTXVTiledVAEDecode (#4995) converte il latente video finale in immagini utilizzando tiles per l'efficienza VRAM, e LTXVAudioVAEDecode (#4848) restituisce l'audio sincronizzato. CreateVideo (#4849) assembla i fotogrammi e l'audio al frame rate originale, e SaveVideo (#4852) scrive il file con il nome preimpostato di RunComfy; cambia questo valore per marchiare i tuoi output. Il risultato è un clip LTX-2.3 ICLoRA LipDub completamente sincronizzato pronto per la revisione o la consegna.
Nodi chiave nel workflow ComfyUI LTX-2.3 ICLoRA LipDub#
LTXICLoRALoaderModelOnly (#5012)#
Carica il LipDub IC-LoRA e lo collega al modello di base in modo che il movimento delle labbra segua il discorso di input senza sovrascrivere l'identità. Se hai bisogno di un controllo delle labbra più forte o più sottile, regola il peso del LoRA qui; mantienilo coordinato con qualsiasi altro LoRA che applichi nello stack per evitare un eccessivo conditioning.
LTXAddVideoICLoRAGuide (#5004)#
Applica la guida IC-LoRA nella fase a bassa risoluzione utilizzando i fotogrammi di riferimento ridimensionati. Questo è il punto in cui il workflow blocca per la prima volta identità e attenzione alla regione delle labbra; usalo per test A/B attivando o disattivando la guida per vedere l'effetto della guida di riferimento su timing e articolazione.
LTXAddVideoICLoRAGuide (#5014)#
Riapplica la guida IC-LoRA ad alta risoluzione con i fotogrammi s2 in modo che il passaggio raffinato preservi la stessa identità del parlante e le forme labiali accurate. Se cambi la dimensione del fotogramma ad alta risoluzione, rivedi questo nodo per mantenere la guida di riferimento coerente con il tuo output target.
LTXVSetAudioRefTokens (#5006)#
Vincola il discorso codificato al tuo conditioning di testo in modo che il campionatore allinei visemi con fonemi. Usa lo stesso latente audio in tutti i passaggi per risultati stabili; questo grafico lo gestisce automaticamente, ma se cambi audio a metà esecuzione dovresti aggiornare sia il conditioning che il latente concatenato.
LTXVLatentUpsampler (#4975)#
Aumenta il latente video con lo Spatial Upscaler x2 LTX-2.3 per fare spazio ai dettagli fini prima del campionatore ad alta risoluzione. Se il VRAM è limitato, abbina questo con dimensioni s2 più piccole o tiling più leggero nel decodificatore per bilanciare qualità e throughput.
LTXVTiledVAEDecode (#4995)#
Decodifica il latente finale in fotogrammi utilizzando il tiling per adattare uscite grandi su GPU limitate. Regola il conteggio e la sovrapposizione dei tile qui per scambiare velocità con l'impronta di memoria; meno tile sono più veloci ma richiedono più VRAM, mentre più tile riducono la VRAM a scapito del tempo.
Extra opzionali#
- Prompting per il doppiaggio: includi le parole esatte che vuoi pronunciate; il modello non traduce automaticamente. Usa lo script nativo della lingua target, mantieni un solo speaker e punta a una lunghezza simile alla linea originale in modo che il ritmo rimanga naturale.
- Suggerimenti per le prestazioni: se incontri limiti di VRAM, riduci il ridimensionamento s2 in
Resize Image/Mask (s2 size)(#5003) e aumenta il tiling inLTXVTiledVAEDecode(#4995). Per la ripetibilità, mantieni i semi diRandomNoisefissi in entrambi i passaggi. - Predefiniti del workflow: il nome del file di input di esempio è precompilato in
LoadVideo(#5002), e il salvatore imposta un nome di output coerente. Sostituisci entrambi per eseguire più corse LTX-2.3 ICLoRA LipDub senza sovrascrivere i risultati. - Inquadratura: se il viso si sposta vicino ai bordi, regola
LTXVCropGuides(#5011, #5015) in modo che la regione delle labbra rimanga in un ritaglio stabile attraverso entrambi i passaggi.
Ringraziamenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo sinceramente Lightricks per il modello LTX-2.3-22b-IC-LoRA-LipDub e RunComfy per il workflow condiviso di ComfyUI (fonte Cloud Save) per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- arXiv: arXiv:2601.22143
- RunComfy/Cloud Save source
- Docs / Release Notes: RunComfy shared workflow
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.