
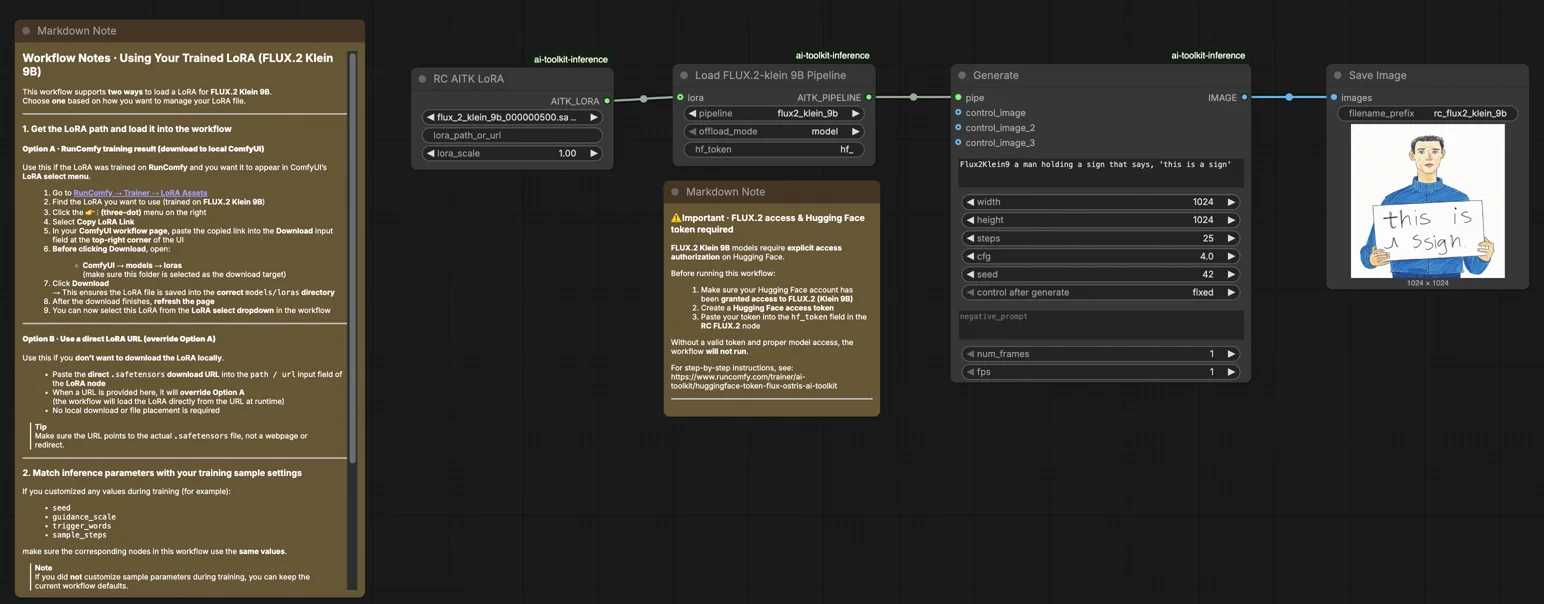
FLUX.2 Klein 9B LoRA ComfyUI Inferenza: generazione di LoRA allineata alle anteprime dell'AI Toolkit in ComfyUI#
Usa questo workflow di RunComfy quando hai bisogno di un'inferenza ComfyUI che rimanga coerente con le anteprime di addestramento dell'AI Toolkit per i FLUX.2 Klein 9B LoRAs. L'impostazione instrada la generazione attraverso Flux2Klein9BPipeline—un wrapper di pipeline specifico del modello open-source da RunComfy—piuttosto che un grafico di campionamento standard. Il tuo adattatore viene applicato tramite lora_path e lora_scale all'interno di quella pipeline, offrendoti un comportamento corrispondente all'addestramento LoRA senza ricostruzione manuale della pipeline.
Perché FLUX.2 Klein 9B LoRA ComfyUI Inferenza spesso appare diversa in ComfyUI#
Quando l'AI Toolkit rende un'anteprima di addestramento, esegue la completa pipeline di inferenza FLUX.2 Klein 9B—codifica del testo Qwen3-8B, pianificazione del flusso e iniezione interna di LoRA avvengono tutte come un'unità coordinata. Un tipico grafico ComfyUI riassembla questi componenti in modo indipendente, il che introduce sottili differenze nel condizionamento, nella pianificazione del rumore e nell'ordine di applicazione dell'adattatore. Il risultato è una deriva a livello di pipeline, non un singolo controllo mal configurato. Flux2Klein9BPipeline colma questo divario eseguendo la pipeline del modello end-to-end e iniettando il tuo LoRA al suo interno. Riferimento: `src/pipelines/flux2_klein.py`.
Come utilizzare il workflow FLUX.2 Klein 9B LoRA ComfyUI Inferenza#
Passo 1: Ottieni il percorso LoRA e caricalo nel workflow (2 opzioni)#
Opzione A — Risultato dell'addestramento RunComfy > scarica su ComfyUI locale:
- Vai a Trainer > LoRA Assets
- Trova il FLUX.2 Klein 9B LoRA che desideri utilizzare
- Clicca sul menu ... (tre punti) a destra > seleziona Copia Link LoRA
- Nella pagina del workflow ComfyUI, incolla il link copiato nel campo di input Download nell'angolo in alto a destra dell'interfaccia
- Prima di cliccare su Download, assicurati che la cartella di destinazione sia impostata su ComfyUI > models > loras (questa cartella deve essere selezionata come destinazione di download)
- Clicca su Download — il file LoRA viene salvato nella directory
models/lorascorretta - Dopo che il download è terminato, aggiorna la pagina
- Ora il LoRA appare nel menu a discesa di selezione LoRA — selezionalo

Opzione B — URL diretto LoRA (sostituisce l'Opzione A):
- Incolla l'URL diretto di download
.safetensorsnel campo di inputpath / urldel nodo LoRA - Quando un URL è fornito qui, sostituisce l'Opzione A — il workflow recupera il LoRA direttamente dall'URL al momento dell'esecuzione
- Non è richiesto alcun download locale o posizionamento di file
Suggerimento: conferma che l'URL risolva effettivamente il file .safetensors, non una pagina di destinazione o un reindirizzamento.

Passo 2: Allinea i parametri di inferenza con le impostazioni del tuo campione di addestramento#
Imposta lora_scale sul nodo LoRA per controllare la forza dell'adattatore—inizia con il valore utilizzato durante le anteprime di addestramento e regola da lì.
I parametri rimanenti sono sui nodi Generate e Load Pipeline:
prompt— il tuo prompt di testo; includi eventuali parole chiave di attivazione dall'addestramentowidth/height— risoluzione di output; abbina la dimensione dell'anteprima di addestramento per un confronto diretto (multipli di 16)sample_steps— passi di inferenza; FLUX.2 Klein 9B predefiniti a 25guidance_scale— forza CFG; il valore predefinito è 4.0 (Klein 9B non è guidance-distilled, quindi questo valore modella direttamente la qualità dell'output)seed— fissa un seed per riprodurre un output specifico; cambia per esplorare variazioniseed_mode—fixedorandomizehf_token— è richiesto un valido token Hugging Face poiché FLUX.2 Klein 9B è un modello con accesso limitato; incolla il tuo token nel campohf_tokensul nodo Load Pipeline
Suggerimento per l'allineamento dell'addestramento: se hai personalizzato i valori di campionamento durante l'addestramento (seed, guidance_scale, sample_steps, parole chiave di attivazione), copia quegli esatti valori nei campi corrispondenti. Se hai addestrato su RunComfy, apri Trainer > LoRA Assets > Config per visualizzare il YAML risolto e trasferire le impostazioni di anteprima/campione.

Passo 3: Esegui FLUX.2 Klein 9B LoRA ComfyUI Inferenza#
Clicca su Queue/Run — il nodo SaveImage scrive i risultati nella tua cartella di output ComfyUI.
⚠️ Importante · Accesso a FLUX.2 & token Hugging Face richiesti#
I modelli FLUX.2 Klein 9B richiedono autorizzazione esplicita su Hugging Face.
Prima di eseguire questo workflow:
- Assicurati che il tuo account Hugging Face abbia ottenuto l'accesso a FLUX.2 (Klein 9B)
- Crea un token di accesso Hugging Face
- Incolla il tuo token nel campo
hf_tokennel nodo RC FLUX.2
Senza un token valido e un accesso corretto al modello, il workflow non funzionerà.
Per istruzioni dettagliate, vedi: https://www.runcomfy.com/trainer/ai-toolkit/huggingface-token-flux-ostris-ai-toolkit
Checklist rapida:
- ✅ L'account Hugging Face ha accesso a FLUX.2 Klein 9B e un token valido è in
hf_token - ✅ LoRA è: scaricato in
ComfyUI/models/loras(Opzione A), o caricato tramite un URL diretto.safetensors(Opzione B) - ✅ Pagina aggiornata dopo il download locale (solo Opzione A)
- ✅ I parametri di inferenza corrispondono alla configurazione del campione di addestramento (se personalizzati)
Se tutto sopra è corretto, i risultati dell'inferenza qui dovrebbero corrispondere strettamente alle tue anteprime di addestramento.
Risoluzione dei problemi FLUX.2 Klein 9B LoRA ComfyUI Inferenza#
La maggior parte delle discrepanze "anteprima di addestramento vs inferenza ComfyUI" su FLUX.2 Klein 9B derivano da differenze a livello di pipeline (percorso dell'encoder di testo, pianificazione/condizionamento e dove/come viene applicato l'adattatore). Il workflow RunComfy evita di ricostruire manualmente la pipeline eseguendo la generazione attraverso Flux2Klein9BPipeline e iniettando il LoRA all'interno di quella pipeline tramite lora_path / lora_scale, che è il modo più vicino per riprodurre il comportamento dell'anteprima dell'AI Toolkit in ComfyUI.
(1) Errore 401 Client.#
Perché succede FLUX.2 Klein 9B è un modello con accesso limitato su Hugging Face. Se il tuo account non ha accesso, o non viene fornito un token valido, i pesi del modello non possono essere scaricati e l'inferenza fallisce con un errore 401.
Come risolvere
- Assicurati che il tuo account Hugging Face abbia ottenuto l'accesso a
black-forest-labs/FLUX.2-klein-base-9B. - Crea un token di accesso Hugging Face e incollalo nel campo
hf_tokensul nodo Load Pipeline. - Dopo che l'accesso e il token sono stati confermati, esegui l'inferenza attraverso i nodi della pipeline AI Toolkit di RunComfy in modo che autenticazione e caricamento del modello avvengano in un'unica pipeline coerente.
- Per istruzioni dettagliate, vedi: https://www.runcomfy.com/trainer/ai-toolkit/huggingface-token-flux-ostris-ai-toolkit
(2) Errori CLIPLoader dei modelli Flux 2 Klein#
Perché succede Questi errori sono causati da un disallineamento dell'encoder di testo—ad esempio, caricando un encoder incompatibile o mescolando asset dell'encoder Klein 4B e Klein 9B. Questo spesso appare come disallineamenti di dimensioni di embedding o vocabolario durante il caricamento del CLIP/encoder di testo.
Come risolvere
- Aggiorna ComfyUI all'ultima versione per assicurarti che il supporto FLUX.2 Klein sia completo.
- Assicurati che venga utilizzato l'encoder di testo corretto per Klein 9B (Klein 9B richiede Qwen3-8B; l'uso di un encoder 4B fallirà).
- Per un'inferenza LoRA allineata alle anteprime, preferisci il wrapper di pipeline di RunComfy, che carica l'encoder corretto e applica il LoRA nella stessa pipeline utilizzata per le anteprime dell'AI Toolkit.
(3) le forme di mat1 e mat2 non possono essere moltiplicate (512x2560 e 7680x3072)#
Perché succede Questo errore indica un disallineamento delle dimensioni del condizionamento, tipicamente causato dall'uso dell'encoder sbagliato o di un tipo di clip/condizionamento errato per FLUX.2 Klein 9B. Il modello riceve embedding della forma sbagliata, causando il fallimento della moltiplicazione delle matrici durante il campionamento.
Come risolvere
- Se costruisci grafici manualmente, verifica di utilizzare l'encoder di testo specifico per FLUX.2 Klein e che il tipo di clip/condizionamento corrisponda alle aspettative di FLUX.2 Klein.
- Per la soluzione più affidabile, esegui l'inferenza attraverso il wrapper di pipeline FLUX.2 Klein 9B di RunComfy (
model_type = flux2_klein_9b) e inietta il tuo LoRA tramitelora_path. Questo mantiene l'intero stack di inferenza—encoder, pianificatore e adattatore—allineato alla pipeline con le anteprime dell'AI Toolkit.
Esegui ora FLUX.2 Klein 9B LoRA ComfyUI Inferenza#
Carica il workflow, incolla il tuo lora_path, inserisci un valido hf_token, e lascia che Flux2Klein9BPipeline mantenga l'output ComfyUI allineato con le tue anteprime di addestramento dell'AI Toolkit.