






Flux Kontext Zoom Out LoRA | ComfyUI Workflow#
Questo flusso di lavoro ComfyUI crea una vista ingrandita pulita di qualsiasi immagine di input estendendo la tela e continuando naturalmente la scena, preservando la posizione e l'aspetto del soggetto. È costruito attorno a Flux Kontext e a un LoRA appositamente costruito in modo da poter "allontanare la telecamera" senza distorcere volti, texture o prospettiva. Se desideri un modo rapido e affidabile per ingrandire la cornice per miniature, foto di prodotti, ritratti o fotogrammi cinematografici, questo flusso di lavoro Flux Kontext Zoom Out LoRA fa per te.
Al suo core, il grafico carica un Flux Kontext UNet, applica il Flux Kontext Zoom Out LoRA, codifica la tua immagine in un riferimento latente e campiona una composizione più ampia guidata da un prompt esplicitamente progettato per l'integrità dello zoom-out. Il risultato è un'espansione senza soluzione di continuità che corrisponde all'illuminazione, stile e geometria originali.
Modelli chiave nel flusso di lavoro Comfyui Flux Kontext Zoom Out LoRA#
- Flux 1 Kontext UNet. Il backbone di diffusione utilizzato qui è una variante Flux 1 consapevole del Kontext preparata per ComfyUI (
flux1-dev-kontext_fp8_scaled.safetensors). Cattura la struttura a lungo raggio e il layout della scena necessari per un outpainting realistico. Pacchetto modello: Comfy-Org/flux1-kontext-dev_ComfyUI. - Flux Kontext Zoom Out LoRA. Un adattatore leggero che condiziona il modello per estendere i bordi in modo convincente mantenendo il soggetto visibile invariato. Repository: reverentelusarca/flux-kontext-zoom-out-lora.
- Dual text encoders for Flux. Il grafico utilizza encoder CLIP-L e T5-XXL sintonizzati per Flux per interpretare i prompt con alta fedeltà. Encoder di testo: comfyanonymous/flux_text_encoders.
- AE VAE. Un autoencoder veloce e di alta qualità utilizzato per i passaggi di codifica/decodifica (
ae.safetensors). Fonte: Comfy-Org/Lumina_Image_2.0_Repackaged.
Come usare il flusso di lavoro Comfyui Flux Kontext Zoom Out LoRA#
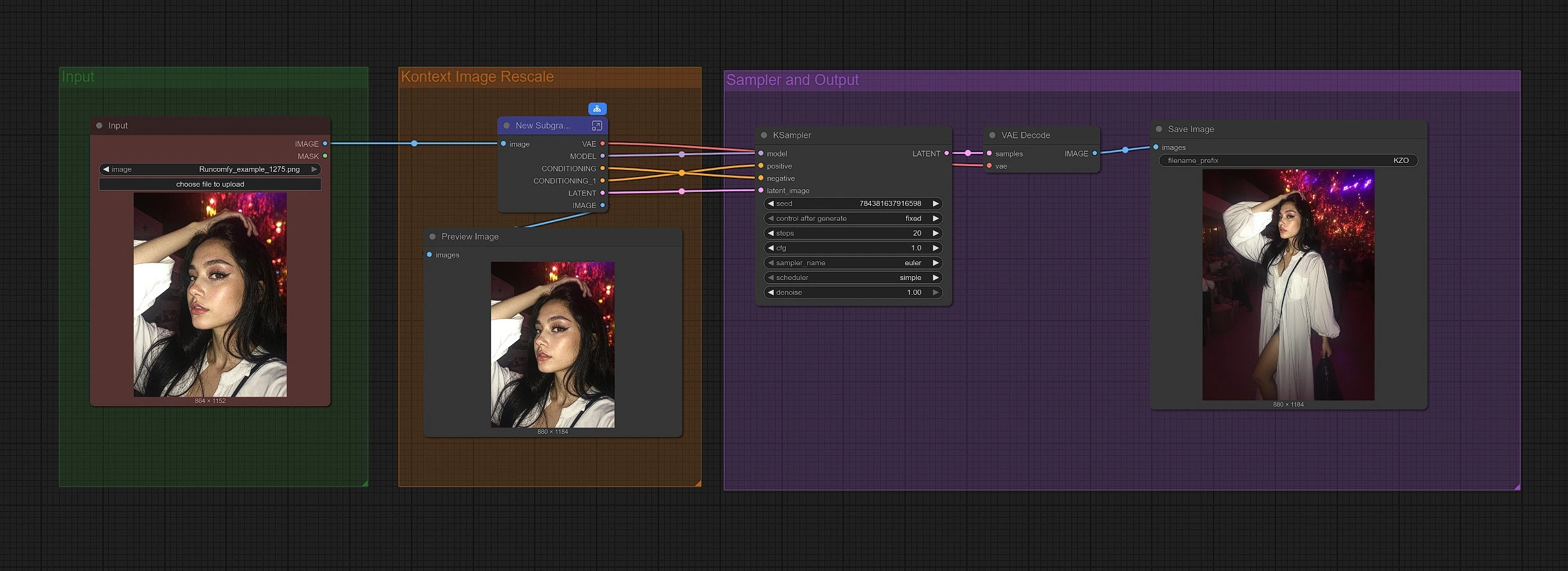
Questo flusso di lavoro è organizzato in tre gruppi. Inizia caricando la tua immagine, quindi il grafico la ridimensiona per il zoom-out Kontext, e infine il campionamento ricostruisce un quadro più ampio e salva il risultato.
Gruppo: Input#
Carica la tua immagine sorgente tramite LoadImage (#190). Il prompt positivo predefinito in CLIP Text Encode (Positive Prompt) (#6) è progettato per preservare il soggetto ed espandere la tela uniformemente in tutte le direzioni. Puoi mantenere quel prompt così com'è per zoom-out fedeli o adattarlo leggermente allo stile della tua scena. Il DualCLIPLoader (#38) è preconfigurato con CLIP-L e T5-XXL quindi il condizionamento del testo è pronto all'uso.
Gruppo: Kontext Image Rescale#
FluxKontextImageScale (#42) prepara l'immagine per lo zoom-out ridimensionando e aggiungendo padding in modo che i modelli Kontext gestiscano il tutto senza problemi. Questo passaggio di staging aiuta il modello a comprendere dove estendere il contenuto e come mantenere coerenza di prospettiva e illuminazione. L'immagine ridimensionata viene quindi codificata da VAEEncode (#124) in modo che il campionatore lavori da un latente che "ricorda" ancora l'inquadratura originale.
Gruppo: Sampler e Output#
Lo stack del modello è assemblato da UNETLoader (#37) e LoraLoaderModelOnly (#191), che applica il Flux Kontext Zoom Out LoRA al modello di base. ReferenceLatent (#177) utilizza la tua immagine codificata come ancoraggio strutturale in modo che il soggetto rimanga invariato mentre i bordi crescono. FluxGuidance (#35) modella quanto fortemente il riferimento influenza la generazione; valori più alti aumentano la fedeltà mentre valori più bassi consentono un riempimento leggermente più innovativo. KSampler (#31) esegue il passaggio di diffusione effettivo, e VAEDecode (#8), PreviewImage (#173) e SaveImage (#136) mostrano e salvano l'immagine finale ingrandita.
Nodi chiave nel flusso di lavoro Comfyui Flux Kontext Zoom Out LoRA#
FluxKontextImageScale (#42)#
Prepara l'input ridimensionando e incorniciando per un outpainting consapevole del contesto. Usalo come unico punto per modificare quanto tela vuoi aggiungere. Se hai bisogno di più spazio, aumenta la quantità di scala-out; se i bordi sembrano troppo nuovi, riducilo per mantenere più pixel originali.
LoraLoaderModelOnly (#191)#
Carica e applica kontext/zoomout-fal-v1.safetensors sul Flux 1 Kontext UNet. Se i tuoi output sembrano sotto o sovra-biasati, regola la forza del LoRA qui. Mantieni le modifiche modeste per preservare il comportamento previsto di Zoom Out LoRA.
ReferenceLatent (#177)#
Blocca la composizione e l'identità condizionando il campionatore sul VAE codificato originale. Se vedi un lieve spostamento nella posa o nella scala del soggetto, instrada il condizionamento attraverso questo nodo come fornito ed evita di rimuoverlo. Abbinare questo con un prompt neutro o minimo massimizza la fedeltà.
FluxGuidance (#35)#
Controlla quanto il riferimento e il prompt guidano il campionatore. Aumenta la guida quando le aree estese non corrispondono a illuminazione o prospettiva; diminuiscila se desideri un riempimento di sfondo leggermente più creativo. Trattalo come una manopola di bilanciamento tra stretta conservazione e continuazione organica.
Extra opzionali#
- Mantieni il prompt positivo minimale. Il prompt incluso è sintonizzato per questo Flux Kontext Zoom Out LoRA e di solito non necessita di modifiche.
- Se i bordi mostrano piccole cuciture, prova una scala-out più piccola in
FluxKontextImageScaleo unaFluxGuidanceleggermente più alta. - Per scene stilistiche, aggiungi 1-2 parole al prompt che descrivono il tono o il mezzo, non la forma del soggetto, per evitare di cambiare la figura principale.
- Salva varianti iterative cambiando solo il seme; questo ti permette di scegliere la continuazione più pulita senza alterare la composizione.
Riconoscimenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine reverentelusarca per Flux Kontext Zoom Out LoRA per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- reverentelusarca/Flux Kontext Zoom Out LoRA
- Hugging Face: Flux Kontext Zoom Out LoRA
Nota: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.


