
Animazione Controllabile nel Video AI: Workflow WanVideo + TTM Motion Control per ComfyUI#
Questo workflow di mickmumpitz porta l'Animazione Controllabile nel Video AI su ComfyUI utilizzando un approccio guidato dal movimento senza addestramento. Combina la diffusione da immagine a video di WanVideo con la guida latente Time-to-Move (TTM) e maschere consapevoli della regione per dirigere come i soggetti si muovono mantenendo identità, texture e continuità della scena.
Puoi iniziare da una base video o da due fotogrammi chiave, aggiungere maschere di regione che concentrano il movimento dove lo desideri e guidare le traiettorie senza alcuna messa a punto. Il risultato è un'Animazione Controllabile nel Video AI precisa e ripetibile, adatta per riprese dirette, sequenziamento del movimento degli oggetti e modifiche creative personalizzate.
Modelli chiave nel workflow Animazione Controllabile nel Video AI di Comfyui#
- Wan2.2 I2V A14B (HIGH/LOW). Il modello di diffusione da immagine a video di base che sintetizza il movimento e la coerenza temporale da prompt e riferimenti visivi. Due varianti bilanciano fedeltà (HIGH) e agilità (LOW) per diverse intensità di movimento. I file dei modelli sono ospitati nelle collezioni della comunità WanVideo su Hugging Face, ad esempio le distribuzioni WanVideo di Kijai. Link: Kijai/WanVideo_comfy_fp8_scaled, Kijai/WanVideo_comfy
- Lightx2v I2V LoRA. Un adattatore leggero che rafforza la struttura e la consistenza del movimento quando si compone l'Animazione Controllabile nel Video AI con Wan2.2. Aiuta a mantenere la geometria del soggetto sotto segnali di movimento più forti. Link: Kijai/WanVideo_comfy – Lightx2v LoRA
- Wan2.1 VAE. L'autoencoder video utilizzato per codificare i fotogrammi in latenti e decodificare gli output del campionatore in immagini senza sacrificare i dettagli. Link: Kijai/WanVideo_comfy – Wan2_1_VAE_bf16.safetensors
- UMT5‑XXL text encoder. Fornisce ricche incorporazioni di testo per il controllo guidato dal prompt insieme ai segnali di movimento. Link: google/umt5-xxl, Kijai/WanVideo_comfy – encoder weights
- Modelli Segment Anything per maschere video. SAM3 e SAM2 creano e propagano maschere di regione attraverso i fotogrammi, consentendo una guida dipendente dalla regione che affina l'Animazione Controllabile nel Video AI dove è importante. Link: facebook/sam3, facebook/sam2
- Qwen‑Image‑Edit 2509 (opzionale). Una base di modifica dell'immagine e una LoRA fulminea per una pulizia rapida dei fotogrammi di inizio/fine o la rimozione di oggetti prima dell'animazione. Link: QuantStack/Qwen‑Image‑Edit‑2509‑GGUF, lightx2v/Qwen‑Image‑Lightning, Comfy‑Org/Qwen‑Image_ComfyUI
- Guida Time‑to‑Move (TTM). Il workflow integra i latenti TTM per iniettare il controllo della traiettoria in modo senza addestramento per l'Animazione Controllabile nel Video AI. Link: time‑to‑move/TTM
Come usare il workflow Animazione Controllabile nel Video AI di Comfyui#
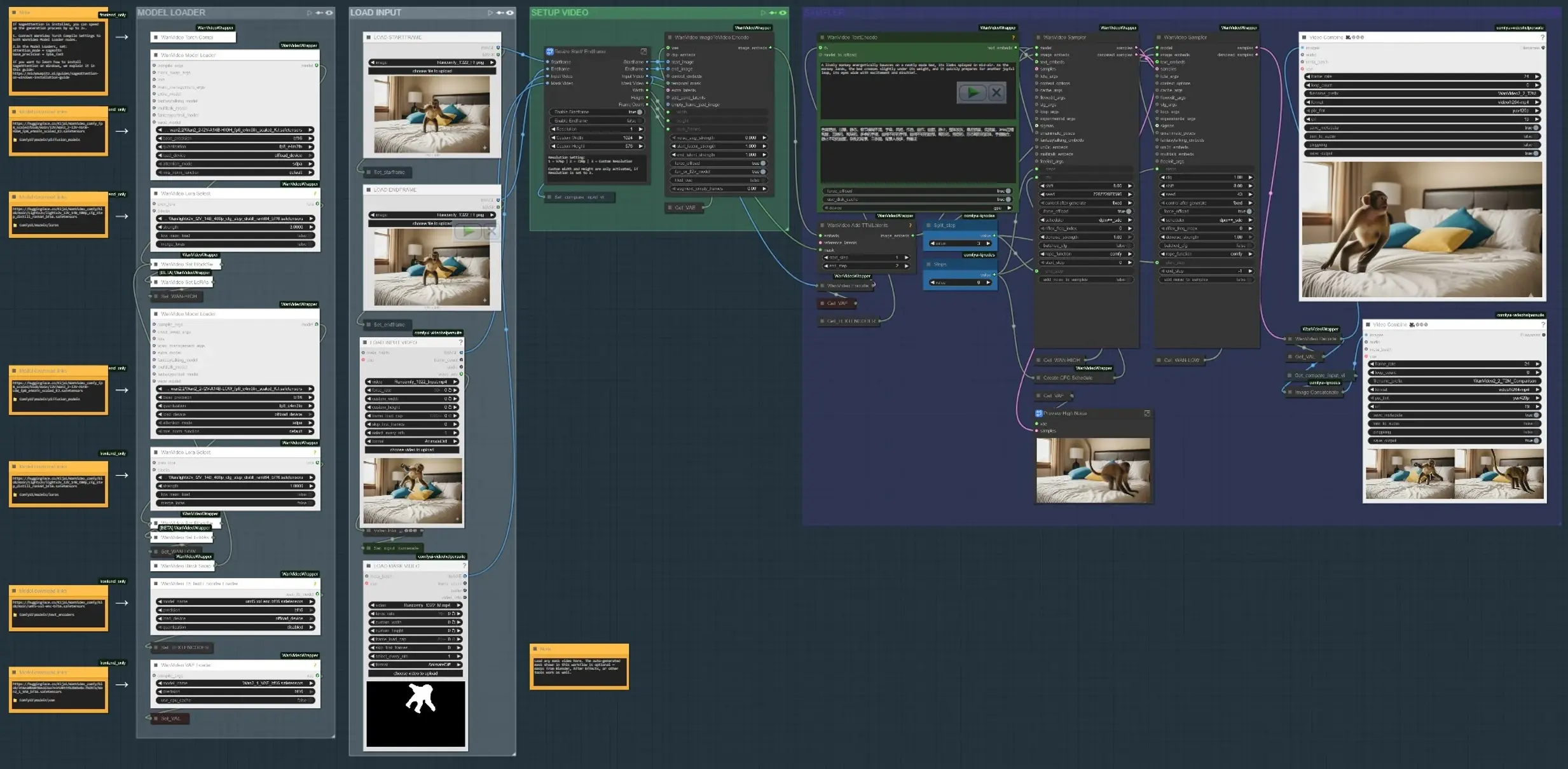
Il workflow si svolge in quattro fasi principali: caricare gli input, definire dove dovrebbe avvenire il movimento, codificare i segnali di testo e movimento, quindi sintetizzare e visualizzare l'anteprima del risultato. Ogni gruppo sotto mappa a una sezione etichettata nel grafico.
- CARICA INPUT Usa il gruppo “CARICA VIDEO INPUT” per portare una base o un clip di riferimento, o carica i fotogrammi di inizio e fine se stai costruendo il movimento tra due stati. Il sottografo “Ridimensiona Inizio/Finefotogramma” normalizza le dimensioni e consente opzionalmente il gating del fotogramma di inizio e fine. Un comparatore affiancato costruisce un output che mostra input rispetto al risultato per una rapida revisione (
VHS_VideoCombine(#613)). - CARICATORE DI MODELLI Il gruppo “CARICATORE DI MODELLI” configura Wan2.2 I2V (HIGH/LOW) e applica il Lightx2v LoRA. Un percorso di scambio di blocchi mescola varianti per un buon compromesso tra fedeltà e movimento prima del campionamento. Il Wan VAE viene caricato una volta e condiviso tra codifica/decodifica. La codifica del testo utilizza UMT5‑XXL per un forte condizionamento del prompt nell'Animazione Controllabile nel Video AI.
- MASCHERA SOGGETTO SAM3/SAM2 In “MASCHERA SOGGETTO SAM3” o “MASCHERA SOGGETTO SAM2”, clicca su un fotogramma di riferimento, aggiungi punti positivi e negativi, e propaga le maschere attraverso il clip. Questo produce maschere temporalmente consistenti che limitano le modifiche di movimento al soggetto o alla regione che scegli, consentendo una guida dipendente dalla regione. Puoi anche bypassare e caricare il tuo video maschera; le maschere da Blender/After Effects funzionano bene quando desideri un controllo disegnato dall'artista.
- PREPARAZIONE FOTOGRAMMA INIZIALE/FINALE (opzionale) I gruppi “FOTOGRAMMA INIZIALE – RIMOZIONE QWEN” e “FOTOGRAMMA FINALE – RIMOZIONE QWEN” forniscono un passaggio di pulizia opzionale su fotogrammi specifici utilizzando Qwen‑Image‑Edit. Usali per rimuovere impalcature, bastoni o artefatti di base che altrimenti inquinerebbero i segnali di movimento. L'inpainting ritaglia e cuce la modifica di nuovo nel fotogramma completo per una base pulita.
- CODIFICA TESTO + MOVIMENTO I prompt sono codificati con UMT5‑XXL in
WanVideoTextEncode(#605). Le immagini di fotogramma iniziale/finale sono trasformate in latenti video inWanVideoImageToVideoEncode(#89). I latenti di movimento TTM e una maschera temporale opzionale sono fusi tramiteWanVideoAddTTMLatents(#104) così che il campionatore riceva sia segnali semantici (testo) che di traiettoria, centrali per l'Animazione Controllabile nel Video AI. - CAMPIONATORE E ANTEPRIMA Il campionatore Wan (
WanVideoSampler(#27) eWanVideoSampler(#90)) denoizza i latenti utilizzando un setup a doppio orologio: un percorso governa la dinamica globale mentre l'altro preserva l'aspetto locale. I passaggi e un programma CFG configurabile modellano l'intensità del movimento rispetto alla fedeltà. Il risultato viene decodificato in fotogrammi e salvato come video; un output di confronto aiuta a giudicare se la tua Animazione Controllabile nel Video AI corrisponde al brief.
Nodi chiave nel workflow Animazione Controllabile nel Video AI di Comfyui#
WanVideoImageToVideoEncode(#89) Codifica le immagini di fotogramma iniziale/finale in latenti video che seminano la sintesi del movimento. Regola solo quando cambi la risoluzione di base o il conteggio dei fotogrammi; tienili allineati con il tuo input per evitare allungamenti. Se usi un video maschera, assicurati che le sue dimensioni corrispondano alla dimensione latente codificata.WanVideoAddTTMLatents(#104) Fonde i latenti di movimento TTM e le maschere temporali nel flusso di controllo. Attiva/disattiva l'input della maschera per limitare il movimento al tuo soggetto; lasciandolo vuoto applica il movimento a livello globale. Usa questo quando vuoi un'Animazione Controllabile nel Video AI specifica per la traiettoria senza influenzare lo sfondo.SAM3VideoSegmentation(#687) Raccogli alcuni punti positivi e negativi, scegli un fotogramma di riferimento, quindi propaga attraverso il clip. Usa l'output di visualizzazione per convalidare la deriva della maschera prima del campionamento. Per flussi di lavoro sensibili alla privacy o offline, passa al gruppo SAM2 che non richiede il gating del modello.WanVideoSampler(#27) Il denoiser che bilancia movimento e identità. Accoppia “Passaggi” con l'elenco del programma CFG per aumentare o rilassare la forza del movimento; una forza eccessiva può sopraffare l'aspetto, mentre troppo poca non fornisce abbastanza movimento. Quando le maschere sono attive, il campionatore concentra gli aggiornamenti all'interno della regione, migliorando la stabilità per l'Animazione Controllabile nel Video AI.
Extra opzionali#
- Per iterazioni rapide, inizia con il modello LOW Wan2.2, regola il movimento con TTM, quindi passa a HIGH per il passaggio finale per recuperare la texture.
- Usa video maschera disegnati dall'artista per silhouette complesse; il caricatore accetta maschere esterne e le ridimensiona per adattarsi.
- Gli switch “fotogramma iniziale/finale” ti permettono di bloccare visivamente il primo o l'ultimo fotogramma, utile per passaggi fluidi in modifiche più lunghe.
- Se disponibile nel tuo ambiente, abilitare l'attenzione ottimizzata (es. SageAttention) può accelerare significativamente il campionamento.
- Abbina il frame rate di output alla sorgente nel nodo di combinazione per evitare differenze di temporizzazione percepite nell'Animazione Controllabile nel Video AI.
Questo workflow offre un controllo del movimento consapevole della regione e senza addestramento combinando prompt di testo, latenti TTM e segmentazione robusta. Con pochi input mirati, puoi dirigere un'Animazione Controllabile nel Video AI sfumata e pronta per la produzione mantenendo i soggetti on-model e le scene coerenti.
Ringraziamenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine Mickmumpitz che è il creatore dell'Animazione Controllabile nel Video AI per il tutorial/post, e il team time-to-move per TTM per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati qui sotto.
Risorse#
- Patreon/Animazione Controllabile nel Video AI
- Documenti / Note di rilascio: Mickmumpitz Patreon post
- time-to-move/TTM
- GitHub: time-to-move/TTM
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.