
ComfyUI F5 TTS: sintesi vocale e clonazione vocale zero-shot in un unico workflow#
Questo workflow ComfyUI F5 TTS ti consente di generare discorsi naturali da testo e clonare voci direttamente all'interno di ComfyUI. È alimentato dai nodi personalizzati ComfyUI-F5-TTS e include un percorso completo per la clonazione basata su riferimento: fornisci un breve WAV più una trascrizione corrispondente per condizionare il modello, quindi sintetizza nuove linee che seguono il timbro e lo stile del relatore di riferimento. Il grafico include anche test pronti all'uso per varianti di modello, lingue e vocoder, così puoi confrontare rapidamente i risultati e decidere cosa si adatta meglio a narrazioni, voiceover, dialoghi di personaggi o demo di prodotti.
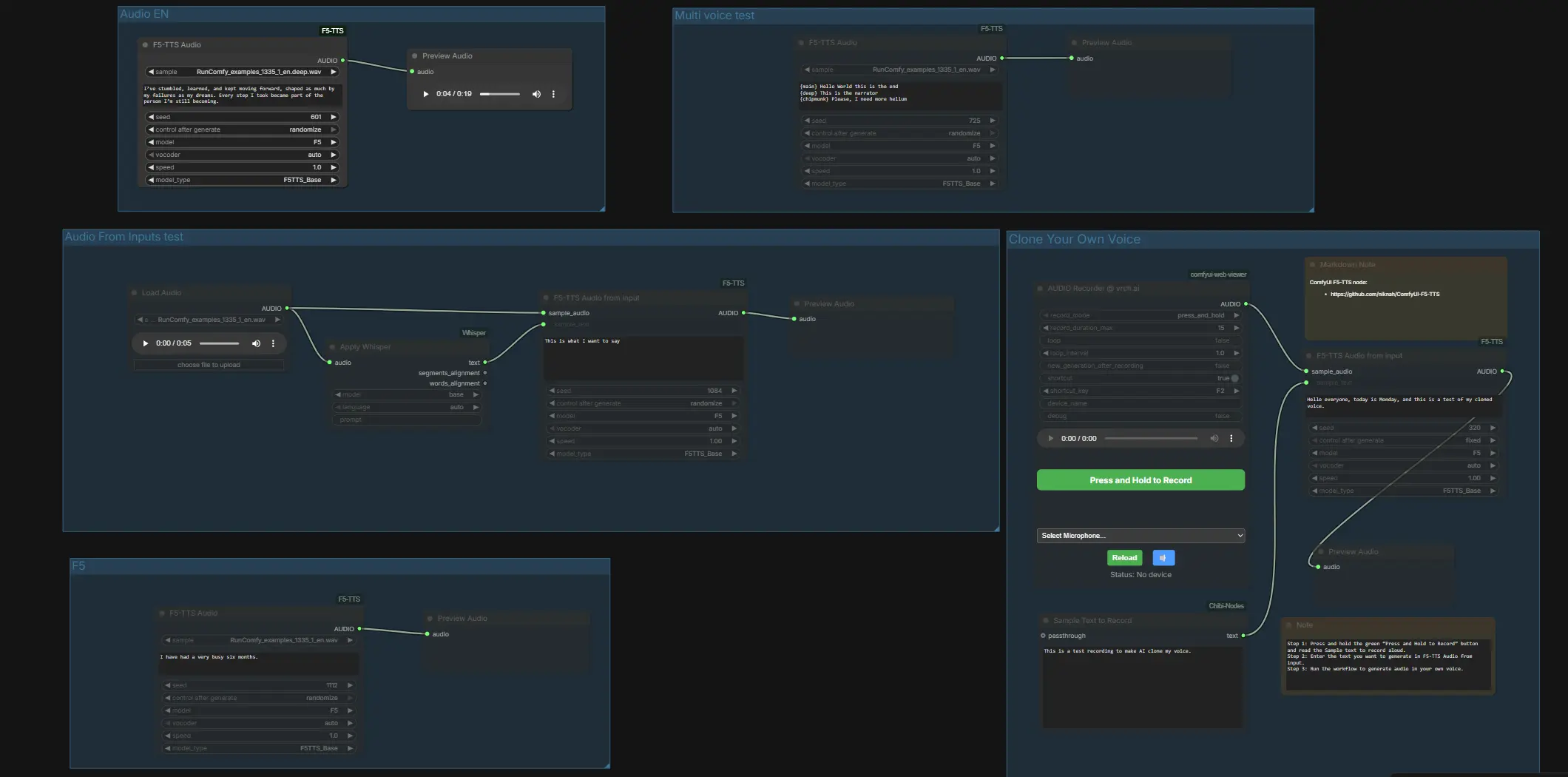
Tutto è organizzato in gruppi chiari, quindi puoi usare ComfyUI F5 TTS in due modi: TTS veloce e con un clic in Inglese, Francese, Tedesco e Giapponese, o clonazione vocale tramite un registratore integrato o file abbinati. È incluso un percorso di trascrizione compatto Whisper per aiutarti a ottenere una trascrizione del campione accurata quando hai già una registrazione pulita.
Modelli chiave nel workflow ComfyUI F5 TTS#
- Fish Audio F5-TTS. TTS zero-shot che apprende le caratteristiche di un relatore da un breve riferimento e produce discorsi di alta qualità in più lingue. Vedi il progetto per i dettagli del modello e il background del training. GitHub
- OpenAI Whisper. Riconoscimento vocale utilizzato qui per trascrivere automaticamente il tuo clip di riferimento in modo che il testo del campione corrisponda esattamente, migliorando la qualità della clonazione. GitHub
- BigVGAN. Un vocoder neurale ad alta fedeltà disponibile come opzione di decodifica per un'uscita più nitida e chiara. GitHub
- Vocos. Un'alternativa vocoder neurale veloce e leggera focalizzata su velocità e bassa latenza. GitHub
- Nodi personalizzati ComfyUI-F5-TTS. L'integrazione ComfyUI che collega F5-TTS e backend compatibili in nodi utilizzati in tutto questo grafico. GitHub
Come usare il workflow ComfyUI F5 TTS#
A livello generale, il workflow offre gruppi indipendenti per confronti rapidi tra modelli e un percorso dedicato alla clonazione. Inizia provando i gruppi preconfigurati per confermare la voce e il vocoder che preferisci, quindi passa alla clonazione con il tuo campione. Ogni sottosezione qui sotto spiega cosa fa il gruppo e i pochi input che contano.
Test Audio From Inputs#
Questo percorso dimostra la trascrizione di riferimento più il condizionamento. LoadAudio (#4) importa un WAV, Apply Whisper (#13) lo trascrive, e F5TTSAudioInputs (#26) utilizza sia l'audio di campione che il testo Whisper per condizionare la voce prima dell'anteprima. Fornisci un campione parlato pulito e lascia che Whisper riempia la porta della trascrizione in modo che la coppia corrisponda esattamente. Se vuoi fornire file direttamente, colloca un .wav e un .txt abbinati con lo stesso nome file in ComfyUI/input, quindi riavvia ComfyUI in modo che il grafico possa vederli.
Test Multi voice#
Questo gruppo mostra il passaggio stilistico all'interno di una singola linea usando un unico nodo di sintesi. F5TTSAudio (#17) legge uno script con segmenti etichettati, così puoi provare stili di personaggio multipli o cambiamenti di enfasi in un unico passaggio. È un modo rapido per sentire come ComfyUI F5 TTS gestisce timbri contrastanti o ritmo narratore-contro-personaggio.
Audio EN#
Usa F5TTSAudio (#15) per un TTS inglese semplice. Inserisci il tuo script e visualizza l'anteprima per valutare la pronuncia e il ritmo di base con il preset F5 predefinito. Questo percorso è ideale per iterazioni rapide prima di impegnarti nella clonazione o nel mixaggio multi-voce.
F5v1#
Questo percorso esegue il nodo F5TTSAudio (#33) contro la variante F5 v1 in modo da poter confrontare il tono e la prosodia con il preset F5 principale. Usa lo stesso testo del percorso EN per rendere facile giudicare le differenze. È utile quando si sceglie un modello predefinito per un progetto più lungo.
Audio FR#
Questo percorso è mirato alla sintesi francese con F5TTSAudio (#27) configurato per un preset francese. Fornisci uno script francese e visualizza l'anteprima dell'output per controllare le vocali nasali e la gestione del legamento. Passa avanti e indietro con il percorso EN per confrontare chiarezza e velocità.
Audio DE bigvgan#
Qui F5TTSAudio (#30) utilizza un preset tedesco e il vocoder BigVGAN per una decodifica più luminosa e nitida. Usa questo percorso quando desideri più presenza o una lucentezza da studio. Se preferisci una resa più morbida, confronta con un percorso Vocos.
Audio JP#
Questo percorso usa F5TTSAudio (#25) con un preset giapponese. Incolla uno script giapponese per valutare l'accento del tono e il timing delle mora. È un buon punto di partenza per letture in stile anime o linee di prodotti destinate a pubblici giapponesi.
Test E2#
Questo gruppo esercita F5TTSAudio (#29) con un preset compatibile E2 e il vocoder Vocos per provare un backend alternativo. Usalo per confrontare latenza e caratteristiche del timbro con le tue esecuzioni F5.
Clona la tua voce#
Registra, abbina e clona direttamente in ComfyUI. Premi il microfono in VrchAudioRecorderNode (#43) e leggi il prompt visualizzato nella casella "Sample Text to Record" Textbox (#42). Il registratore instrada il tuo WAV a F5TTSAudioInputs (#44) insieme al testo esatto che hai pronunciato, il che condiziona il modello sul tuo timbro e stile prima dell'anteprima in PreviewAudio (#45). Per risultati migliori, parla in una stanza tranquilla e assicurati che il testo di riferimento corrisponda esattamente a ciò che hai detto; quindi digita le nuove righe che vuoi che la voce clonata dica ed esegui il grafico.
Nodi chiave nel workflow ComfyUI F5 TTS#
F5TTSAudio (#15)#
Il nodo TTS a singolo passaggio principale utilizzato nei gruppi EN, FR, DE, JP, F5v1 ed E2. Fornisci il tuo script e scegli il preset del modello e il vocoder che si adattano alla tua lingua e consegna. Se vuoi esecuzioni riproducibili, mantieni il seme fisso; se vuoi varietà, randomizza tra le esecuzioni. L'implementazione è fornita dall'estensione ComfyUI-F5-TTS. GitHub GitHub - FishAudio/F5-TTS
F5TTSAudioInputs (#44)#
Il punto di ingresso della clonazione che consuma un WAV di riferimento e la sua trascrizione corrispondente per costruire una rappresentazione del relatore, quindi sintetizza nuove linee in quella voce. Usa un campione pulito con volume costante e assicurati che la trascrizione sia esatta per massimizzare la somiglianza e ridurre gli artefatti. Cambia i preset del modello o i vocoder qui se hai bisogno di una decodifica più luminosa o più neutrale. GitHub - FishAudio/F5-TTS
Apply Whisper (#13)#
Trascrizione automatica per il tuo campione di riferimento. Scegli una dimensione Whisper che bilanci velocità e precisione per il tuo hardware e lingua, quindi alimenta il suo testo di output al nodo di clonazione in modo che l'audio e il testo siano perfettamente allineati. Questo previene errori di condizionamento che possono verificarsi quando il testo del campione differisce da ciò che è stato effettivamente detto. GitHub
VrchAudioRecorderNode (#43)#
Un registratore in grafico che cattura un breve prompt parlato per la clonazione, eliminando la necessità di strumenti esterni. Tieni premuto per registrare, rilascia per fermare e ascolta immediatamente come suona ComfyUI F5 TTS con la tua voce. Tieni il microfono vicino e riduci il rumore della stanza per il risultato più pulito.
Extra opzionali#
- Usa da 5 a 15 secondi di discorso pulito per il riferimento, senza musica o effetti.
- Assicurati che la trascrizione del campione corrisponda esattamente alla registrazione; anche piccole discrepanze possono ridurre la fedeltà della clonazione.
- Confronta Vocos e BigVGAN sulla stessa linea per decidere tra velocità e dettaglio.
- Mantieni un seme fisso quando hai bisogno di riprese coerenti; randomizza quando esplori lo stile.
- Per progetti multilingue, prova prima i percorsi EN, FR, DE e JP, quindi finalizza la clonazione una volta che sei soddisfatto di pronuncia e ritmo.
Ringraziamenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine niknah per il nodo ComfyUI-F5-TTS, niknah per l'esempio di workflow F5TTS-test-all.json, e la comunità r/StableDiffusion per la guida "Voice Cloning with F5-TTS in ComfyUI" per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati qui sotto.
Risorse#
- niknah/ComfyUI-F5-TTS
- GitHub: niknah/ComfyUI-F5-TTS
- niknah/ComfyUI-F5-TTS (Example Workflow: F5TTS-test-all.json)
- r/StableDiffusion/Community Guide (Voice Cloning with F5-TTS in ComfyUI)
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.