








Flux de travail Z Image ControlNet pour la génération d'images guidée par la structure dans ComfyUI#
Ce flux de travail apporte Z Image ControlNet à ComfyUI pour que vous puissiez diriger Z‑Image Turbo avec une structure précise à partir d'images de référence. Il regroupe trois modes de guidage en un seul graphique : profondeur, contours canny et pose humaine, et vous permet de basculer entre eux pour s'adapter à votre tâche. Le résultat est une génération rapide et de haute qualité de texte ou d'image à image où la disposition, la pose et la composition restent sous contrôle pendant que vous itérez.
Conçu pour les artistes, les designers conceptuels et les planificateurs de disposition, le graphique prend en charge les invites bilingues et le style LoRA en option. Vous obtenez un aperçu clair du signal de contrôle choisi ainsi qu'une bande de comparaison automatique pour évaluer la profondeur, le canny ou la pose par rapport au résultat final.
Modèles clés dans le flux de travail Comfyui Z Image ControlNet#
- Modèle de diffusion Z‑Image Turbo 6B paramètres. Générateur principal qui produit rapidement des images photoréalistes à partir d'invites et de signaux de contrôle. alibaba-pai/Z-Image-Turbo
- Patch d'union Z Image ControlNet. Ajoute un contrôle multi-condition à Z‑Image Turbo et permet le guidage de profondeur, de contour et de pose en un seul patch de modèle. alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
- Depth Anything v2. Produit des cartes de profondeur denses utilisées pour le guidage de structure en mode profondeur. LiheYoung/Depth-Anything-V2 on GitHub
- DWPose. Estime les points clés humains et la pose corporelle pour une génération guidée par la pose. IDEA-Research/DWPose
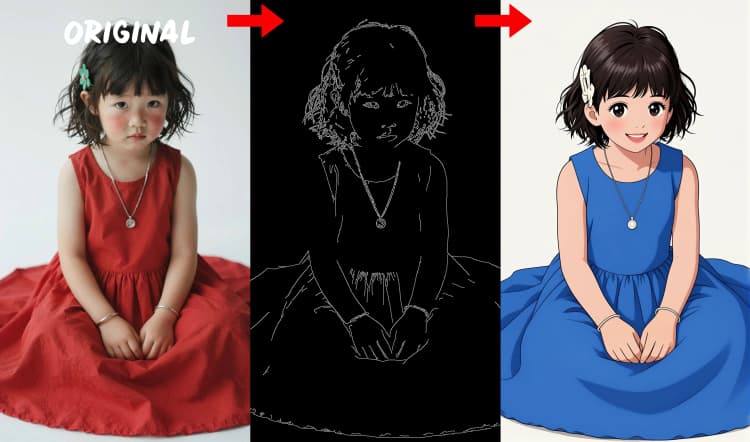
- Détecteur de contours Canny. Extrait des lignes d'art propres et des contours pour un contrôle guidé par la disposition.
- Préprocesseurs ControlNet Aux pour ComfyUI. Fournit des enveloppes unifiées pour la profondeur, les contours et la pose utilisées par ce graphique. comfyui_controlnet_aux
Comment utiliser le flux de travail Comfyui Z Image ControlNet#
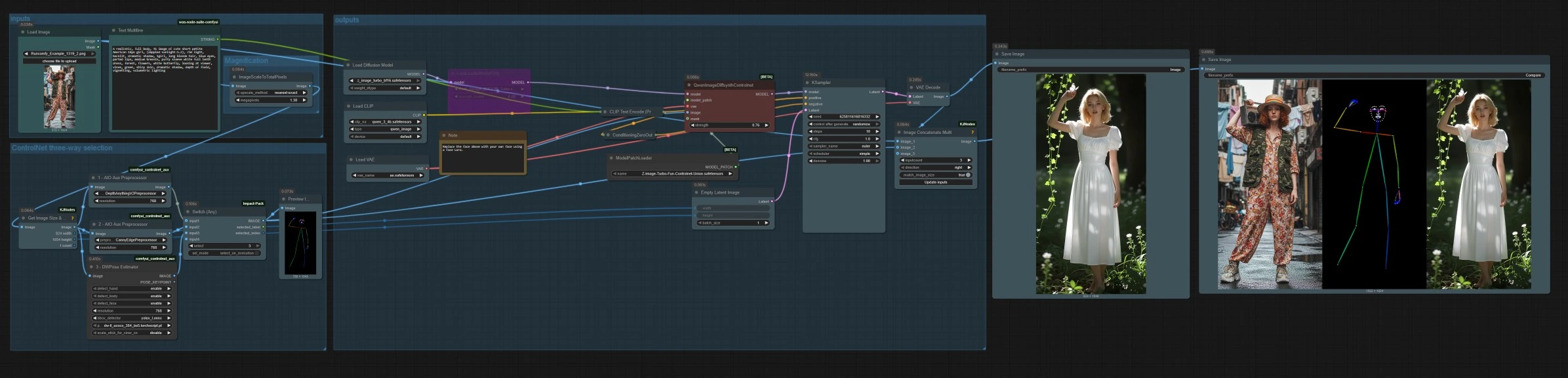
À un niveau élevé, vous chargez ou téléchargez une image de référence, sélectionnez un mode de contrôle parmi la profondeur, le canny ou la pose, puis générez avec une invite textuelle. Le graphique met à l'échelle la référence pour un échantillonnage efficace, construit un latent au rapport d'aspect correspondant, et enregistre à la fois l'image finale et une bande de comparaison côte à côte.
Entrées#
Utilisez LoadImage (#14) pour choisir une image de référence. Entrez votre invite textuelle dans Text Multiline (#17) la pile Z‑Image prend en charge les invites bilingues. L'invite est encodée par CLIPLoader (#2) et CLIPTextEncode (#4). Si vous préférez une image à image purement guidée par la structure, vous pouvez laisser l'invite minimale et vous fier au signal de contrôle sélectionné.
Sélection à trois voies ControlNet#
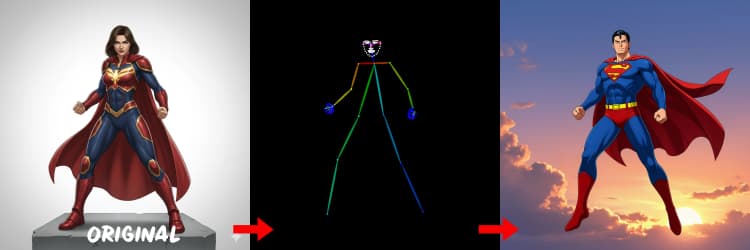
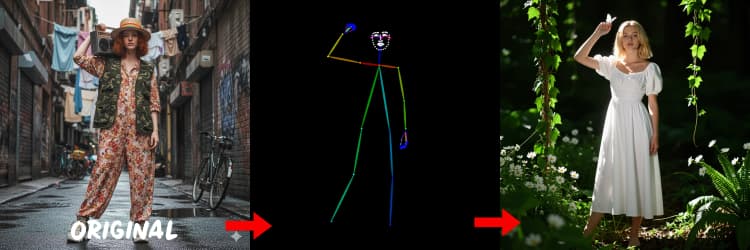
Trois préprocesseurs convertissent votre référence en signaux de contrôle. AIO_Preprocessor (#45) produit la profondeur avec Depth Anything v2, AIO_Preprocessor (#46) extrait les contours canny, et DWPreprocessor (#56) estime la pose corporelle complète. Utilisez ImpactSwitch (#58) pour sélectionner quel signal pilote Z Image ControlNet, et vérifiez PreviewImage (#43) pour confirmer la carte de contrôle choisie. Choisissez la profondeur lorsque vous voulez la géométrie de la scène, le canny pour une disposition nette ou des prises de vue de produit, et la pose pour le travail de personnage.
Conseils pour OpenPose : 1. Meilleur pour le corps entier : OpenPose fonctionne mieux (~70-90% de précision) lorsque vous incluez "corps entier" dans votre invite. 2. Évitez pour les gros plans : La précision diminue considérablement sur les visages. Utilisez Depth ou Canny (faible/moyenne force) pour les gros plans à la place. 3. L'invite est importante : Les invites influencent fortement ControlNet. Évitez les invites vides pour éviter des résultats brouillés.
Agrandissement#
ImageScaleToTotalPixels (#34) redimensionne la référence à une résolution de travail pratique pour équilibrer qualité et vitesse. GetImageSizeAndCount (#35) lit la taille mise à l'échelle et transmet la largeur et la hauteur vers l'avant. EmptyLatentImage (#6) crée une toile latente qui correspond à l'aspect de votre entrée redimensionnée pour que la composition reste cohérente.
Sorties#
QwenImageDiffsynthControlnet (#39) fusionne le modèle de base avec le patch d'union Z Image ControlNet et l'image de contrôle sélectionnée, puis KSampler (#7) génère le résultat guidé par votre conditionnement positif et négatif. VAEDecode (#8) convertit le latent en une image. Le flux de travail enregistre deux sorties SaveImage (#31) écrit l'image finale, et SaveImage (#42) écrit une bande de comparaison via ImageConcatMulti (#38) qui inclut la source, la carte de contrôle, et le résultat pour une QA rapide.
Nœuds clés dans le flux de travail Comfyui Z Image ControlNet#
ImpactSwitch (#58)#
Choisit quelle image de contrôle pilote la génération profondeur, canny ou pose. Changez de mode pour comparer comment chaque contrainte façonne la composition et le détail. Utilisez-le lors de l'itération de dispositions pour tester rapidement quel guidage convient le mieux à votre objectif.
QwenImageDiffsynthControlnet (#39)#
Fait le lien entre le modèle de base, le patch d'union Z Image ControlNet, le VAE et le signal de contrôle sélectionné. Le paramètre strength détermine à quel point le modèle suit strictement l'entrée de contrôle par rapport à l'invite. Pour un appariement de disposition serré, augmentez la force pour plus de variation créative, réduisez-la.
AIO_Preprocessor (#45)#
Exécute le pipeline Depth Anything v2 pour créer des cartes de profondeur denses. Augmentez la résolution pour une structure plus détaillée ou réduisez pour des aperçus plus rapides. Se marie bien avec les scènes architecturales, les prises de vue de produit et les paysages où la géométrie est importante.
DWPreprocessor (#56)#
Génère des cartes de pose adaptées aux personnes et aux personnages. Il fonctionne mieux lorsque les membres sont visibles et non fortement occultés. Si les mains ou les jambes manquent, essayez une référence plus claire ou un cadre différent avec une visibilité corporelle plus complète.
LoraLoaderModelOnly (#54)#
Applique un LoRA optionnel au modèle de base pour des indications de style ou d'identité. Ajustez strength_model pour mélanger le LoRA doucement ou fortement. Vous pouvez échanger un LoRA de visage pour personnaliser les sujets ou utiliser un LoRA de style pour verrouiller un look spécifique.
KSampler (#7)#
Effectue un échantillonnage de diffusion en utilisant votre invite et contrôle. Réglez seed pour la reproductibilité, steps pour le budget de raffinement, cfg pour l'adhérence à l'invite, et denoise pour combien la sortie peut s'écarter du latent initial. Pour les éditions image à image, réduisez le débruitage pour préserver la structure des valeurs plus élevées permettent des changements plus importants.
Extras optionnels#
- Pour resserrer la composition, utilisez le mode profondeur avec une référence propre et uniformément éclairée, le canny favorise un contraste fort, et la pose favorise les prises de vue de corps entier.
- Pour des modifications subtiles à partir d'une image source, gardez le débruitage modeste et augmentez la force de ControlNet pour une structure fidèle.
- Augmentez les pixels cibles dans le groupe d'agrandissement lorsque vous avez besoin de plus de détails, puis réduisez à nouveau pour des brouillons rapides.
- Utilisez la sortie de comparaison pour tester rapidement A/B profondeur vs canny vs pose et choisissez le contrôle le plus fiable pour votre sujet.
- Remplacez le LoRA d'exemple par votre propre LoRA de visage ou de style pour incorporer l'identité ou la direction artistique sans réentraînement.
Remerciements#
Ce flux de travail implémente et s'appuie sur les travaux et ressources suivants. Nous remercions sincèrement Alibaba PAI pour Z Image ControlNet pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Ressources#
- Alibaba PAI/Z Image ControlNet
- Hugging Face: alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.

