
Génération de vidéo basée sur la pose Wan 2.2 VACE pour ComfyUI#
Ce flux de travail ComfyUI Wan 2.2 VACE transforme une seule image de référence en une vidéo assortie au mouvement qui suit la pose, le rythme et le mouvement de la caméra d'un clip source. Il utilise Wan 2.2 VACE pour préserver l'identité tout en traduisant un mouvement corporel complexe en une animation fluide et réaliste.
Conçu pour la génération de danse, le transfert de mouvement et l'animation créative de personnages, le flux de travail automatise l'incitation de style à partir de l'image de référence, extrait les signaux de mouvement de la vidéo source et exécute un échantillonneur Wan 2.2 en deux étapes qui équilibre la cohérence du mouvement et le détail fin.
Modèles clés dans le flux de travail Comfyui Wan 2.2 VACE#
- Modèles Texte-à-Vidéo Wan 2.2 14B (variantes à haut bruit et à faible bruit). Les deux étapes utilisent une base à haut bruit pour façonner le mouvement de manière robuste, suivie d'une base à faible bruit pour le raffinement des détails.
- Wan 2.1 VAE (bf16). Décode et encode des images vidéo latentes pour Wan 2.2 VACE.
- Google UMT5-XXL Encoder. Fournit des caractéristiques textuelles de haute capacité utilisées par Wan 2.2 pour le conditionnement. Model card
- Microsoft Florence-2 (Flux Large). Génère une légende riche à partir de l'image de référence pour amorcer et styliser l'incitation. Repo
- Depth Anything v2 (ViT-L). Produit des cartes de profondeur par image à partir de la vidéo source de mouvement pour guider la structure et le mouvement. Repo
Comment utiliser le flux de travail Comfyui Wan 2.2 VACE#
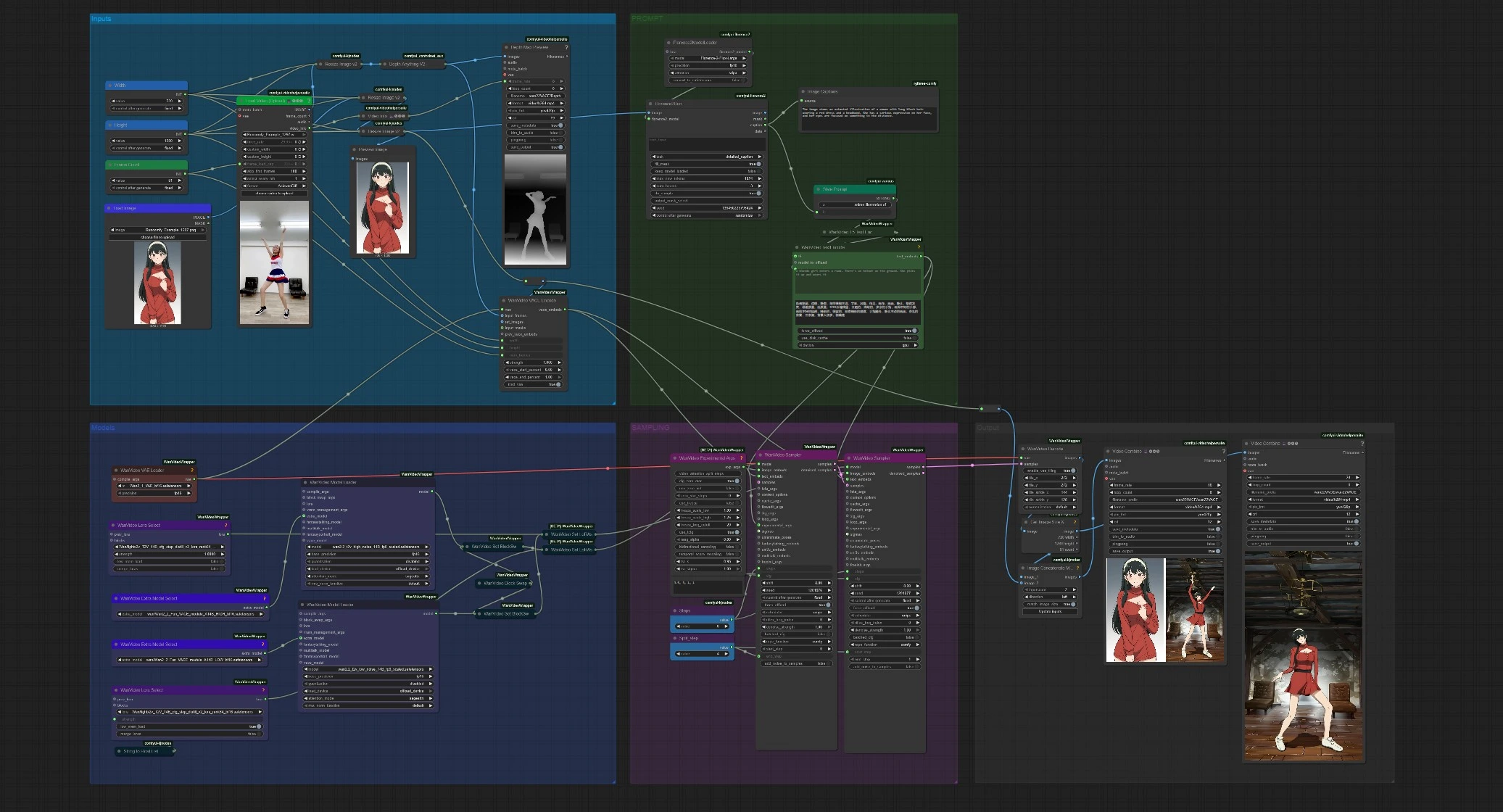
Le flux de travail a cinq étapes groupées: Entrées, INCITATION, Modèles, ÉCHANTILLONNAGE et Sortie. Vous fournissez une image de référence et une courte vidéo de mouvement. Le graphe calcule ensuite la guidance de mouvement, encode les caractéristiques d'identité VACE, exécute un échantillonneur Wan 2.2 en deux passes, et enregistre à la fois l'animation finale et un aperçu optionnel côte à côte.
Entrées#
Chargez un clip source de mouvement dans VHS_LoadVideo (#141). Vous pouvez découper avec des contrôles simples et limiter les images pour la mémoire. Les images sont redimensionnées pour la cohérence, puis DepthAnythingV2Preprocessor (#135) calcule une séquence de profondeur dense qui capture la pose, la disposition et le mouvement de la caméra. Chargez votre image d'identité avec LoadImage (#113); elle est redimensionnée automatiquement et prévisualisée afin que vous puissiez vérifier le cadrage avant l'échantillonnage.
INCITATION#
Florence2Run (#137) analyse l'image de référence et renvoie une légende détaillée. Style Prompt (#138) concatène cette légende avec une courte phrase de style, puis WanVideoTextEncode (#16) encode les incitations positives et négatives finales en utilisant UMT5-XXL. Vous pouvez librement éditer la phrase de style ou remplacer entièrement l'incitation positive si vous souhaitez une direction créative plus forte. Cette intégration d'incitation conditionne les deux étapes de l'échantillonneur afin que la vidéo générée reste fidèle à votre référence.
Modèles#
WanVideoVAELoader (#38) charge le VAE Wan utilisé pour l'encodage/décodage. Deux nœuds WanVideoModelLoader préparent les modèles Wan 2.2 14B: un à haut bruit et un à faible bruit, chacun augmenté avec un module VACE sélectionné dans WanVideoExtraModelSelect (#99, #107). Un raffinement LoRA optionnel est attaché via WanVideoLoraSelect (#56, #97), vous permettant d'ajuster la netteté ou le style sans changer les modèles de base. La configuration est conçue pour que vous puissiez échanger les poids VACE, LoRA, ou la variante de bruit sans toucher le reste du graphe.
ÉCHANTILLONNAGE#
WanVideoVACEEncode (#100) fusionne trois signaux en intégrations VACE: la séquence de mouvement (images de profondeur), votre image de référence, et la géométrie vidéo cible. Le premier WanVideoSampler (#27) exécute le modèle à haut bruit jusqu'à une étape de division pour établir le mouvement, la perspective et le style global. Le second WanVideoSampler (#90) reprend à partir de ce latent et termine avec le modèle à faible bruit pour récupérer les textures, les contours, et les petits détails tout en maintenant le mouvement verrouillé sur la source. Un court programme CFG et une division d'étape contrôlent combien chaque étape influence le résultat.
Sortie#
WanVideoDecode (#28) convertit le latent final en images. Vous obtenez deux vidéos enregistrées: un rendu propre et une concaténation côte à côte qui place les images générées à côté de la référence pour une QA rapide. Un aperçu séparé de la "Carte de Profondeur" montre la séquence de profondeur inférée afin que vous puissiez diagnostiquer la guidance de mouvement d'un coup d'œil. Les paramètres de cadence et de nom de fichier sont disponibles dans les sorties VHS_VideoCombine (#139, #60, #144).
Nœuds clés dans le flux de travail Comfyui Wan 2.2 VACE#
WanVideoVACEEncode (#100)#
Crée les intégrations d'identité et de géométrie VACE utilisées par les deux échantillonneurs. Fournissez vos images de mouvement et l'image de référence; le nœud gère la largeur, la hauteur, et le nombre d'images. Si vous changez la durée ou le format, gardez ce nœud synchronisé pour que les intégrations correspondent à la disposition de votre vidéo cible.
WanVideoSampler (#27)#
Échantillonneur de première étape utilisant le modèle Wan 2.2 à haut bruit. Ajustez steps, un court programme cfg, et la division end_step pour décider combien de la trajectoire est allouée à la formation du mouvement. Les mouvements ou changements de caméra plus importants bénéficient d'une division légèrement plus tardive.
WanVideoSampler (#90)#
Échantillonneur de deuxième étape utilisant le modèle Wan 2.2 à faible bruit. Réglez start_step à la même valeur de division pour qu'il continue sans interruption de la première étape. Si vous voyez un suraffûtage des textures ou une dérive, réduisez les valeurs cfg ultérieures ou diminuez la force de LoRA.
DepthAnythingV2Preprocessor (#135)#
Extrait une séquence de profondeur stable de la vidéo source. Utiliser la profondeur comme guidance de mouvement aide Wan 2.2 VACE à conserver la disposition de la scène, la pose de la main, et l'occlusion. Pour une itération rapide, vous pouvez réduire la taille des images d'entrée; pour les rendus finaux, utilisez des images de plus haute résolution pour une meilleure fidélité structurelle.
WanVideoTextEncode (#16)#
Encode les incitations positives et négatives avec UMT5-XXL. L'incitation est auto-construite à partir de Florence2Run, mais vous pouvez la remplacer pour la direction artistique. Gardez les incitations concises; avec la guidance d'identité VACE, moins de mots-clés donnent souvent un transfert de mouvement plus propre et moins contraint.
Extras optionnels#
- Choisissez des clips de mouvement avec une séparation claire du sujet et un éclairage cohérent pour les transferts Wan 2.2 VACE les plus stables.
- Utilisez la sortie côte à côte pour vérifier l'alignement du visage et la continuité de la tenue avant de rendre une passe finale.
- Si le mouvement semble trop rigide, déplacez la division un peu plus tôt pour que l'étape à faible bruit ait plus de place pour affiner.
- Si l'identité dérive, augmentez légèrement l'influence de LoRA ou simplifiez l'incitation.
- L'aperçu de la profondeur est votre ami: si la profondeur est bruyante, essayez un autre clip source ou ajustez le redimensionnement de l'entrée pour réduire les artefacts.
Remerciements#
Ce flux de travail implémente et se base sur les travaux et ressources suivants. Nous remercions chaleureusement les créateurs de la communauté ComfyUI de Wan 2.2 VACE Source pour le flux de travail, pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Wan 2.2 VACE Source/Wan 2.2 VACE Source
- Docs / Notes de version: Wan 2.2 VACE @ComfyUI
Note: L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et termes respectifs fournis par leurs auteurs et mainteneurs.