
SDXL LoRA Inférence: Exécutez AI Toolkit LoRA dans ComfyUI pour des Résultats Correspondants à l'Entraînement#
SDXL LoRA Inférence: résultats correspondant à l'entraînement avec moins d'étapes dans ComfyUI. Ce workflow exécute Stable Diffusion XL (SDXL) avec AI Toolkit–trained LoRAs via le nœud personnalisé RC SDXL (RCSDXL) de RunComfy (open‑sourced dans les dépôts de l'organisation GitHub runcomfy-com). En encapsulant un pipeline spécifique à SDXL (au lieu d'un graphe d'échantillonneur générique) et en standardisant le chargement et le calibrage LoRA (lora_path / lora_scale) avec des paramètres par défaut corrects pour SDXL, vos sorties ComfyUI restent beaucoup plus proches de ce que vous avez vu dans les prévisualisations d'entraînement.
Si vous avez formé un SDXL LoRA dans AI Toolkit (RunComfy Trainer ou ailleurs) et que vos résultats ComfyUI semblent "décalés" par rapport aux prévisualisations d'entraînement, ce workflow est le moyen le plus rapide de revenir à un comportement correspondant à l'entraînement.
Comment utiliser le workflow SDXL LoRA Inférence#
Étape 1: Ouvrir le workflow#
Ouvrez le workflow SDXL LoRA Inférence de RunComfy
Étape 2: Importez votre LoRA (2 options)#
- Option A (résultat d'entraînement RunComfy): RunComfy → Trainer → LoRA Assets → trouvez votre LoRA → ⋮ → Copier le lien LoRA

- Option B (AI Toolkit LoRA formé en dehors de RunComfy): Copiez un lien de téléchargement direct
.safetensorspour votre LoRA et collez cette URL danslora_path.
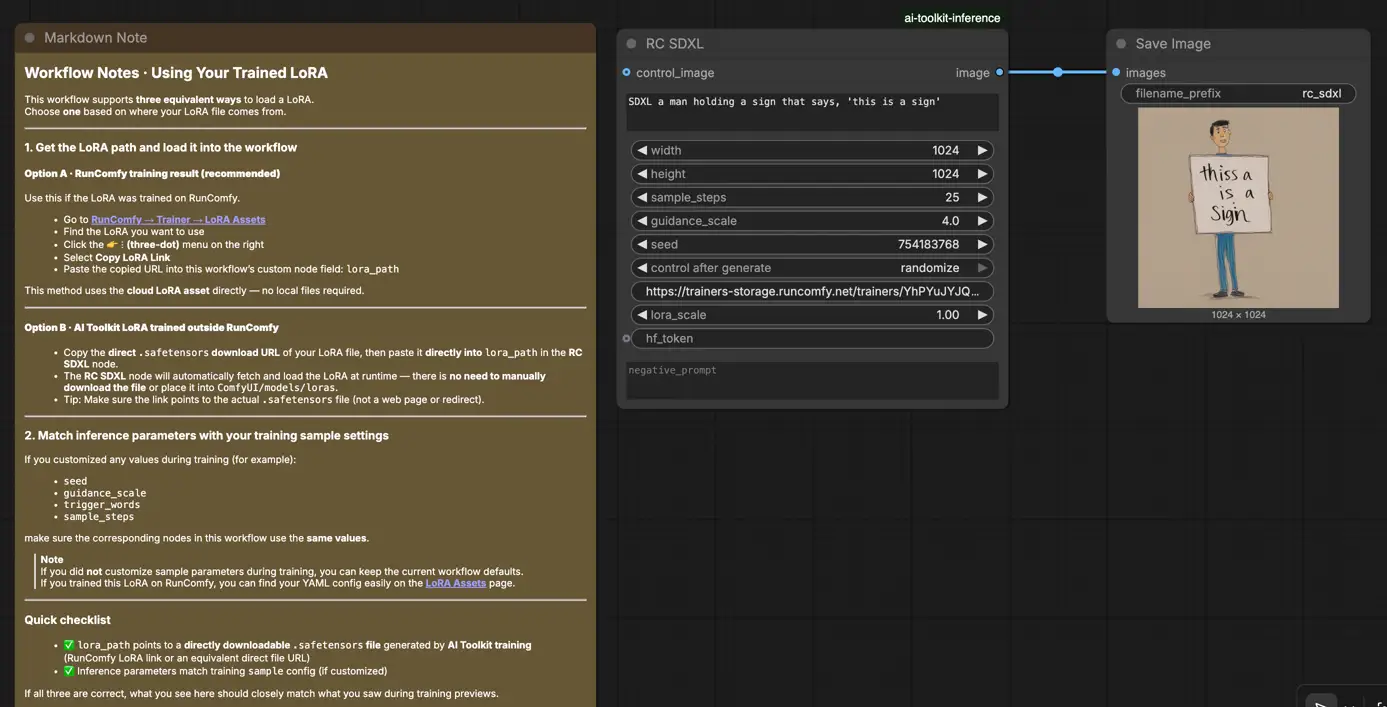
Étape 3: Configurez RCSDXL pour SDXL LoRA Inférence#
Dans l'interface utilisateur du nœud SDXL LoRA Inférence de RCSDXL, définissez les paramètres restants:
prompt: votre texte d'invite principal (incluez tous les jetons déclencheurs que vous avez utilisés pendant l'entraînement)negative_prompt: optionnel; laissez vide si vous n'avez pas utilisé dans les prévisualisations d'entraînementwidth/height: résolution de sortiesample_steps: étapes d'échantillonnage (faites correspondre vos paramètres de prévisualisation d'entraînement lors de la comparaison des résultats)guidance_scale: CFG / guidance (faites correspondre le CFG de prévisualisation d'entraînement)seed: utilisez une graine fixe pour la reproductibilité; changez-la pour explorer des variationslora_scale: force/intensité de LoRA
Si vous avez ajusté l'échantillonnage pendant l'entraînement, ouvrez le YAML d'entraînement AI Toolkit et copiez les mêmes valeurs ici—en particulier width, height, sample_steps, guidance_scale, et seed. Si vous avez formé sur RunComfy, vous pouvez également ouvrir le Config de LoRA dans Trainer → LoRA Assets et copier les valeurs de prévisualisation/échantillonnage.

Étape 4: Exécutez SDXL LoRA Inférence#
- Cliquez sur Queue/Run → la sortie est enregistrée automatiquement via SaveImage
Pourquoi SDXL LoRA Inférence semble souvent différente dans ComfyUI & Ce que fait le nœud personnalisé RCSDXL#
La plupart des décalages SDXL LoRA ne sont pas causés par un mauvais réglage—ils se produisent parce que le pipeline d'inférence change. Les prévisualisations d'entraînement AI Toolkit sont générées via une implémentation d'inférence spécifique au modèle SDXL, tandis que de nombreux graphes ComfyUI sont reconstruits à partir de composants génériques. Même avec la même invite, les mêmes étapes, CFG, et graine, un pipeline différent (et un chemin d'injection LoRA différent) peut produire des résultats sensiblement différents.
Le nœud RC SDXL (RCSDXL) encapsule un pipeline d'inférence spécifique à SDXL afin que SDXL LoRA Inférence reste aligné avec le pipeline de prévisualisation d'entraînement AI Toolkit et utilise un comportement d'injection LoRA cohérent pour SDXL. Implémentation de référence: `src/pipelines/sdxl.py`
Dépannage SDXL LoRA Inférence#
La plupart des problèmes de "prévisualisation d'entraînement vs inférence ComfyUI" proviennent des décalages de pipeline, pas d'un seul paramètre incorrect. Si votre LoRA a été formé avec AI Toolkit (SDXL), la manière la plus fiable de retrouver un comportement correspondant à l'entraînement dans ComfyUI est d'exécuter l'inférence via le nœud personnalisé RCSDXL de RunComfy, qui aligne l'échantillonnage SDXL + l'injection LoRA au niveau du pipeline.
(1) Inférence sur les fichiers lora .safetensor du modèle sdxl ne correspond pas aux échantillons de l'entraînement#
Pourquoi cela arrive
Même lorsque le LoRA se charge, les résultats peuvent encore dériver si votre graphe ComfyUI ne correspond pas au pipeline de prévisualisation d'entraînement (différents paramètres par défaut SDXL, chemin d'injection LoRA différent, gestion de raffinement différente).
Comment réparer (recommandé)
- Utilisez RCSDXL et collez votre lien direct
.safetensorsdanslora_path. - Copiez les valeurs d'échantillonnage de votre config d'entraînement AI Toolkit (ou Config Trainer → LoRA Assets de RunComfy):
width,height,sample_steps,guidance_scale,seed. - Gardez les "piles de vitesse supplémentaires" (LCM/Lightning/Turbo) en dehors de la comparaison à moins que vous n'ayez formé/échantillonné avec elles.
(2) Clé SDXL lora non chargée "lora_te2_text_projection.*"#
Pourquoi cela arrive
Votre LoRA contient des clés de projection Text Encoder 2 SDXL que votre chemin de chargement actuel n'applique pas (facile à atteindre lorsque l'injection/la cartographie des clés ne correspond pas à la configuration à double encodeur de SDXL).
Comment réparer (le plus fiable)
- Utilisez RCSDXL et chargez le LoRA via
lora_pathà l'intérieur du nœud (injection au niveau du pipeline). - Gardez
lora_scalecohérent, et incluez les mêmes jetons déclencheurs utilisés pendant l'entraînement. - Si les avertissements persistent, essayez le checkpoint de base exact utilisé pendant l'entraînement (les variantes SDXL mal assorties peuvent produire des clés manquantes/ignorées).
(3) Impossible d'utiliser LoRAs avec SDXL maintenant#
Pourquoi cela arrive
Après la mise à jour de ComfyUI / nœuds personnalisés, l'application SDXL LoRA peut changer (comportement du chargeur, mise en cache, comportement mémoire), rendant les graphes précédemment fonctionnels défaillants ou décalés.
Comment réparer (recommandé)
- Utilisez RCSDXL pour maintenir le chemin d'inférence SDXL stable et aligné sur l'entraînement.
- Effacez le cache du modèle/nœud ou redémarrez la session après les mises à jour (surtout si le comportement change uniquement après avoir modifié les paramètres LoRA/chargeur).
- Pour le débogage, exécutez d'abord un workflow SDXL de base uniquement, puis ajoutez de la complexité.
(4) Hook de Planification LoRA cache CLIP incorrect dans l'exécution suivante après un changement de valeur#
Pourquoi cela arrive
Les workflows de hook/planification peuvent réutiliser l'état de cache CLIP après des changements de paramètres, ce qui brise la reproductibilité et rend le comportement LoRA incohérent d'une exécution à l'autre.
Comment réparer (recommandé)
- Pour une inférence correspondant à l'entraînement, préférez RCSDXL avec un
lora_path/lora_scalesimple d'abord (évitez les couches de hook/planification jusqu'à ce que la ligne de base corresponde). - Si vous devez utiliser des nœuds de hook/planification, videz le cache (ou redémarrez) après avoir modifié les paramètres de hook, puis relancez avec la même graine.
(5) Erreur Ksampler lors de l'utilisation de LORA dans l'inpainting SDXL#
Pourquoi cela arrive
Les piles d'inpainting modifient le modèle pendant l'échantillonnage. Certains nœuds personnalisés / wrappers d'assistance peuvent entrer en conflit avec le patching LoRA lorsque vous modifiez les paramètres en cours de session, déclenchant des erreurs KSampler/inpaint worker.
Comment réparer (recommandé)
- Confirmez que le LoRA fonctionne dans RCSDXL dans un workflow txt2img simple d'abord (ligne de base au niveau du pipeline).
- Ajoutez l'inpainting un composant à la fois. Si l'erreur apparaît seulement après des modifications, redémarrez/effacez le cache avant de relancer.
- Si le problème ne survient qu'avec un nœud d'assistance spécifique, essayez le chemin d'inpainting classique ou mettez à jour/désactivez le nœud personnalisé en conflit.
(6) Je reçois cette erreur clip manquant: ['clip_l.logit_scale', 'clip_l.transformer.text_projection.weight']#
Pourquoi cela arrive
Cela signifie généralement que les actifs CLIP/text-encoder chargés ne correspondent pas au checkpoint SDXL que vous exécutez (poids CLIP SDXL attendus manquants), ce qui peut également rendre le comportement LoRA "décalé".
Comment réparer (recommandé)
- Assurez-vous que vous utilisez une configuration de checkpoint SDXL appropriée avec des encodeurs de texte SDXL/CLIP corrects.
- Ensuite, exécutez l'inférence LoRA via RCSDXL afin que le chemin de conditionnement SDXL reste cohérent de bout en bout.
Exécutez maintenant SDXL LoRA Inférence#
Ouvrez le workflow SDXL LoRA Inférence de RunComfy, collez votre LoRA dans lora_path, et exécutez RCSDXL pour une inférence SDXL LoRA correspondant à l'entraînement dans ComfyUI.