
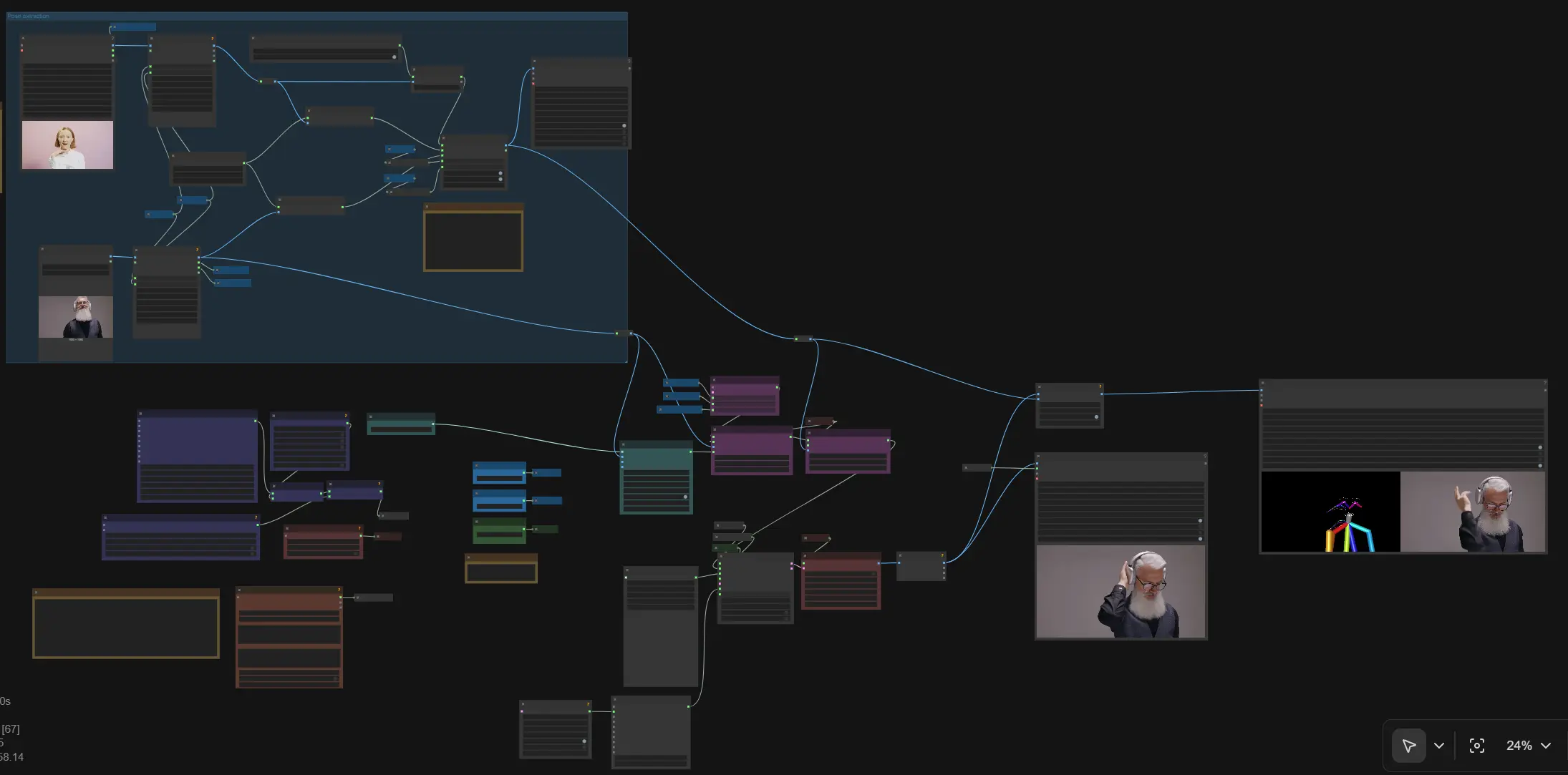
Animation de personnage guidée par la pose SCAIL dans ComfyUI#
Ce flux de travail apporte SCAIL à ComfyUI pour l'animation de personnage guidée par la pose et basée sur des références. En combinant une seule image de référence avec des poses humaines extraites, SCAIL maintient l'identité du sujet, la structure corporelle et un mouvement cohérent à travers les cadres tout en vous permettant de contrôler le style avec des invites. Il prend en charge soit une vidéo d'entrée pour le transfert de mouvement, soit des images plus des poses rendues pour la chorégraphie, puis produit des vidéos multi-cadres avec un passage audio optionnel.
Utilisez ce flux de travail SCAIL pour le transfert de mouvement de danse et d'action, l'animation de personnage stylisée et des séquences multi-plans cohérentes où la stabilité temporelle et les poses précises comptent. Sous le capot, il fonctionne sur WanVideo pour la génération vidéo par transformateur de diffusion, augmente l'identité via CLIP vision, et conduit la structure avec les signaux de pose NLF et ViTPose/DWPose, tous câblés pour un échantillonnage efficace de longues séquences.
Remarque : En raison des limitations de compatibilité, la machine 2XL ne peut pas être utilisée avec le flux de travail ComfyUI actuel.
Modèles clés dans le flux de travail Comfyui SCAIL#
- SCAIL : Animation de personnage de qualité studio via une injection de pose en plein contexte et une représentation de pose 3D cohérente; au cœur de la préservation de l'identité et de la fidélité de la pose de ce flux de travail. GitHub, arXiv
- Wan 2.x Image-à-Vidéo : grands modèles de diffusion vidéo utilisés ici comme colonne vertébrale de l'échantillonneur pour la génération conditionnée par SCAIL; prend en charge des tâches I2V de haute qualité et d'animation. Exemples : Wan-AI/Wan2.1-I2V-14B-480P, Wan-AI/Wan2.2-Animate-14B
- UMT5-XXL encodeur de texte : variante multilingue de T5 utilisée par les pipelines Wan pour transformer les invites en embeddings de conditionnement. Hugging Face
- CLIP ViT-H/14 encodeur de vision : extrait des caractéristiques d'image de référence robustes pour ancrer l'identité pendant la synthèse vidéo. GitHub
- ViTPose (Corps entier) : estimateur de pose humaine 2D de haute qualité qui fournit des points clés denses pour le corps, les mains et le visage utilisés par les utilitaires d'alignement et de dessin de SCAIL. GitHub
- DWPose : format et modèles de points clés pour tout le corps utilisés pour un détail optionnel du visage/des mains et l'alignement des poses. GitHub
- NLF (Neural Localizer Fields) : prédit des indices continus de pose/forme humaine qui se rendent dans les images de pose SCAIL 3D utilisées pour un contrôle structurel fort. GitHub
- YOLOv10 : détecteur rapide utilisé dans la chaîne de prétraitement de la pose pour la localisation des personnes. GitHub
Comment utiliser le flux de travail Comfyui SCAIL#
Flux global : chargez une image de référence et une vidéo de conduite optionnelle; extrayez et rendez les poses; encodez la référence avec CLIP vision; ajoutez les embeddings de référence SCAIL et de pose SCAIL; assemblez le conditionnement de texte; échantillonnez les cadres avec WanVideo; décodez et exportez la vidéo. Le graphe inclut des variables "Set_" publiques pour que la largeur, la hauteur, le CFG, et le nombre de cadres se propagent automatiquement.
- Entrées et dimensions
- Chargez une image de personnage de référence ou une vidéo pour le transfert de mouvement. Le flux de travail redimensionne la référence à la taille de génération et s'assure que les dimensions cibles sont divisibles par 32. Si vous chargez une vidéo, son audio est disponible pour le passage à l'exportation finale.
- Réglez une fois la largeur, la hauteur, et le nombre de cadres; les valeurs alimentent l'échantillonneur, le décodeur, et l'exportateur via des getters et setters partagés. Gardez le rapport d'aspect cohérent entre la référence et la sortie pour minimiser les artefacts d'étirement.
- Extraction de pose (groupe : Extraction de pose)
- Les cadres vidéo ou images d'entrée sont redimensionnés pour l'analyse et alimentés à un prédicteur de pose NLF et à un détecteur ViTPose. La sortie ViTPose est convertie au format DWPose pour un détail optionnel du visage/des mains et pour aligner la pose globale au sujet de référence.
- Les images de pose SCAIL rendues sont produites à la moitié de la résolution de génération en interne pour l'efficacité, puis composées à la taille cible, préservant les indices de profondeur et les occlusions. Le dessin du visage/des mains peut être basculé tout en utilisant encore l'alignement; déconnectez DWPose si vous souhaitez désactiver l'alignement de la pose.
- Encodage de l'identité de référence
- L'image de référence est encodée avec CLIP ViT-H/14 et convertie en embeddings d'image WanVideo. Ces embeddings capturent la couleur, la texture, et la structure locale pour que SCAIL puisse garder le personnage cohérent à travers des mouvements difficiles.
- Si l'identité dérive dans des plans longs ou stylisés, gardez une référence propre et de face; cela renforce le signal CLIP utilisé en aval.
- Conditionnement de pose SCAIL
- Les rendus de pose SCAIL sont injectés comme des embeddings d'image supplémentaires. Ils agissent comme un guidage structurel fort qui impose le placement des membres, l'ordre de profondeur, et la stabilité de la silhouette à travers les cadres.
- Vous pouvez échanger la source de conduite à ce stade : utilisez des poses extraites d'une vidéo pour le transfert de mouvement ou alimentez des images de pose SCAIL pré-rendues pour chorégraphier des séquences sans conducteur.
- Conditionnement d'invite de texte
- Les invites sont encodées en embeddings de texte qui biaisent le style, la garde-robe, l'éclairage, et l'environnement. Utilisez des descripteurs concis qui complètent l'image de référence; le texte négatif peut réduire la sur-saturation, les artefacts, ou l'encombrement.
- Les invites sont optionnelles lorsque vous voulez que la sortie suive de près l'apparence de la référence sous contrôle SCAIL.
- Échantillonnage et planification
- L'échantillonneur WanVideo exécute le transformateur de diffusion avec le modèle, l'ordonnanceur, les embeddings d'image (référence + pose SCAIL), les embeddings de texte, et le guidage CFG. Un nœud d'options de contexte peut fenêtrer de longues séquences pour une génération économe en mémoire tout en préservant la continuité temporelle.
- Si vous remarquez des scintillements ou des bords flous, envisagez un ordonnanceur plus lent ou un CFG légèrement plus fort; si le mouvement semble trop contraint, réduisez le guidage global pour que les indices de structure et d'apparence de SCAIL s'équilibrent naturellement.
- Décodage et exportation
- Les latents sont décodés en cadres à l'aide du Wan VAE, et la vidéo est écrite avec votre cadence et préfixe de nom de fichier choisis. Le flux de travail peut concaténer les visuels pour des tranches A/B et passe l'audio lorsque connecté.
- Inspectez la sortie; si les bras ou les jambes se coupent lors de virages rapides, revisitez la qualité de l'extraction de pose ou des entrées d'alignement, puis réenfilez avec les mêmes graines pour une itération contrôlée.
Nœuds clés dans le flux de travail Comfyui SCAIL#
WanVideoAddSCAILReferenceEmbeds(#350)- Ajoute le conditionnement d'identité et d'apparence de l'image de référence dans le flux d'embedding d'image. Augmentez son influence lorsque le visage ou les vêtements du personnage dérivent; diminuez si le modèle refuse de s'adapter à de grandes rotations corporelles ou à un éclairage dramatique.
WanVideoAddSCAILPoseEmbeds(#324)- Injecte les images de pose SCAIL rendues comme guidage structurel. Augmentez son influence pour un placement plus strict des membres et une stabilité de silhouette; diminuez si le mouvement semble trop rigide ou si vous souhaitez plus de liberté pour que les invites de style plient légèrement la pose.
RenderNLFPoses(#362)- Rend les prédictions continues de NLF en images de pose au style SCAIL, superposant éventuellement le visage/mains DWPose et effectuant l'alignement pose-à-référence. Gardez le rendu de pose interne à la moitié de la résolution cible pour correspondre à la conception de SCAIL et éviter l'aliasing; déconnectez DWPose pour supprimer l'alignement.
WanVideoSamplerv2(#348)- Conduit l'échantillonnage principal de diffusion avec le modèle, les embeddings d'image/texte, l'ordonnanceur, des arguments supplémentaires, et
cfg. Si vous voyez un vacillement temporel, utilisez un ordonnanceur plus stable ou plus d'étapes; si les détails dépassent la référence, réduisezcfgpour que les indices d'identité de SCAIL mènent.
- Conduit l'échantillonnage principal de diffusion avec le modèle, les embeddings d'image/texte, l'ordonnanceur, des arguments supplémentaires, et
WanVideoSchedulerv2(#349)- Contrôle le comportement de l'ordonnancement de débruitage. Choisissez des ordonnancements qui équilibrent le détail et la stabilité; des ordonnancements plus lents améliorent souvent la cohérence temporelle pour les mouvements amples et les longues séquences.
WanVideoClipVisionEncode(#327)- Encode l'image de référence avec ViT-H/14 et produit des embeddings d'image CLIP pour l'identité. Utilisez des références de haute qualité et bien éclairées; les vues frontales ou 3/4 tendent à mieux ancrer les visages et les cheveux.
Extras optionnels#
- Les dimensions doivent être divisibles par 32. Gardez les rapports d'aspect de référence et de sortie alignés pour éviter les déformations.
- SCAIL s'attend à des rendus de pose à la moitié de la résolution de génération; ce flux de travail le calcule automatiquement donc vous n'avez pas besoin de le gérer manuellement.
- Pour des mains et expressions précises, gardez DWPose connecté pour activer les indices du visage/mains; pour désactiver uniquement l'alignement, déconnectez le lien DWPose mais gardez les images de pose rendues.
- Longues séquences : utilisez le nœud d'options de contexte pour fenêtrer la génération pour l'efficacité mémoire tout en gardant un chevauchement pour des transitions fluides.
- Si vous utilisez des poids de prévisualisation SCAIL reconditionnés pour ComfyUI, récupérez-les des distributions communautaires si nécessaire. Exemple de pack de prévisualisation : Kijai/WanVideo_comfy SCAIL et Kijai/WanVideo_comfy_fp8_scaled SCAIL.
Remerciements#
Ce flux de travail implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Ai Verse Z.ai (zai-org) pour SCAIL (implémentation officielle) et teal024 pour la page de projet SCAIL pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux référentiels liés ci-dessous.
Ressources#
- zai-org/SCAIL
- GitHub: zai-org/SCAIL
- Hugging Face: zai-org/SCAIL-Preview
- arXiv: arXiv:2512.05905
- teal024/SCAIL Project Page
- Docs / Release Notes: Project Page
- GitHub: zai-org/SCAIL
- Hugging Face: zai-org/SCAIL-Preview
- arXiv: arXiv:2512.05905
Remarque : L'utilisation des modèles, ensembles de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.