
Qwen Image LoRA Inference : inférence AI Toolkit correspondant à l'entraînement dans ComfyUI#
L'inférence Qwen Image LoRA est un workflow RunComfy prêt pour la production pour appliquer un LoRA entraîné par AI Toolkit à Qwen Image dans ComfyUI avec un comportement correspondant à l'entraînement. Il est centré sur RC Qwen Image (RCQwenImage)—un nœud personnalisé open-source construit par RunComfy (source) qui exécute un pipeline d'inférence spécifique à Qwen Image (pas un graphique d'échantillonneur générique) et injecte votre adaptateur via lora_path et lora_scale.
Pourquoi l'inférence Qwen Image LoRA semble souvent différente dans ComfyUI#
Les aperçus de l'AI Toolkit sont produits par un pipeline d'inférence spécifique au modèle, avec la propre mise en condition et implémentation de guidage de Qwen Image. Si vous reconstruisez l'échantillonnage de Qwen Image en tant que graphique ComfyUI générique, vous modifiez souvent les paramètres par défaut du pipeline (et l'itinéraire exact où le LoRA est appliqué), donc le même prompt/étapes/seed peut encore dériver. Lorsque les sorties ne correspondent pas, il s'agit généralement d'un décalage au niveau du pipeline—pas d'un simple "mauvais bouton".
Ce que fait le nœud personnalisé RCQwenImage#
RCQwenImage enveloppe l'inférence Qwen Image dans un pipeline aligné sur l'aperçu et applique votre AI Toolkit LoRA à l'intérieur de ce pipeline via lora_path / lora_scale, de sorte que le comportement d'échantillonnage reste cohérent pour cette famille de modèles. Implémentation de référence : `src/pipelines/qwen_image.py`.
Comment utiliser le workflow Qwen Image LoRA Inference#
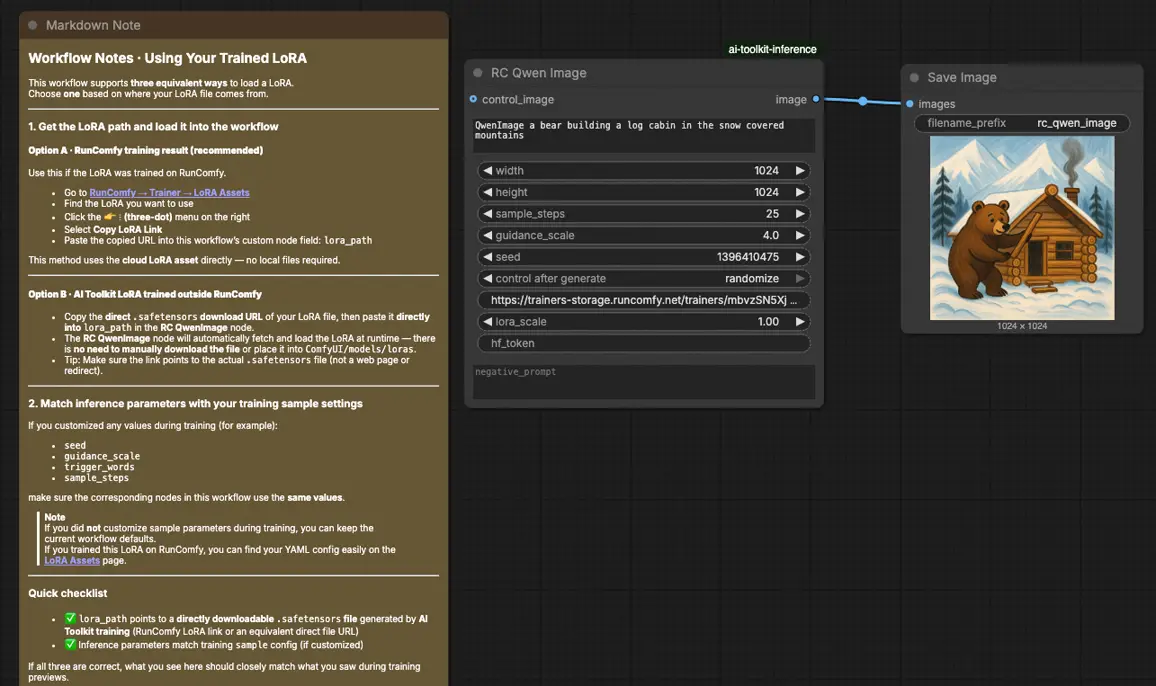
Étape 1 : Ouvrir le workflow#
Ouvrez le workflow sauvegardé dans le cloud dans ComfyUI
Étape 2 : Importer votre LoRA (2 options)#
- Option A (résultat de l'entraînement RunComfy) : RunComfy → Trainer → LoRA Assets → trouvez votre LoRA → ⋮ → Copier le lien LoRA

- Option B (LoRA AI Toolkit entraîné en dehors de RunComfy) : Copiez un lien de téléchargement direct
.safetensorspour votre LoRA et collez cette URL danslora_path(pas besoin de télécharger dansComfyUI/models/loras)
Étape 3 : Configurer le nœud personnalisé RCQwenImage pour l'inférence Qwen Image LoRA#
Définissez le reste des paramètres du nœud (ils doivent correspondre à ceux que vous avez utilisés pour l'échantillonnage d'aperçu AI Toolkit lorsque vous comparez les résultats) :
prompt: votre texte de prompt (incluez les mêmes tokens déclencheurs que vous avez utilisés pendant l'entraînement, le cas échéant)negative_prompt: optionnel ; laissez-le vide si vous n'avez pas utilisé de négatifs dans vos aperçus d'entraînementwidth/height: résolution de sortie (des multiples de 32 sont recommandés pour Qwen Image)sample_steps: nombre d'étapes d'inférence utilisées par le pipeline Qwen Imageguidance_scale: force de guidage (Qwen Image utilise une échelle "CFG véritable" ; commencez par refléter votre valeur d'aperçu avant de l'ajuster)seed: seed fixe pour la répétabilité ; changez-le uniquement après avoir validé la baselora_scale: force du LoRA (commencez à votre force d'aperçu, puis ajustez par petits incréments)
Remarque sur l'alignement de l'entraînement : si vous avez ajusté vos paramètres d'échantillon d'entraînement, ouvrez votre YAML d'entraînement AI Toolkit et reflétez width, height, sample_steps, guidance_scale, et seed. Si vous vous êtes entraîné sur RunComfy, utilisez Trainer → LoRA Assets → Config pour copier les mêmes valeurs d'aperçu dans RCQwenImage.

Étape 4 : Exécuter l'inférence Qwen Image LoRA#
Mettez en file d'attente le workflow, puis exécutez-le. Le nœud SaveImage écrit l'image générée dans votre répertoire de sortie standard ComfyUI.
Dépannage de l'inférence Qwen Image LoRA#
La plupart des problèmes rencontrés après avoir entraîné un Qwen Image LoRA dans Ostris AI Toolkit puis essayé de l'exécuter dans ComfyUI se résument à un décalage pipeline + injection LoRA.
Le nœud personnalisé RC Qwen Image (RCQwenImage) de RunComfy est conçu pour maintenir l'inférence alignée sur le pipeline avec l'échantillonnage d'aperçu AI Toolkit en exécutant un pipeline d'inférence spécifique à Qwen Image (pas un graphique d'échantillonneur générique) et en injectant votre adaptateur via lora_path / lora_scale à l'intérieur de ce pipeline.
(1)Les Loras Qwen-Image ne fonctionnent pas dans comfyui#
Pourquoi cela arrive
Ceci est souvent signalé comme étant soit :
- beaucoup d'avertissements
lora key not loaded, et/ou - le LoRA "s'exécute" mais la sortie ne change pas comme elle le faisait dans l'échantillonnage AI Toolkit.
En pratique, les utilisateurs ont constaté que cela provient souvent du fait que ComfyUI n'est pas sur une version qui inclut encore la nouvelle cartographie des clés Qwen LoRA, ou du fait de charger le LoRA via un chemin générique qui ne correspond pas aux noms de modules Qwen Image utilisés par le workflow.
Comment réparer
- Passez ComfyUI sur le canal "nightly / development" et mettez à jour, puis réexécutez le même workflow. Plusieurs utilisateurs ont signalé que cela supprime le spam
lora key not loadedet permet d'appliquer correctement les LoRAs Qwen-Image. - Utilisez RCQwenImage et passez le LoRA uniquement via
lora_path/lora_scale(évitez d'empiler des nœuds de chargeur LoRA supplémentaires dessus). RCQwenImage garde le point d'injection LoRA au niveau du pipeline cohérent avec l'inférence de style AI Toolkit. - Lors de la comparaison avec les aperçus AI Toolkit, reflétez exactement les valeurs de l'échantillonneur d'aperçu :
width,height,sample_steps,guidance_scale,seed, etlora_scale.
(2)Problème de génération d'image Qwen et de qualité de sortie avec l'utilisation du Qwen lighting 8 steps Lora#
Pourquoi cela arrive
Les gens signalent qu'après avoir mis à jour ComfyUI, les sorties Qwen Image deviennent déformées ou "bizarres", et la console affiche lora key not loaded pour le Lightning 8-step LoRA—ce qui signifie que le LoRA de vitesse/qualité n'est probablement pas réellement appliqué, même si une image est toujours produite.
Comment réparer (vérifié par l'utilisateur + correspondant à l'entraînement)
- Passez à ComfyUI nightly et mettez à jour. C'est la solution la plus fréquemment signalée pour
lora key not loadedavec les LoRAs Qwen-Image Lightning. - Si vous utilisez le workflow natif Comfy, les utilisateurs ont signalé un succès en insérant
LoraLoaderModelOnlyentre le chargeur de modèle et les nœuds d'échantillonnage de modèle sur la dernière version nightly. - Pour correspondre à l'aperçu d'entraînement (AI Toolkit), validez d'abord via RCQwenImage (aligné sur le pipeline), puis ajustez uniquement
lora_scaleaprès que la base correspond.
(3)Le LoRA de personnage Qwen Image semble différent des échantillons d'entraînement#
Pourquoi cela arrive
Un rapport courant est : les échantillons d'entraînement AI Toolkit semblent corrects, mais dans ComfyUI, le LoRA a "peu ou pas d'impact". Pour Qwen Image, cela signifie généralement soit :
- le LoRA n'est pas vraiment appliqué (souvent accompagné de
lora key not loaded/ support Qwen obsolète), ou - le LoRA est chargé via un itinéraire de graphique/chargeur qui ne correspond pas à la manière dont Qwen Image s'attend à ce que les modules soient patchés.
Comment réparer (vérifié par l'utilisateur + correspondant à l'entraînement)
- Validez le LoRA via RCQwenImage (injection alignée sur le pipeline en un seul nœud via
lora_path/lora_scale). Si l'effet LoRA apparaît ici mais pas dans votre graphique manuel, vous avez confirmé un décalage pipeline/chargeur plutôt qu'un échec de formation. - Lors de la correspondance avec les échantillons d'aperçu AI Toolkit, ne changez pas de résolution/étapes/guidage/seed pendant le diagnostic. Correspondre d'abord aux valeurs de l'échantillonneur d'aperçu, puis ajustez
lora_scalepar petits incréments.
Exécutez maintenant l'inférence Qwen Image LoRA#
Ouvrez le workflow RunComfy, définissez lora_path, et exécutez RCQwenImage pour maintenir l'inférence Qwen Image LoRA dans ComfyUI alignée avec vos aperçus d'entraînement AI Toolkit.