
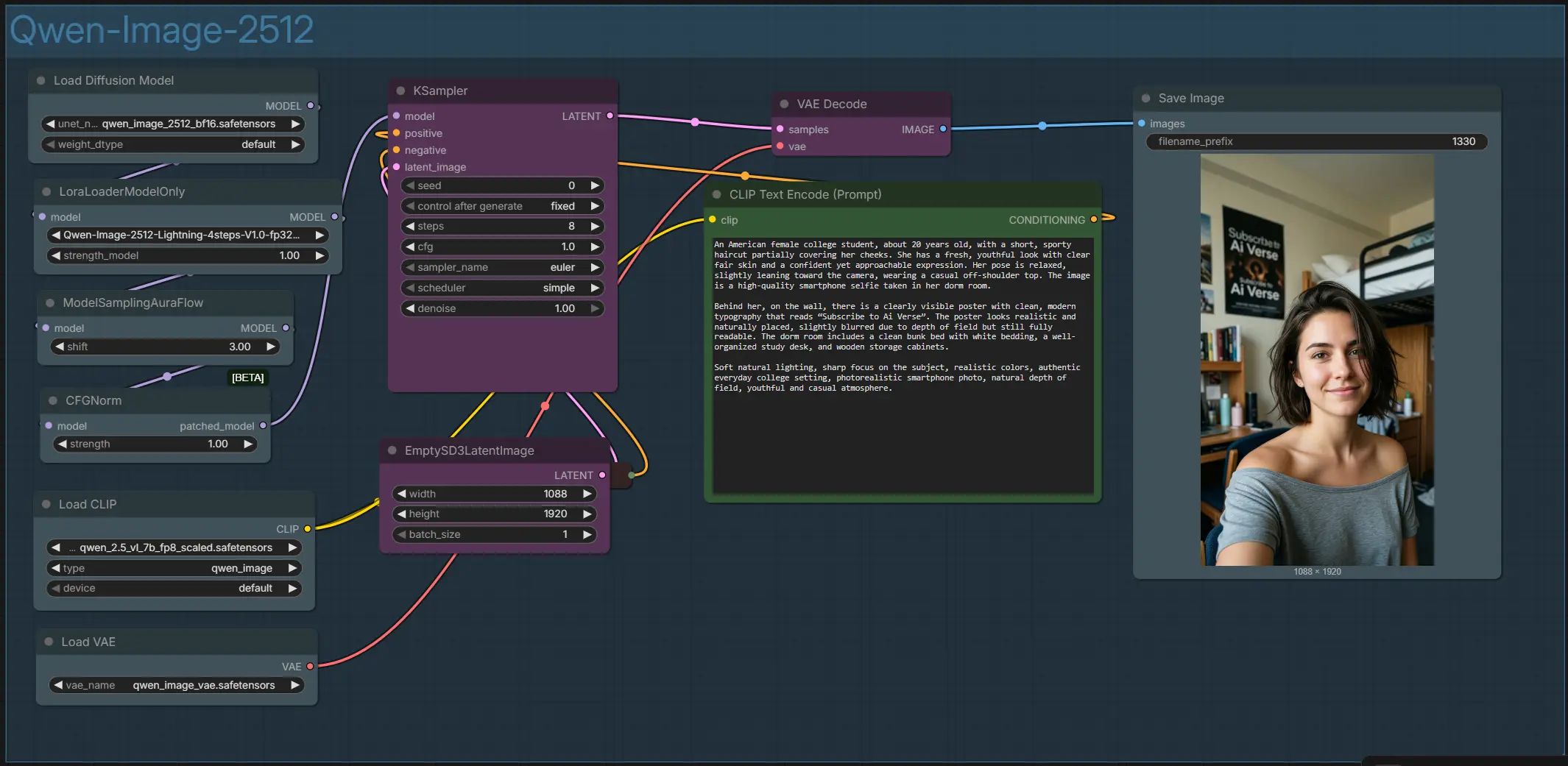






Flux de travail Qwen Image 2512 ComfyUI pour portraits et scènes textuellement précis#
Ce flux de travail transforme votre prompt en une image haute fidélité utilisant Qwen Image 2512. Il est conçu pour les créateurs qui ont besoin d'un alignement texte-image fort, de personnes réalistes, et d'un rendu fiable de texte bilingue dans la scène. Le graphe est pré-câblé avec le VAE et l'encodeur de texte de Qwen, plus un Lightning LoRA optionnel pour une génération en quelques étapes, vous permettant de passer du prompt au résultat avec un minimum de configuration.
Utilisez-le pour le concept art, l'illustration, la signalétique, les affiches et les styles photo quotidiens. Qwen Image 2512 apporte une composition stable et une typographie nette, en faisant un choix solide pour les prompts qui mélangent personnes, environnements et texte lisible.
Modèles clés dans le flux de travail Comfyui Qwen Image 2512#
- Modèle de base Qwen-Image 2512 (bfloat16). Modèle de diffusion de base qui synthétise l'image à partir du conditionnement. Les poids prêts pour Comfy sont fournis dans le package Comfy-Org. Fichiers du modèle
- Encodeur de texte Qwen2.5-VL 7B. Encode votre prompt en vecteurs de conditionnement qui pilotent la mise en page, le style et le rendu de texte de Qwen Image 2512. Fichiers de l'encodeur de texte
- VAE Qwen Image. Décode le latent produit par l'échantillonneur en une image RGB avec une couleur et un détail fidèles. Fichier VAE
- Qwen-Image-2512-Lightning-4steps-V1.0 LoRA (optionnel). Un LoRA communautaire ajusté pour une génération en quelques étapes afin d'accélérer le rendu avec des compromis de qualité mineurs. Carte LoRA
- Pour des informations de fond sur la famille de modèles et l'approche d'entraînement, voir le rapport technique Qwen-Image. Article
Comment utiliser le flux de travail Comfyui Qwen Image 2512#
Flux global : votre prompt est encodé, une toile latente est créée à la résolution choisie, la pile de modèles applique le modèle de base et le LoRA optionnel, l'échantillonneur itère pour affiner le latent, et le VAE décode l'image finale pour l'enregistrement.
- Vue d'ensemble du groupe Qwen-Image-2512
- L'ensemble du graphe est organisé dans un seul groupe nommé "Qwen-Image-2512." Il relie l'encodeur de texte, la pile de modèles et de LoRA, les aides à l'échantillonnage, et le décodage VAE. Vous contrôlez l'apparence avec vos prompts positifs et négatifs, la taille de la toile, et quelques réglages de l'échantillonneur. La sortie est une image de style portrait haute résolution enregistrée dans votre dossier de sortie ComfyUI.
- Prompts avec
CLIPTextEncode(#52) et négatifs optionnelsCLIPTextEncode(#32)- Entrez votre description principale dans
CLIPTextEncode(#52). Écrivez la scène, les sujets, et tout texte dans l'image que vous souhaitez rendre ; Qwen Image 2512 est particulièrement fort pour la signalétique, les affiches, les maquettes d'interface utilisateur, et les légendes bilingues. UtilisezCLIPTextEncode(#32) pour des négatifs optionnels afin d'éviter les artefacts ou les styles indésirables. Gardez les extraits de texte entre guillemets si vous avez besoin d'un libellé précis.
- Entrez votre description principale dans
- Toile et rapport d'aspect avec
EmptySD3LatentImage(#57)- Choisissez votre largeur et hauteur cibles ici pour définir la composition. Les formats portrait fonctionnent bien pour les personnes et les selfies, tandis que les rapports carrés et paysages conviennent aux produits et aux mises en page de scène. Les toiles plus grandes offrent un détail plus fin au prix de la mémoire et du temps ; commencez modestement, puis agrandissez une fois que vous aimez le cadrage. La cohérence s'améliore lorsque vous gardez le même rapport d'aspect à travers les itérations.
- Pile de modèles et de LoRA avec
UNETLoader(#100) etLoraLoaderModelOnly(#101)- Le générateur de base est Qwen Image 2512 chargé par
UNETLoader(#100). Si vous souhaitez des rendus plus rapides, activez le Lightning LoRA dansLoraLoaderModelOnly(#101) pour passer à un flux de travail en quelques étapes. Cette pile définit les capacités du modèle pour le réalisme, la mise en page, et l'alignement texte-image avant que l'échantillonnage ne commence.
- Le générateur de base est Qwen Image 2512 chargé par
- Aides à l'échantillonnage avec
ModelSamplingAuraFlow(#43) etCFGNorm(#55)- Ces deux nœuds préparent le modèle pour un échantillonnage stable et équilibré en contraste.
ModelSamplingAuraFlow(#43) ajuste le calendrier pour garder les détails nets sans surcuisson des textures.CFGNorm(#55) normalise les conseils pour maintenir une couleur et une exposition cohérentes tout en suivant votre prompt.
- Ces deux nœuds préparent le modèle pour un échantillonnage stable et équilibré en contraste.
- Dénaturation et raffinement avec
KSampler(#54)- C'est l'étape de travail qui améliore itérativement le latent du bruit à une image cohérente. Vous définissez la graine pour la répétabilité, sélectionnez l'échantillonneur et le planificateur, et choisissez combien d'étapes exécuter. Avec Lightning activé, vous pouvez viser peu d'étapes ; avec le modèle de base seul, utilisez plus d'étapes pour une fidélité maximale.
- Décoder et enregistrer avec
VAEDecode(#45) etSaveImage(#117)- Après l'échantillonnage, le VAE reconstruit proprement le RGB à partir du latent et
SaveImageécrit le PNG final. Si les couleurs ou le contraste semblent décalés, repensez aux conseils ou à la formulation du prompt plutôt qu'à la post-traitement ; Qwen Image 2512 répond bien aux indices de lumière et de matériau descriptifs.
- Après l'échantillonnage, le VAE reconstruit proprement le RGB à partir du latent et
Nœuds clés dans le flux de travail Comfyui Qwen Image 2512#
UNETLoader(#100)- Charge le modèle de base Qwen-Image-2512 qui détermine la capacité globale et l'espace de style. Utilisez la construction bf16 pour une qualité maximale si votre GPU le permet. Passez à une variante fp8 ou compressée uniquement si vous devez ajuster la mémoire ou augmenter le débit.
LoraLoaderModelOnly(#101)- Applique le Qwen-Image-2512-Lightning-4steps-V1.0 LoRA sur le modèle de base. Augmentez ou diminuez
strength_modelpour mélanger le réglage de vitesse avec la fidélité de base, ou réglez-le à 0 pour désactiver. Lorsque ce LoRA est actif, réduisezstepsdansKSamplerà quelques itérations pour réaliser l'accélération.
- Applique le Qwen-Image-2512-Lightning-4steps-V1.0 LoRA sur le modèle de base. Augmentez ou diminuez
ModelSamplingAuraFlow(#43)- Corrige le comportement d'échantillonnage du modèle pour un calendrier de style flux qui donne souvent des bords plus nets et moins de bavures. Si les résultats semblent sur-aiguisés ou sous-détaillés, ajustez légèrement le paramètre
shiftet ré-échantillonnez. Gardez les autres variables stables pendant que vous testez pour isoler l'effet.
- Corrige le comportement d'échantillonnage du modèle pour un calendrier de style flux qui donne souvent des bords plus nets et moins de bavures. Si les résultats semblent sur-aiguisés ou sous-détaillés, ajustez légèrement le paramètre
CFGNorm(#55)- Normalise les conseils sans classificateur pour éviter les sorties délavées ou trop saturées. Utilisez
strengthpour décider de la force avec laquelle la normalisation doit agir. Si la précision du texte diminue lorsque vous augmentez le CFG, augmentez la force de normalisation au lieu d'augmenter davantage le CFG.
- Normalise les conseils sans classificateur pour éviter les sorties délavées ou trop saturées. Utilisez
EmptySD3LatentImage(#57)- Définit la taille de la toile latente qui détermine le cadrage et le rapport d'aspect. Pour les personnes, les ratios portrait réduisent la distorsion et aident avec les proportions corporelles ; pour les affiches, les ratios carrés ou paysages soulignent la mise en page et les blocs de texte. Augmentez la résolution seulement après être satisfait de la composition.
CLIPTextEncode(#52) etCLIPTextEncode(#32)- L'encodeur positif (#52) transforme votre description en conditionnement, y compris les chaînes de texte explicites à rendre dans la scène. L'encodeur négatif (#32) supprime les traits indésirables comme les artefacts, les doigts supplémentaires, ou les arrière-plans bruyants. Gardez les prompts concis et factuels pour le meilleur alignement.
KSampler(#54)- Contrôle la graine, l'échantillonneur, le planificateur, les étapes, le CFG, et la force de débruitage. Avec Qwen Image 2512, des valeurs CFG modérées conservent généralement le fort alignement textuel du modèle ; si les lettres se déforment, baissez le CFG avant de changer l'échantillonneur. Pour des brouillons rapides, activez Lightning et essayez très peu d'étapes, puis augmentez les étapes pour les rendus finaux si nécessaire.
VAELoader(#34) etVAEDecode(#45)- Chargez et appliquez le VAE de Qwen pour reconstruire des couleurs fidèles et des détails fins. Gardez le VAE associé au modèle de base pour éviter les décalages de couleur. Si vous changez les poids de base, changez également pour la construction VAE correspondante.
Extras optionnels#
- Prompts pour texte dans l'image
- Mettez les mots exacts entre guillemets droits, et ajoutez de brèves indications typographiques comme "typographie moderne épurée" ou "sans serif gras." Incluez des indices de placement tels que "affiche murale" ou "enseigne de vitrine" pour ancrer où le texte doit apparaître.
- Itération plus rapide avec Lightning
- Activez le Lightning LoRA et utilisez peu d'étapes pour les aperçus. Une fois le cadrage et le libellé corrects, désactivez ou réduisez la force du LoRA et augmentez les étapes pour récupérer la fidélité maximale.
- Choix de rapport d'aspect
- Maintenez des ratios cohérents à travers les variations. Utilisez le portrait pour les personnes, le carré pour les études de produit ou de logo, et le paysage pour les environnements ou les diapositives. Si vous suréchantillonnez plus tard, gardez le même ratio pour maintenir la composition.
- Discipline de guidage
- Qwen Image 2512 préfère généralement un CFG modeste. Si la fidélité du texte glisse, baissez le CFG ou augmentez la force
CFGNormplutôt que d'ajouter plus de guidage.
- Qwen Image 2512 préfère généralement un CFG modeste. Si la fidélité du texte glisse, baissez le CFG ou augmentez la force
- Reproductibilité
- Bloquez une graine lorsque vous aimez un résultat pour pouvoir itérer en toute sécurité. Changez un contrôle à la fois pour comprendre son impact avant de passer à autre chose.
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Comfy-Org pour les fichiers de modèle Qwen Image 2512 pour leurs contributions et leur maintenance. Pour des détails autoritatifs, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Comfy-Org/Qwen Image 2512 Model Files
- Hugging Face: Comfy-Org/Qwen-Image_ComfyUI
- Docs / Notes de version: Qwen Image 2512 Model Files
Note: L'utilisation des modèles, jeux de données, et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.