
Pose Control LipSync avec Wan2.2 S2V : image-à-vidéo pilotée par l'audio et contrôlée par la pose pour des avatars expressifs#
Pose Control LipSync avec Wan2.2 S2V transforme une seule image, un clip audio et une vidéo de référence de pose en une performance parlante synchronisée. Le personnage de votre image de référence suit le mouvement corporel de la vidéo de référence tandis que les mouvements labiaux correspondent à l'audio. Ce workflow ComfyUI est idéal pour les avatars, les scènes narratives, les bandes-annonces, les vidéos explicatives et les clips musicaux où vous souhaitez un contrôle précis sur la pose, l'expression et le timing du discours.
Construit sur la famille de modèles Wan 2.2 S2V 14B, le workflow fusionne des invites textuelles, des caractéristiques vocales claires et des cartes de poses pour générer un mouvement cinématique avec une identité stable. Il est conçu pour être simple à utiliser tout en offrant aux créateurs un contrôle précis sur l'apparence, le rythme et le cadrage.
Modèles clés dans le workflow Comfyui Pose Control LipSync avec Wan2.2 S2V#
- Wan2.2‑S2V‑14B. Le générateur principal de parole-à-vidéo qui transforme une image fixe plus un audio en vidéo, avec un conditionnement de pose optionnel pour guider le mouvement. Voir le dépôt officiel et la fiche du modèle pour les capacités et les notes d'utilisation : Wan‑Video/Wan2.2 et Wan‑AI/Wan2.2‑S2V‑14B.
- Wan VAE. L'autoencodeur Wan encode et décode les latents vidéo avec une haute fidélité et est utilisé à travers les pipelines Wan 2.x. Mise en œuvre de référence : Pipelines Wan dans Diffusers documentation.
- Google UMT5‑XXL encodeur de texte. Fournit un conditionnement textuel multilingue fort pour le contrôle de l'intention de scène et du style de haut niveau dans les pipelines Wan. Fiche du modèle : google/umt5‑xxl.
- Facebook Wav2Vec2‑Large. Extrait des caractéristiques vocales robustes qui pilotent la synchronisation labiale et les micro-expressions. Fiche du modèle : facebook/wav2vec2‑large‑960h.
- DWPose avec détecteur YOLOX. Génère des points clés de pose humaine et des cartes de pose à partir de la vidéo de référence pour guider le mouvement corporel complet. Dépôts : IDEA‑Research/DWPose et Megvii‑BaseDetection/YOLOX.
- LightX2V LoRA pour Wan. Un LoRA léger utilisé pour accélérer le débruitage de style image-à-vidéo à faible étape tout en préservant la qualité du mouvement ; Wan 2.2 prend en charge les LoRAs dans ses débruiteurs. Voir les conseils sur l'utilisation des LoRAs dans les pipelines Wan dans Wan pipelines.
Comment utiliser le workflow Comfyui Pose Control LipSync avec Wan2.2 S2V#
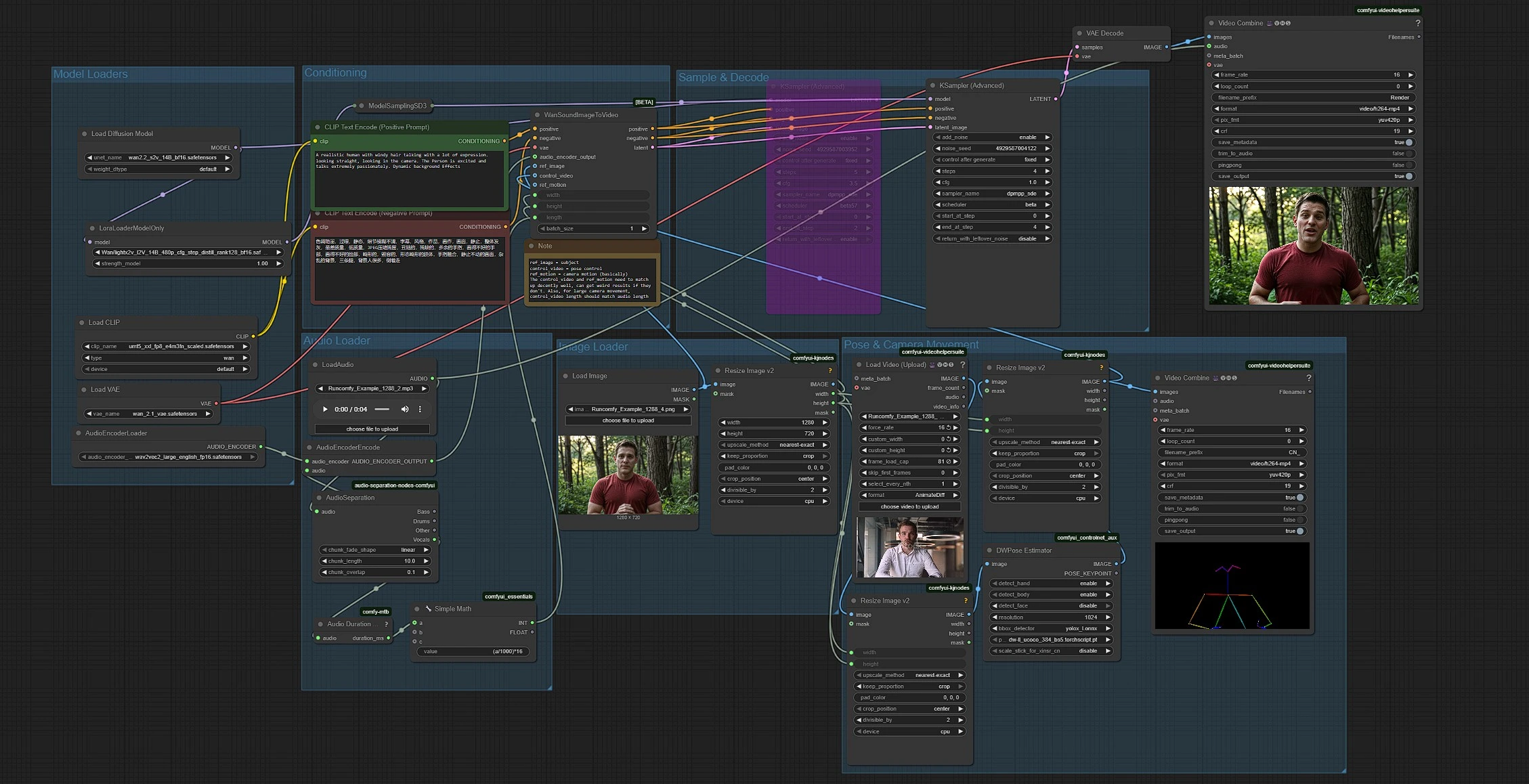
Le workflow combine cinq parties : chargement de modèles, préparation audio, entrées image et pose, conditionnement et génération. Les groupes fonctionnent dans un flux de gauche à droite, avec la longueur de l'audio définissant automatiquement la durée du clip à 16 fps.
Chargeurs de modèles#
Ce groupe charge le modèle Wan 2.2 S2V, son VAE, l'encodeur de texte UMT5‑XXL et un LightX2V LoRA. Le transformateur de base est initialisé dans UNETLoader (#37) et adapté avec LoraLoaderModelOnly (#61) pour un échantillonnage plus rapide à faible étape. Le Wan VAE est fourni par VAELoader (#39). Les encodeurs de texte sont fournis par CLIPLoader (#38) qui charge les poids UMT5‑XXL référencés par Wan. Vous n'avez rarement besoin de toucher ce groupe sauf si vous échangez des fichiers de modèles.
Chargeur Audio#
Déposez un fichier audio avec LoadAudio (#58). AudioSeparation (#85) isole la piste vocale pour que les lèvres suivent un discours ou un chant clair plutôt que des instruments de fond. Audio Duration (mtb) (#70) mesure le clip et SimpleMath+ (#71) convertit la durée en un nombre d'images à 16 fps pour que la longueur de la vidéo corresponde à votre audio. AudioEncoderEncode (#56) alimente un encodeur Wav2Vec2‑Large pour que Wan puisse mapper les phonèmes aux formes de bouche pour une synchronisation labiale précise.
Chargeur d'Images#
LoadImage (#52) fournit l'image fixe du sujet qui porte l'identité, les vêtements et la configuration de la caméra. ImageResizeKJv2 (#69) lit les dimensions de l'image pour que le pipeline dérive systématiquement la largeur et la hauteur cibles pour toutes les étapes ultérieures. Utilisez une image nette, de face, avec une bouche dégagée pour les mouvements labiaux les plus fidèles.
Mouvement de Pose & Caméra#
VHS_LoadVideo (#80) importe votre vidéo de référence de pose. ImageResizeKJv2 (#83) adapte les cadres à la taille cible, et DWPreprocessor (#78) les transforme en cartes de poses avec détection YOLOX plus points clés DWPose. Un dernier ImageResizeKJv2 (#81) aligne les cadres de pose à la résolution de génération avant qu'ils ne soient transmis en tant que vidéo de contrôle. Vous pouvez prévisualiser les sorties de pose en les routant vers VHS_VideoCombine (#95), ce qui aide à confirmer que le cadrage et le timing de référence conviennent à votre sujet.
Conditionnement#
Écrivez le style et l'intention de la scène dans CLIP Text Encode (Positive Prompt) (#6) et utilisez CLIP Text Encode (Negative Prompt) (#7) pour décourager les artefacts indésirables. Les invites dirigent les esthétiques de haut niveau et le mouvement de fond, tandis que l'audio pilote les mouvements labiaux et la référence de pose régit la dynamique corporelle. Gardez les invites concises et alignées avec votre angle de caméra cible et l'ambiance.
Échantillon & Décodage#
WanSoundImageToVideo (#55) fusionne le texte, les caractéristiques audio, l'image de référence et la vidéo de contrôle de pose, puis prépare une séquence latente. KSamplerAdvanced (#64) effectue le débruitage à faible étape adapté à l'accélération de style LightX2V, et VAEDecode (#8) reconstruit les cadres. VHS_VideoCombine (#62) assemble les cadres en un MP4 et attache votre audio original pour que la sortie soit prête à être revue ou éditée.
Nœuds clés dans le workflow Comfyui Pose Control LipSync avec Wan2.2 S2V#
WanSoundImageToVideo (#55)#
Le cœur du workflow qui conditionne Wan2.2‑S2V avec votre invite, vos vocaux, votre image de sujet et votre vidéo de contrôle de pose. Ajustez uniquement ce qui compte : définissez width, height et length pour correspondre à votre image de sujet et à la longueur de l'audio, et branchez une vidéo de pose prétraitée pour le contrôle du mouvement. Laissez ref_motion vide sauf si vous prévoyez d'injecter une piste de caméra séparée. Le comportement de parole-à-vidéo du modèle est décrit dans Wan‑AI/Wan2.2‑S2V‑14B et Wan‑Video/Wan2.2.
DWPreprocessor (#78)#
Génère des cartes de pose en utilisant YOLOX pour la détection et DWPose pour les points clés du corps entier. Des indices de pose forts aident Wan à suivre les membres et le torse tandis que l'audio contrôle les lèvres et les expressions. Si votre référence a un mouvement de caméra important, utilisez une vidéo de pose qui aligne le point de vue et le timing avec la performance prévue. DWPose et ses variantes sont documentés dans IDEA‑Research/DWPose.
KSamplerAdvanced (#64)#
Exécute le débruitage pour la séquence latente. Avec un LightX2V LoRA chargé, vous pouvez garder les étapes basses pour des aperçus rapides tout en conservant la cohérence du mouvement ; augmentez les étapes lorsque vous poussez pour un maximum de détails. Les choix de planification affectent la fluidité contre la netteté du mouvement, et doivent être ajustés conjointement avec l'utilisation des LoRAs comme décrit pour Wan dans les Diffusers documentation.
VHS_LoadVideo (#80)#
Importe et frotte votre référence de pose. Utilisez ses outils de sélection de cadre dans le nœud pour choisir le segment exact qui correspond à votre segment audio. Garder le cadrage et la taille du sujet cohérents avec l'image de référence stabilisera le transfert de mouvement. Le nœud fait partie de VideoHelperSuite : ComfyUI‑VideoHelperSuite.
VHS_VideoCombine (#62)#
Combine les cadres générés et votre audio en un MP4 et enregistre les métadonnées du workflow. Réglez le taux de trame de sortie à 16 fps pour correspondre au nombre d'images calculé à partir de la durée audio dans ce workflow. Désactivez ou activez l'enregistrement des métadonnées selon vos besoins de gestion des actifs. Voir la documentation de VideoHelperSuite à ComfyUI‑VideoHelperSuite.
AudioSeparation (#85)#
Isole les vocaux pour que les caractéristiques Wav2Vec2 pilotent les formes de bouche sans interférence des instruments ou FX. Si votre entrée est déjà un discours clair, vous pouvez contourner la séparation. Pour de meilleurs résultats, maintenez des niveaux audio constants et minimisez la réverbération.
Extras optionnels#
- Pour la meilleure synchronisation labiale, préférez les discours clairs ou les vocaux a cappella. Wav2Vec2 fonctionne à 16 kHz ; la plupart des pipelines resamplent automatiquement, mais fournir des fichiers à 16 kHz aide.
- Utilisez une image de sujet bien éclairée, de face, avec des dents et des lèvres visibles. Les occlusions réduisent la précision.
- Adaptez le cadrage et le mouvement de la référence de pose à votre sujet. Les grands mouvements de caméra fonctionnent mieux lorsque la longueur de la vidéo de pose correspond au segment audio.
- Commencez à 480p pour une itération rapide ; passez à 720p pour la qualité finale. Wan 2.2 prend en charge les deux résolutions en S2V.
- Gardez les invites courtes et cohérentes avec la configuration de la caméra dans votre image et référence de pose pour éviter les conflits.
- Si vous expérimentez avec les LoRAs, assurez-vous qu'ils sont compatibles avec les débruiteurs Wan 2.2. Voir les notes sur les LoRAs dans les Diffusers docs.
Ce workflow Pose Control LipSync avec Wan2.2 S2V vous offre un chemin rapide de l'audio et d'une image fixe à une performance contrôlable et en rythme qui semble cohérente et se sent expressive.
Remerciements#
Ce workflow met en œuvre et se base sur les travaux et ressources suivants. Nous remercions chaleureusement @ArtOfficialLabs de Pose Control LipSync avec Wan2.2 S2VDemo pour leurs contributions et leur maintenance. Pour les détails autorisés, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- YouTube/Pose Control LipSync avec Wan2.2 S2VDemo
- Docs / Notes de version de @ArtOfficialLabs : Pose Control LipSync avec Wan2.2 S2VDemo
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.