
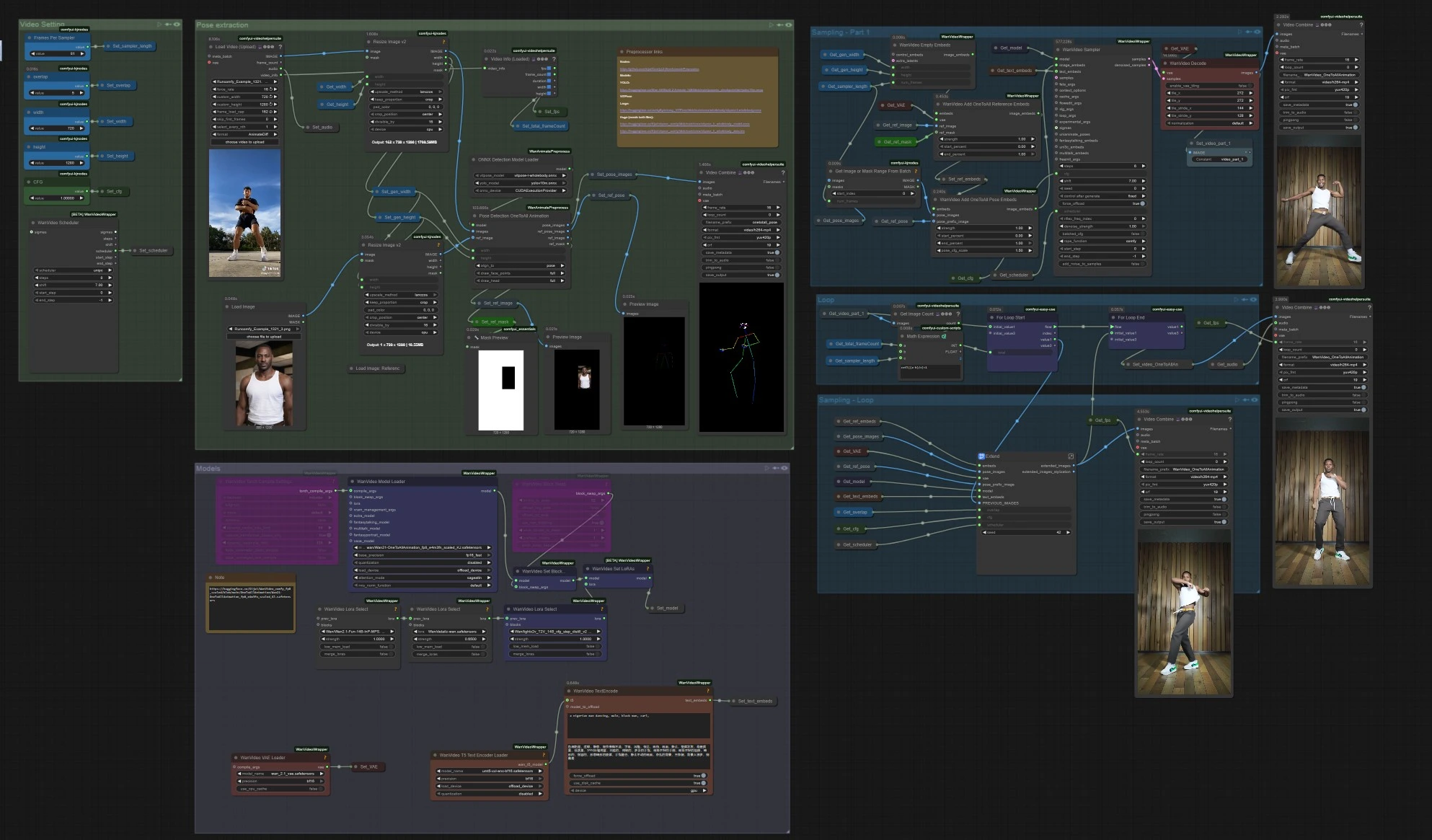
One to All Animation : vidéo de personnage alignée sur la pose dans ComfyUI#
Ce workflow One to All Animation transforme un court clip de référence en une vidéo étendue et haute fidélité tout en maintenant la cohérence du mouvement, l’alignement des poses et l’identité des personnages tout au long de la séquence. Construit autour de la génération vidéo Wan 2.1 avec guidage de pose pour tout le corps et un extensible à fenêtre glissante, il est idéal pour la danse, la capture de performance et les prises de vue narratives où vous souhaitez qu’un seul look suive un mouvement complexe.
Si vous êtes un créateur ayant besoin de sorties stables et guidées par la pose sans tremblement ni dérive d’identité, One to All Animation vous offre un chemin clair : extrayez les poses de votre vidéo source, fusionnez-les avec une image de référence et un masque, générez le premier segment, puis étendez ce segment de manière répétée jusqu'à couvrir toute la longueur.
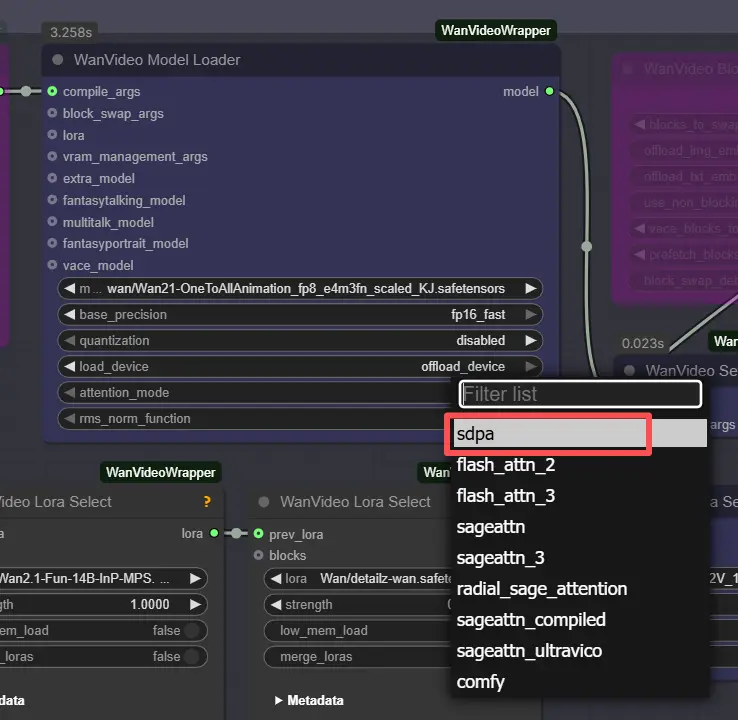
Remarque : Sur les machines 2XL ou 3XL, veuillez régler le mode_attention sur "sdpa" dans le noeud WanVideo Model Loader. Le backend segeattn par défaut peut causer des problèmes de compatibilité sur les GPU haut de gamme.
Modèles clés du workflow One to All Animation dans Comfyui#
- Wan 2.1 OneToAllAnimation (génération vidéo). Le modèle de diffusion principal utilisé pour la rétention de mouvement et d'identité de haute qualité. Poids d'exemple : Wan21-OneToAllAnimation fp8 mis à l'échelle par Kijai. Model card
- UMT5-XXL encodeur de texte. Encode les invites pour la génération vidéo Wan. Model card
- ViTPose Whole-Body (estimation de pose). Produit des points clés squelettiques denses qui conduisent la fidélité des poses. Voir le document ViTPose et les poids ONNX pour tout le corps. Paper • Weights
- Détecteur YOLOv10m (détection de personne/région). Accélère l'extraction de pose robuste en concentrant l'estimateur sur le sujet. Paper • Weights
- Alternative ViTPose-H optionnelle. Modèle de tout le corps à plus grande capacité pour les mouvements difficiles. Weights et data file
- Packs LoRA optionnels pour le style/contrôle. Les LoRAs d'exemple utilisés dans ce graphique incluent Wan2.1-Fun-InP-MPS, detailz-wan et lightx2v T2V; ils affinent la texture, le détail ou le contrôle sur place sans réentraînement.
Comment utiliser le workflow One to All Animation dans Comfyui#
Flux global
- Le workflow lit votre vidéo de mouvement de référence, extrait des poses de tout le corps, prépare des embeddings One to All Animation qui fusionnent la pose et une référence de personnage, génère un clip initial, puis étend ce clip de manière répétée avec chevauchement jusqu'à ce que toute la durée soit couverte. Enfin, il fusionne l'audio et exporte une vidéo complète.
Extraction de pose
- Chargez votre source de mouvement dans
VHS_LoadVideo(#454). Les frames sont redimensionnées avecImageResizeKJv2(#131) pour correspondre au rapport d'aspect de génération pour un échantillonnage stable. OnnxDetectionModelLoader(#128) charge YOLOv10m et ViTPose pour tout le corps;PoseDetectionOneToAllAnimation(#141) produit ensuite une carte de pose par frame, une image de pose de référence et un masque de référence propre.- Utilisez
PreviewImage(#145) pour inspecter rapidement que les poses suivent le sujet. Des séquences claires et à fort contraste avec un flou de mouvement minimal donnent les meilleurs résultats One to All Animation.
Modèles
WanVideoModelLoader(#22) charge les poids Wan 2.1 OneToAllAnimation;WanVideoVAELoader(#38) fournit le VAE associé. Si désiré, empilez les LoRAs de style/contrôle viaWanVideoLoraSelect(#452, #451, #56) et appliquez-les avecWanVideoSetLoRAs(#80).- Les invites textuelles sont encodées par
WanVideoTextEncode(#16). Rédigez une invite positive concise et centrée sur l'identité et une forte négative de nettoyage pour garder le personnage sur le modèle.
Réglage vidéo
- La largeur et la hauteur sont définies dans le groupe "Réglage Vidéo" et propagées à l'extraction de pose et à la génération pour que tout reste aligné.
Remarque : ⚠️ Limite de Résolution : Ce workflow est fixé à 720×1280 (720p). Utiliser une autre résolution entraînera des erreurs de correspondance de dimension à moins que le workflow ne soit reconfiguré manuellement.
WanVideoScheduler(#231) et le contrôleCFGsélectionnent le calendrier de bruit et la force de l'invite. Un CFG plus élevé adhère davantage à l'invite; des valeurs plus basses suivent la pose un peu plus librement mais peuvent réduire les artefacts.VHS_VideoInfoLoaded(#440) lit la fréquence d'images et le nombre de frames du clip source, que la boucle utilise pour déterminer combien de fenêtres One to All Animation sont nécessaires.
Échantillonnage – Partie 1
WanVideoEmptyEmbeds(#99) crée un conteneur pour le conditionnement à la taille cible.WanVideoAddOneToAllReferenceEmbeds(#105) injecte votre image de référence et sonref_maskpour verrouiller l'identité et préserver ou ignorer des zones comme l'arrière-plan ou les vêtements.WanVideoAddOneToAllPoseEmbeds(#98) attache lespose_imagesextraites etpose_prefix_imagepour que le premier segment généré suive le mouvement source dès le premier frame.WanVideoSampler(#27) produit le clip latent initial, qui est décodé parWanVideoDecode(#28) et éventuellement prévisualisé ou enregistré avecVHS_VideoCombine(#139). Il s'agit du segment de graine à étendre.
Boucle
VHS_GetImageCount(#327) etMathExpression|pysssss(#332) calculent combien de passes d'extension sont nécessaires en fonction du nombre total de frames et de la longueur par passe.easy forLoopStart(#329) commence les passes d'extension en utilisant le clip initial comme contexte de départ.
Échantillonnage – Boucle
Extend(#263) est le cœur de l'extension One to All Animation de longue durée. Il recompute le conditionnement avecWanVideoAddOneToAllExtendEmbeds(à l'intérieur du sous-graphe) pour maintenir la continuité à partir des latents précédents, puis échantillonne et décode la fenêtre suivante.ImageBatchExtendWithOverlap(à l'intérieur deExtend) mélange chaque nouvelle fenêtre sur la vidéo accumulée en utilisant une régionoverlap, lissant les frontières et réduisant les coutures temporelles.easy forLoopEnd(#334) ajoute chaque bloc étendu. Le résultat est stocké viaSet_video_OneToAllAnimation(#386) pour exportation.
Export
VHS_VideoCombine(#344) écrit la vidéo finale, utilisant la fréquence d'images source et l'audio optionnel deVHS_LoadVideo. Si vous préférez un résultat silencieux, omettez ou coupez l'entrée audio ici.
Nœuds clés dans le workflow One to All Animation de Comfyui#
PoseDetectionOneToAllAnimation (#141)
- Détecte le sujet et estime les points clés de tout le corps qui guident la pose. Soutenu par YOLOv10 et ViTPose, il est robuste aux mouvements rapides et à l'occlusion partielle. Si votre sujet dérive ou si des scènes à plusieurs personnes confondent le détecteur, recadrez votre entrée ou passez aux poids ViTPose-H de plus grande capacité liés ci-dessus.
WanVideoAddOneToAllReferenceEmbeds (#105)
- Fusionne une image de référence et
ref_maskdans le conditionnement pour que l'identité, la tenue ou les régions protégées restent stables à travers les frames. Les masques serrés préservent les visages et les cheveux; les masques larges peuvent verrouiller les arrière-plans. Lors du changement de look, échangez la référence et gardez le même mouvement.
WanVideoAddOneToAllPoseEmbeds (#98)
- Lie les cartes de pose et une pose de préfixe aux embeddings One to All Animation. Pour une chorégraphie plus stricte, augmentez l'influence de la pose; pour une interprétation plus libre, réduisez-la légèrement. Combinez avec les LoRAs lorsque vous souhaitez une texture cohérente tout en correspondant au mouvement.
WanVideoSampler (#27)
- Le principal échantillonneur vidéo qui transforme les embeddings et le texte en le clip latent initial.
cfgcontrôle l'adhérence à l'invite, etscheduleréchange qualité, vitesse et stabilité. Utilisez la même famille d'échantillonneurs ici et dans la boucle pour éviter les scintillements.
Extend (#263)
- Un sous-graphe compact qui effectue l'extension à fenêtre glissante avec chevauchement. Le réglage
overlapest le cadran clé : plus de chevauchement mélange les transitions plus doucement au coût de calcul supplémentaire; moins de chevauchement est plus rapide mais peut révéler des coutures. Ce nœud réutilise également les latents précédents pour garder la scène et le personnage cohérents à travers les fenêtres.
VHS_VideoCombine (#344)
- Multiplexage final et sauvegarde. Réglez le
frame_rateà partir du fps détecté pour garder le timing du mouvement fidèle à votre source. Vous pouvez couper ou boucler en post, mais exporter à la cadence originale préserve le ressenti de la performance.
Extras optionnels#
- Notes d'installation pour les préprocesseurs. Les nœuds d'extraction de pose proviennent de l'add-on communautaire. Voir le dépôt pour la configuration et le placement ONNX. ComfyUI-WanAnimatePreprocess
- Préférez ViTPose-H pour les mouvements difficiles. Passez à ViTPose-H lorsque les mains/pieds sont rapides ou partiellement occultés; téléchargez à la fois le modèle et son fichier de données à partir des pages liées ci-dessus.
- Réglage pour les longues exécutions. Si vous atteignez les limites de VRAM, réduisez la longueur de fenêtre par passe ou simplifiez les piles LoRA. Le chevauchement peut alors être légèrement augmenté pour garder les transitions propres.
- Forte rétention d'identité. Utilisez une référence de haute qualité, de face, et peignez un
ref_maskprécis pour protéger le visage, les cheveux ou la tenue. C'est crucial pour les longues séquences One to All Animation. - Les séquences propres aident. Une vitesse d'obturation élevée, un éclairage cohérent et un sujet de premier plan clair amélioreront considérablement le suivi des poses et réduiront le tremblement dans les sorties One to All Animation.
- Utilitaires vidéo. L'exportateur et les nœuds d'aide proviennent de Video Helper Suite. Si vous souhaitez un contrôle supplémentaire sur les codecs ou les aperçus, consultez la documentation du projet. Video Helper Suite
Remerciements#
Ce workflow met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Innovate Futures @ Benji pour le tutoriel de workflow One to All Animation et ssj9596 pour le projet One-to-All Animation pour leurs contributions et maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Innovate Futures @ Benji/One to All Animation Source
- GitHub: ssj9596/One-to-All-Animation
- Hugging Face: MochunniaN1/One-to-All-1.3b_1
- arXiv: 2511.22940
- Docs / Release Notes: Patreon post
Remarque : L'utilisation des modèles, ensembles de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.

