






Édition et composition multi-image Nunchaku Qwen Image pour ComfyUI#
Nunchaku Qwen Image est un workflow d'édition et de composition multi-image basé sur des instructions pour ComfyUI. Il accepte jusqu'à trois images de référence, vous permet de spécifier comment elles doivent être mélangées ou transformées, et produit un résultat cohérent guidé par le langage naturel. Les cas d'utilisation typiques incluent la fusion de sujets, le remplacement d'arrière-plans ou le transfert de styles et de détails d'une image à une autre.
Construit autour de la famille d'images Qwen, ce workflow donne aux artistes, designers et créateurs un contrôle précis tout en restant rapide et prévisible. Il inclut également une route d'édition d'image unique et une route de texte à image pure, pour que vous puissiez générer, affiner et composer au sein d'un seul pipeline Nunchaku Qwen Image.
Note : Veuillez sélectionner des types de machines dans la gamme de Medium à 2XLarge. L'utilisation de types de machines 2XLarge Plus ou 3XLarge n'est pas prise en charge et entraînera un échec d'exécution.
Modèles clés dans le workflow Comfyui Nunchaku Qwen Image#
- Nunchaku Qwen Image Edit 2509. Poids de diffusion/DiT optimisés pour l'édition d'images guidée par instructions et le transfert d'attributs. Fort pour les éditions localisées, les échanges d'objets et les changements d'arrière-plan. Model card
- Nunchaku Qwen Image (base). Générateur de base utilisé par la branche de texte à image pour la synthèse créative sans photo source. Model card
- Qwen2.5‑VL 7B encodeur de texte. Modèle de langage multimodal qui interprète les instructions et les aligne avec les caractéristiques visuelles pour l'édition et la génération. Model page
- Qwen Image VAE. Autoencodeur variationnel utilisé pour encoder les images sources en latents et décoder les résultats finaux avec des couleurs et des détails fidèles. Assets
Comment utiliser le workflow Comfyui Nunchaku Qwen Image#
Ce graphe contient trois routes indépendantes qui partagent le même langage visuel et logique d'échantillonnage. Utilisez une branche à la fois selon que vous éditez plusieurs images, affinez une seule image, ou générez à partir de texte.
Nunchaku‑qwen‑image‑edit‑2509 (édition et composition multi-image)#
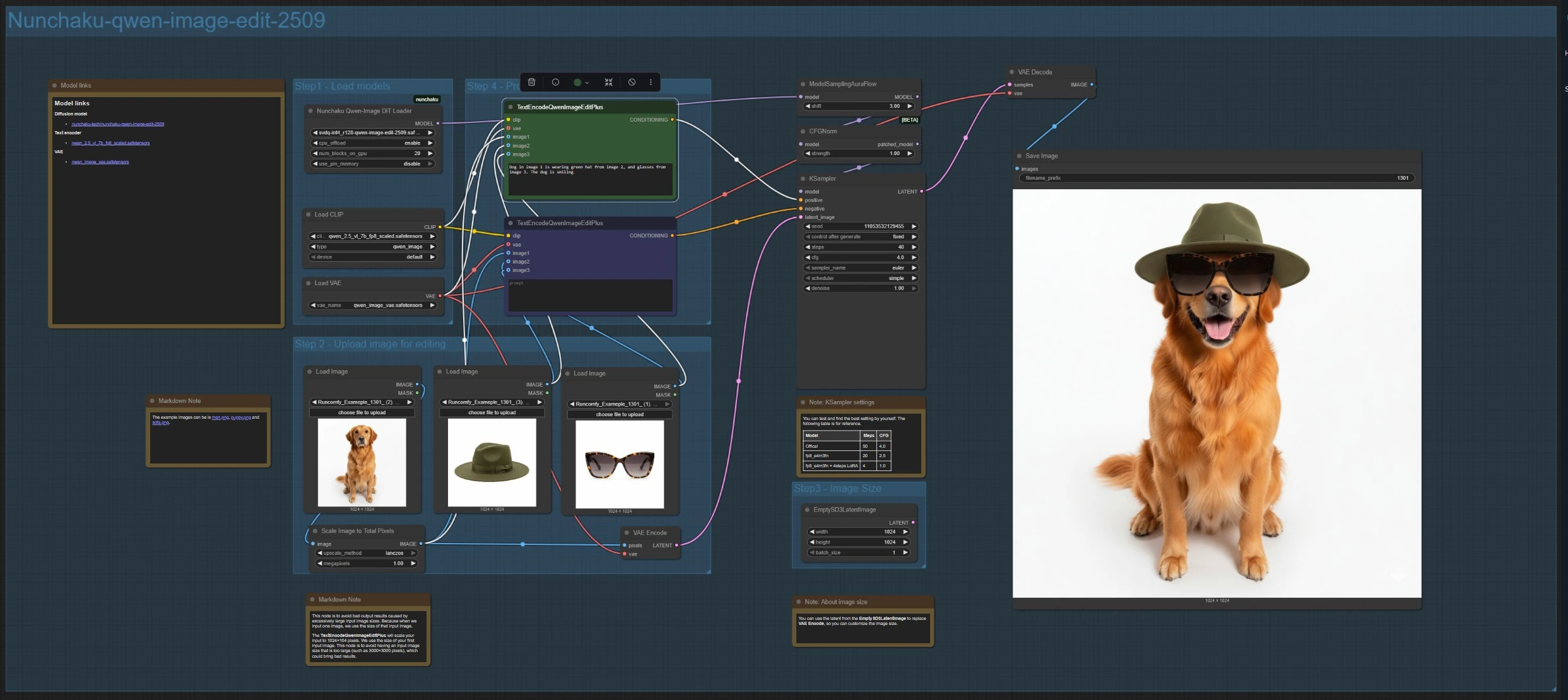
Cette branche charge le modèle d'édition avec NunchakuQwenImageDiTLoader (#115), le dirige à travers ModelSamplingAuraFlow (#66) et CFGNorm (#75), puis synthétise avec KSampler (#3). Téléchargez jusqu'à trois images en utilisant LoadImage (#78, #106, #108). La référence principale est encodée par VAEEncode (#88) pour définir la toile, et ImageScaleToTotalPixels (#93) garde les entrées dans une plage de taille stable.
Écrivez votre instruction dans TextEncodeQwenImageEditPlus (#111) et, si besoin, placez des suppressions ou des contraintes dans le TextEncodeQwenImageEditPlus (#110) associé. Référez-vous explicitement aux sources, par exemple : "Le chien de l'image 1 porte le chapeau vert de l'image 2 et les lunettes de l'image 3." Pour une taille de sortie personnalisée, vous pouvez remplacer le latent encodé par EmptySD3LatentImage (#112). Les résultats sont décodés par VAEDecode (#8) et sauvegardés avec SaveImage (#60).
Nunchaku‑qwen‑image‑edit (raffinage d'image unique)#
Choisissez ceci lorsque vous souhaitez des nettoyages ciblés, des changements d'arrière-plan ou des ajustements de style sur une image. Le modèle est chargé par NunchakuQwenImageDiTLoader (#120), adapté par ModelSamplingAuraFlow (#125) et CFGNorm (#123), et échantillonné par KSampler (#127). Importez votre photo avec LoadImage (#129); elle est normalisée par ImageScaleToTotalPixels (#130) et encodée par VAEEncode (#131).
Fournissez votre instruction dans TextEncodeQwenImageEdit (#121) et un contre-guidage optionnel dans TextEncodeQwenImageEdit (#122) pour garder ou supprimer des éléments. La branche décode avec VAEDecode (#124) et écrit les fichiers via SaveImage (#128).
Nunchaku‑qwen‑image (texte à image)#
Utilisez cette branche pour créer de nouvelles images à partir de zéro avec le modèle de base. NunchakuQwenImageDiTLoader (#146) alimente ModelSamplingAuraFlow (#138). Entrez vos instructions positives et négatives dans CLIPTextEncode (#143) et CLIPTextEncode (#137). Définissez votre toile avec EmptySD3LatentImage (#136), puis générez avec KSampler (#141), décodez en utilisant VAEDecode (#142), et sauvegardez avec SaveImage (#147).
Nœuds clés dans le workflow Comfyui Nunchaku Qwen Image#
NunchakuQwenImageDiTLoader (#115) Charge les poids d'image Qwen et la variante utilisée par la branche. Sélectionnez le modèle d'édition pour les éditions guidées par photo ou le modèle de base pour le texte à image. Lorsque la VRAM le permet, des variantes de plus haute précision ou de plus haute résolution peuvent offrir plus de détails; les variantes plus légères privilégient la vitesse.
TextEncodeQwenImageEditPlus (#111) Conduit les éditions multi-image en analysant votre instruction et en la liant à jusqu'à trois références. Gardez les directives explicites sur quelle image contribue à quel attribut. Utilisez des phrases concises et évitez les objectifs contradictoires pour garder les éditions concentrées.
TextEncodeQwenImageEditPlus (#110) Agit comme l'encodeur négatif ou de contrainte associé pour la branche multi-image. Utilisez-le pour exclure des objets, styles, ou artefacts que vous ne souhaitez pas voir apparaître. Cela aide souvent à préserver la composition tout en supprimant les superpositions d'interface utilisateur ou les accessoires indésirables.
TextEncodeQwenImageEdit (#121) Instruction positive pour la branche d'édition d'image unique. Décrivez le résultat souhaité, les qualités de surface, et la composition en termes clairs. Visez une à trois phrases qui spécifient la scène et les changements.
TextEncodeQwenImageEdit (#122) Invite négative ou de contrainte pour la branche d'édition d'image unique. Listez les éléments ou caractéristiques à éviter, ou décrivez les éléments à supprimer de l'image source. Ceci est utile pour nettoyer le texte errant, les logos, ou les éléments d'interface.
ImageScaleToTotalPixels (#93) Empêche les entrées surdimensionnées de déstabiliser les résultats en redimensionnant à un nombre total de pixels cible. Utilisez-le pour harmoniser les résolutions sources disparates avant de composer. Si vous remarquez une netteté incohérente entre les sources, rapprochez-les en taille effective ici.
ModelSamplingAuraFlow (#66) Applique un calendrier d'échantillonnage DiT/flow-matching ajusté pour les modèles d'image Qwen. Si les sorties semblent sombres, floues, ou manquent de structure, augmentez le décalage du calendrier pour stabiliser le ton global; si elles semblent plates, réduisez le décalage pour rechercher des détails supplémentaires.
KSampler (#3) Le principal échantillonneur où vous équilibrez la vitesse, la fidélité, et la variété stochastique. Ajustez les étapes et l'échelle de guidage pour la cohérence contre la créativité, choisissez une méthode d'échantillonnage, et verrouillez une graine lorsque vous souhaitez une reproductibilité exacte entre les exécutions.
CFGNorm (#75) Normalise le guidage sans classificateur pour réduire la sursaturation ou les explosions de contraste à des échelles de guidage plus élevées. Laissez-le sur le chemin tel que fourni; il aide à maintenir une couleur et une exposition stables pendant que vous itérez sur les instructions.
Suppléments optionnels#
- Pour de meilleurs résultats multi-image, choisissez des sources avec une perspective et un éclairage similaires; le modèle d'édition Nunchaku Qwen Image se concentrera alors sur le contenu plutôt que de corriger la géométrie.
- Référez-vous aux sources par ordre ("image 1", "image 2", "image 3") et soyez explicite sur quels attributs sont transférés où.
- Lorsque les sorties penchent vers le sombre ou le flou, ajustez le décalage de
ModelSamplingAuraFlowvers le haut; lorsque vous voulez une texture supplémentaire, essayez un décalage légèrement plus bas. - Pour définir une résolution spécifique, échangez le latent encodé pour
EmptySD3LatentImagedans la branche que vous utilisez. - Utilisez des instructions négatives pour supprimer le texte de l'interface utilisateur, les filigranes, ou les objets indésirables avant d'investir dans le style détaillé; cela maintient les éditions Nunchaku Qwen Image propres dès le départ.
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Nunchaku pour le workflow Qwen-Image (ComfyUI-nunchaku) pour leurs contributions et leur maintenance. Pour des détails autorisés, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Nunchaku/Qwen-Image
- GitHub: nunchaku-tech/ComfyUI-nunchaku
- Hugging Face: nunchaku-tech/nunchaku-qwen-image
- arXiv: SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
- Docs / Release Notes: Nunchaku Qwen Image Source
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et termes respectifs fournis par leurs auteurs et mainteneurs.




