
LTX-2 ComfyUI : texte, image, profondeur et pose en temps réel vers vidéo avec audio synchronisé#
Ce workflow tout-en-un LTX-2 ComfyUI vous permet de générer et d'itérer sur de courtes vidéos avec audio en quelques secondes. Il est livré avec des routes pour texte vers vidéo (T2V), image vers vidéo (I2V), profondeur vers vidéo, pose vers vidéo, et canny vers vidéo, vous pouvez donc commencer à partir d'une invite, d'une image fixe, ou d'une guidance structurée et garder la même boucle créative.
Construit autour du pipeline AV à faible latence de LTX-2 et du parallélisme séquentiel multi-GPU, le graphe met l'accent sur un retour rapide. Décrivez le mouvement, la caméra, l'apparence et le son une fois, puis ajustez la largeur, la hauteur, le nombre de frames, ou contrôlez les LoRAs pour affiner le résultat sans rien re-câbler.
Note : Note sur la compatibilité du workflow LTX-2 — LTX-2 inclut 5 workflows : Texte-vers-Vidéo et Image-vers-Vidéo fonctionnent sur tous les types de machines, tandis que Profondeur vers Vidéo, Canny vers Vidéo, et Pose vers Vidéo nécessitent une machine 2X-Large ou plus grande ; exécuter ces workflows ControlNet sur des machines plus petites peut entraîner des erreurs.
Modèles clés dans le workflow LTX-2 ComfyUI#
- LTX-2 19B (dev FP8) checkpoint. Modèle génératif audio-visuel central qui produit des frames vidéo et un audio synchronisé à partir d'un conditionnement multimodal. Lightricks/LTX-2
- Checkpoint LTX-2 19B Distillé. Variante plus légère et rapide utile pour des brouillons rapides ou des exécutions contrôlées par canny. Lightricks/LTX-2
- Encodeur de texte Gemma 3 12B IT. Colonne vertébrale principale de compréhension du texte utilisée par les encodeurs d'invites du workflow. Comfy-Org/ltx-2 split files
- LTX-2 Spatial Upscaler x2. Suréchantillonneur latent qui double le détail spatial en milieu de graphe pour des sorties plus propres. Lightricks/LTX-2
- VAE Audio LTX-2. Encode et décode les latents audio pour que le son puisse être généré et multiplexé avec la vidéo. Inclus avec la version LTX-2 ci-dessus.
- Lotus Depth D v1‑1. UNet de profondeur utilisé pour dériver des cartes de profondeur robustes à partir d'images avant la génération de vidéo guidée par profondeur. Comfy‑Org/lotus
- SD VAE (MSE, EMA élagué). VAE utilisé dans la branche préprocesseur de profondeur. stabilityai/sd-vae-ft-mse-original
- LoRAs de contrôle pour LTX‑2. LoRAs optionnels, plug‑and‑play pour diriger le mouvement et la structure :
Comment utiliser le workflow LTX-2 ComfyUI#
Le graphe contient cinq routes que vous pouvez exécuter indépendamment. Toutes les routes partagent le même chemin d'exportation et utilisent la même logique d'invite-à-conditionnement, donc une fois que vous en maîtrisez une, les autres semblent familières.
T2V : générer vidéo et audio à partir d'une invite#
Le chemin T2V commence par CLIP Text Encode (Prompt) (#3) et un négatif optionnel dans CLIP Text Encode (Prompt) (#4). LTXVConditioning (#22) lie votre texte et le taux de frames choisi au modèle. EmptyLTXVLatentVideo (#43) et LTX LTXV Empty Latent Audio (#26) créent des latents vidéo et audio qui sont fusionnés par LTX LTXV Concat AV Latent (#28). La boucle de débruitage passe par LTXVScheduler (#9) et SamplerCustomAdvanced (#41), après quoi VAE Decode (#12) et LTX LTXV Audio VAE Decode (#14) produisent des frames et de l'audio. Video Combine 🎥🅥🅗🅢 (#15) sauvegarde un MP4 H.264 avec son synchronisé.
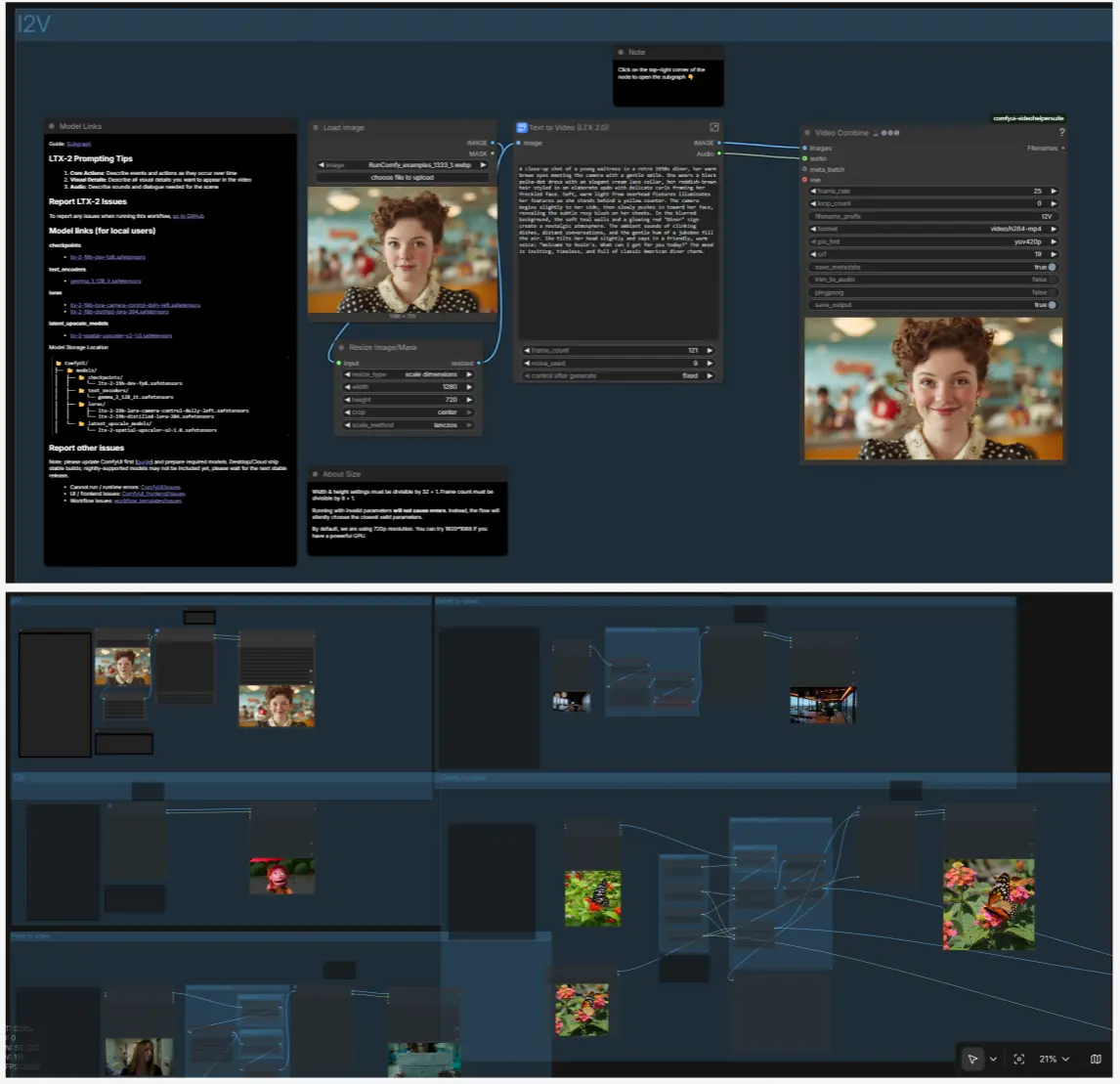
I2V : animer une image fixe#
Chargez une image fixe avec LoadImage (#98) et redimensionnez avec ResizeImageMaskNode (#99). À l'intérieur du sous-graphe T2V, LTX LTXV Img To Video Inplace injecte le premier frame dans la séquence latente pour que le mouvement se construise à partir de votre image fixe plutôt que de bruit pur. Gardez votre invite textuelle centrée sur le mouvement, la caméra, et l'ambiance ; le contenu vient de l'image.
Profondeur vers vidéo : mouvement conscient de la structure à partir de cartes de profondeur#
Utilisez le préprocesseur “Image to Depth Map (Lotus)” pour transformer une entrée en une image de profondeur, décodée par VAEDecode et éventuellement inversée pour une polarité correcte. La route “Depth to Video (LTX 2.0)” alimente ensuite la guidance de profondeur via LTX LTXV Add Guide pour que le modèle respecte la structure globale de la scène pendant qu'il anime. Le chemin réutilise les mêmes étapes de scheduler, sampler, et upscaler, et se termine par un décodage en mosaïque vers des images et de l'audio multiplexé pour l'export.
Pose vers vidéo : diriger le mouvement à partir de la pose humaine#
Importez un clip avec VHS_LoadVideo (#198) ; DWPreprocessor (#158) estime de manière fiable la pose humaine à travers les frames. Le sous-graphe “Pose to Video (LTX 2.0)” combine votre invite, le conditionnement de la pose, et une LoRA de contrôle de pose optionnelle pour garder les membres, l'orientation, et les battements cohérents tout en permettant au style et à l'arrière-plan de s'écouler à partir du texte. Utilisez ceci pour des danses, des cascades simples, ou des prises de parole où le timing corporel est important.
Canny vers vidéo : animation fidèle aux contours et mode de vitesse distillé#
Alimentez des frames à Canny (#169) pour obtenir une carte de contours stable. La branche “Canny to Video (LTX 2.0)” accepte les contours plus une LoRA de contrôle Canny optionnelle pour une haute fidélité aux silhouettes, tandis que “Canny to Video (LTX 2.0 Distilled)” offre un checkpoint distillé plus rapide pour des itérations rapides. Les deux variantes vous permettent d'injecter éventuellement le premier frame et de choisir la force de l'image, puis d'exporter soit via CreateVideo soit VHS_VideoCombine.
Paramètres vidéo et exportation#
Réglez la largeur et la hauteur via Width (#175) et height (#173), le nombre total de frames avec Frame Count (#176), et activez Enable First Frame (#177) si vous souhaitez verrouiller une référence initiale. Utilisez les nœuds VHS_VideoCombine à la fin de chaque route pour contrôler crf, frame_rate, pix_fmt, et la sauvegarde des métadonnées. Un SaveVideo (#180) dédié est fourni pour la route canny distillée lorsque vous préférez une sortie VIDÉO directe.
Performance et multi-GPU#
Le graphe applique LTXVSequenceParallelMultiGPUPatcher (#44) avec torch_compile activé pour diviser les séquences sur les GPUs pour une latence plus faible. KSamplerSelect (#8) vous permet de choisir entre les samplers incluant les styles d'estimation d'Euler et de gradient ; des comptes de frames plus petits et des étapes plus faibles réduisent le délai d'exécution pour que vous puissiez itérer rapidement et augmenter l'échelle lorsque vous êtes satisfait.
Nœuds clés dans le workflow LTX-2 ComfyUI#
LTX Multimodal Guider(#17). Coordonne comment le conditionnement textuel dirige à la fois les branches vidéo et audio. Ajustezcfgetmodalitydans lesLTX Guider Parametersliés (#18 pour VIDÉO, #19 pour AUDIO) pour équilibrer fidélité et créativité ; augmentezcfgpour une adhésion plus stricte à l'invite et augmentezmodality_scalepour mettre l'accent sur une branche spécifique.LTXVScheduler(#9). Construit un planning sigma adapté à l'espace latent de LTX‑2. Utilisezstepspour échanger vitesse contre qualité ; lors du prototypage, moins d'étapes réduisent la latence, puis augmentez les étapes pour les rendus finaux.SamplerCustomAdvanced(#41). Le débruiteur qui lieRandomNoise, le sampler choisi deKSamplerSelect(#8), les sigmas du scheduler, et le latent AV. Changez de samplers pour différentes textures de mouvement et comportements de convergence.LTX LTXV Img To Video Inplace(voir les branches I2V, par exemple, #107). Injecte une image dans un latent vidéo pour que le premier frame ancre le contenu pendant que le modèle synthétise le mouvement. Ajustezstrengthpour déterminer à quel point le premier frame est préservé.LTX LTXV Add Guide(dans les routes guidées, par exemple, profondeur/pose/canny). Ajoute un guide structurel (image, pose, ou contours) directement dans l'espace latent. Utilisezstrengthpour équilibrer la fidélité du guide avec la liberté générative et activez le premier frame uniquement lorsque vous souhaitez un ancrage temporel.Video Combine 🎥🅥🅗🅢(#15 et ses semblables). Emballe les frames décodées et l'audio généré en MP4. Pour les aperçus, augmentezcrf(plus de compression) ; pour les finales, réduisezcrfet confirmez queframe_ratecorrespond à ce que vous avez défini dans le conditionnement.LTXVSequenceParallelMultiGPUPatcher(#44). Active l'inférence parallèle de séquence avec des optimisations de compilation. Laissez-le activé pour le meilleur débit ; désactivez-le uniquement lors du débogage de l'emplacement des appareils.
Extras optionnels#
- Conseils pour l'invite pour LTX-2 ComfyUI
- Décrivez les actions principales au fil du temps, pas seulement l'apparence statique.
- Spécifiez les détails visuels importants que vous devez voir dans la vidéo.
- Écrivez la bande sonore : ambiance, bruitages, musique, et tout dialogue.
- Règles de dimensionnement et taux de frames
- Utilisez une largeur et une hauteur qui sont des multiples de 32 (par exemple 1280×720).
- Utilisez des comptes de frames qui sont des multiples de 8 (121 dans ce modèle est une bonne longueur).
- Gardez le taux de frames cohérent là où il apparaît ; le graphe inclut à la fois des cases flottantes et entières et elles doivent correspondre.
- Guidance LoRA
- Les LoRAs de caméra, profondeur, pose, et canny sont intégrés ; commencez avec une force de 1 pour les mouvements de caméra, puis ajoutez une deuxième LoRA uniquement lorsque nécessaire. Parcourez la collection officielle sur Lightricks/LTX‑2.
- Itérations plus rapides
- Réduisez le nombre de frames, réduisez les étapes dans
LTXVScheduler, et essayez le checkpoint distillé pour la route canny. Lorsque le mouvement fonctionne, augmentez la résolution et les étapes pour les finales.
- Réduisez le nombre de frames, réduisez les étapes dans
- Reproductibilité
- Verrouillez
noise_seeddans les nœuds Random Noise pour obtenir des résultats reproductibles pendant que vous ajustez les invites, les tailles, et les LoRAs.
- Verrouillez
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Lightricks pour le modèle de génération vidéo multimodal LTX-2 et la base de code de recherche LTX-Video, ainsi que Comfy Org pour les nœuds/partenariats LTX-2 ComfyUI, pour leurs contributions et leur maintenance. Pour des détails autoritatifs, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Comfy Org/LTX-2 maintenant disponible dans ComfyUI !
- GitHub : Lightricks/LTX-Video
- Hugging Face : Lightricks/LTX-Video-ICLoRA-detailer-13b-0.9.8
- arXiv : 2501.00103
- Docs / Notes de version : LTX-2 Now Available in ComfyUI!
Note : L'utilisation des modèles, ensembles de données, et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.