
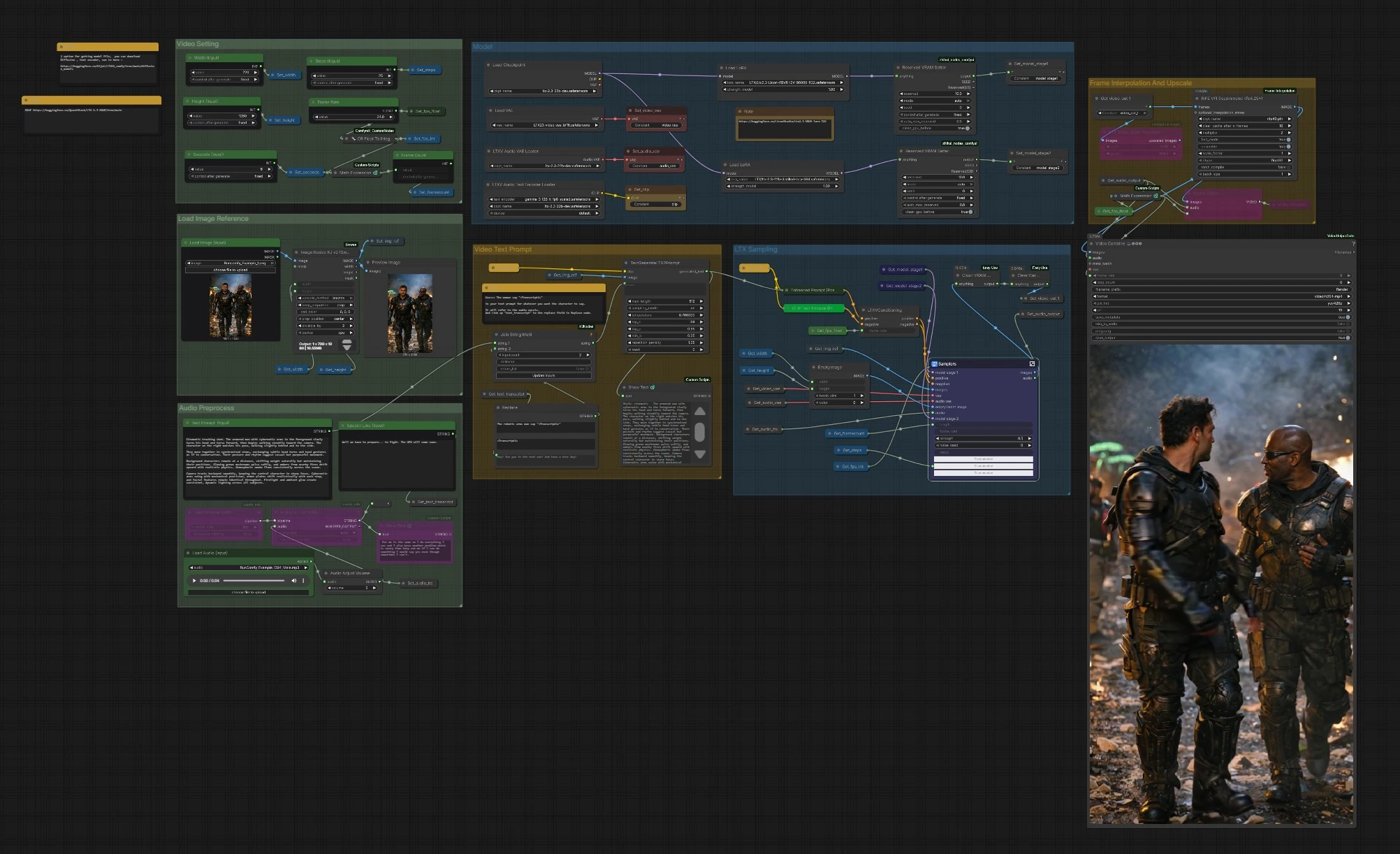
Flux de travail LTX 2.3 VBVR ComfyUI : image-à-vidéo conscient du raisonnement avec dialogue#
Ce flux de travail transforme une seule image de référence en une séquence vidéo cohérente guidée par du texte et un discours facultatif, alimentée par LTX‑2.3 et le LTX 2.3 VBVR LoRA. VBVR signifie raisonnement visuel basé sur la vidéo : il aide le modèle à conserver les identités, les relations spatiales, et la cohérence cause‑à‑effet entre les images afin que vos scènes paraissent intentionnelles plutôt qu'aléatoires. Le graphe inclut une incitation consciente du discours, un échantillonnage LTX en deux étapes, un lissage du mouvement, et une mise à l'échelle/exportation finale en MP4.
Les créateurs qui ont besoin de continuité narrative, de mouvement crédible, ou de synchronisation de dialogue trouveront le flux de travail LTX 2.3 VBVR particulièrement utile. Fournissez une image de référence forte, décrivez l'action et les interactions, et insérez éventuellement une ligne parlée qui est transcrite automatiquement et intégrée dans l'invite pour un meilleur alignement des lèvres et du timing.
Modèles clés dans le flux de travail Comfyui LTX 2.3 VBVR#
- Modèle de génération vidéo LTX‑2.3 22B de Lightricks, l'épine dorsale de diffusion principale pour le décodage image-à-vidéo et conditionné par l'audio. Hugging Face: Lightricks/LTX-2.3
- LTX‑2.3 Video VAE pour l'encodage/décodage des latents vidéo, associé au point de contrôle de base pour un décodage carrelé efficace. Hugging Face: Lightricks/LTX-2.3
- Modèle latent d'agrandissement spatial LTX‑2.3 x2 pour améliorer le détail spatial après le premier passage. Hugging Face: Lightricks/LTX-2.3
- Encodeur de texte Gemma 3 12B emballé pour LTX‑2, utilisé ici pour analyser des instructions complexes et des jetons de dialogue. Hugging Face: Comfy-Org/ltx-2
- LTX 2.3 VBVR LoRA pour la structure de scène centrée sur le raisonnement, l'interaction des objets, et la continuité dans le temps. Hugging Face: LiconStudio/Ltx2.3-VBVR-lora-I2V
- Modèle d'interpolation de trames RIFE pour lisser le mouvement entre les images générées. GitHub: hzwer/Practical-RIFE
- Modèle de reconnaissance vocale Whisper pour l'infusion facultative de l'audio au texte dans l'invite. GitHub: openai/whisper
Comment utiliser le flux de travail Comfyui LTX 2.3 VBVR#
Le graphe est organisé en groupes clairs. Vous configurez les entrées, la pile de modèles, et les paramètres vidéo, puis les échantillonneurs LTX génèrent des images qui sont éventuellement interpolées et mises à l'échelle avant l'exportation.
Charger l'image de référence#
Utilisez Load Image (Input) (#5525) pour choisir une image de référence forte et stylée. L'image est redimensionnée par ImageResizeKJv2 (#5280) à la largeur et à la hauteur choisies tout en préservant la composition. Un nœud de prévisualisation confirme ce que le modèle verra réellement. De bonnes images de référence avec des sujets clairs et un éclairage donnent à la pile LTX 2.3 VBVR un ancrage fiable pour l'identité et le style.
Paramètres vidéo#
Définissez Width (Input) (#5284), Height (Input) (#5286), Seconds (Input) (#5573), et le Frame Rate de base (#5289). Le graphe calcule automatiquement le nombre d'images pour que le timing reste cohérent lorsque vous modifiez la durée ou les fps. Si vous prévoyez d'activer l'interpolation plus tard, vous pouvez choisir un fps de base modeste pour gagner du temps et laisser RIFE ajouter de la fluidité. Ces paramètres informent également le nœud de conditionnement pour que le mouvement et le rythme restent cohérents.
Modèle#
CheckpointLoaderSimple (#5493) charge LTX‑2.3. Le graphe attache le LTX 2.3 VBVR LoRA via LoraLoaderModelOnly (#5616) et peut éventuellement appliquer un LoRA distillé et un LoRA detailer pour une fidélité supplémentaire. LTXAVTextEncoderLoader (#5494) intègre l'encodeur de texte basé sur Gemma, tandis que VAELoader (#5629) et LTXVAudioVAELoader (#5492) fournissent les VAE vidéo et audio. Deux nœuds ReservedVRAMSetter équilibrent l'utilisation de la mémoire pour que les longues exécutions restent stables.
Invite de texte vidéo#
Écrivez votre scène dans Text Prompt (Input) (#5620). Pour injecter un dialogue aligné avec l'audio, incluez un espace réservé comme : La femme dit "<Transcript1>". Alimentez la ligne réelle dans Speech Line (Input) (#5524) ou laissez Whisper la produire à partir de l'audio; StringReplace (#5226) et JoinStringMulti (#5602) remplacent <Transcript1> par la transcription. TextGenerateLTX2Prompt (#5488) compose ensuite une instruction raffinée, que Enhanced Prompt (Positive) (#5174) encode avant que LTXVConditioning (#5173) prépare la guidance finale. Des verbes clairs, des références de sujet, et des indices spatiaux donnent au LTX 2.3 VBVR LoRA le contexte dont il a besoin pour raisonner dans le temps.
Prétraitement audio#
Apportez une piste vocale avec Load Audio (Input) (#5590) ou connectez TTS. AudioAdjustVolume (#5601) normalise les niveaux. Si vous souhaitez un dialogue conscient de l'invite, utilisez Whisper via Load Whisper (mtb) (#5606) et Audio To Text (mtb) (#5607) pour générer la transcription utilisée dans l'invite. Le même audio est également encodé en tant que latent et plus tard multiplexé dans la vidéo finale pour que les indices de lèvres et de timing puissent influencer la génération.
Échantillonnage LTX#
LTXVPreprocess (#5240) et LTXVImgToVideoInplace (#5245) convertissent votre image de référence en une séquence latente initiale, préservant l'identité de base tout en permettant le mouvement. Le sous-graphe Samplers (#5278) exécute un processus en deux étapes avec des guiders CFG et un planificateur, produisant des latents spatio-temporels qui respectent à la fois votre invite et le raisonnement LTX 2.3 VBVR LoRA. Les latents audio sont concaténés avec les latents vidéo pour que le timing du discours puisse informer le mouvement. LTXVSpatioTemporalTiledVAEDecode (#5237) décode les images, et LTXVAudioVAEDecode (#5103) restaure la piste audio.
Interpolation et mise à l'échelle des images#
RIFE VFI (#5554) interpole entre les images pour créer un mouvement plus fluide et pour atteindre votre taux de lecture cible lorsqu'il est combiné avec le fps de base. RTXVideoSuperResolution (#5631) améliore le détail et réduit les artefacts de compression, améliorant la lisibilité des visages, des bords, et des petits accessoires. Utilisez cette étape pour équilibrer la vitesse et la qualité : interpolez pour la fluidité, puis mettez à l'échelle pour la netteté.
Exportation#
Choisissez entre CreateVideo (#5599) pour un simple multiplexage ou VHS_VideoCombine (#5618) pour plus de contrôle sur le format, les métadonnées, et le découpage. Le pipeline écrit un H.264 MP4 via SaveVideo (#5597). Le taux de trame est dérivé de vos paramètres et de l'étape d'interpolation pour que la lecture corresponde à l'intention de mouvement que vous avez créée au départ.
Nœuds clés dans le flux de travail Comfyui LTX 2.3 VBVR#
LoraLoaderModelOnly (#5616)#
Charge le LTX 2.3 VBVR LoRA qui améliore la continuité logique, l'interaction des objets, et le mouvement conscient de la caméra. Ajustez le poids du LoRA pour équilibrer l'influence du raisonnement avec le style du modèle de base et d'autres LoRAs. Ce nœud est central pour l'apparence distincte et la cohérence qui définissent le flux de travail LTX 2.3 VBVR. Pour l'utilisation des nœuds LTX et LoRA, voir Lightricks/ComfyUI-LTXVideo et la carte VBVR LoRA ci-dessus.
TextGenerateLTX2Prompt (#5488)#
Assemble l'invite positive finale en fusionnant votre description de base, l'image de référence, et le jeton de dialogue remplacé de <Transcript1>. Gardez les instructions concises, explicites, et cohérentes sur les sujets et les actions pour que le modèle puisse raisonner dans le temps. C'est ici que vous encodez l'intention que le LTX 2.3 VBVR LoRA renforcera lors de l'échantillonnage.
LTXVConditioning (#5173)#
Emballe les conditionnements positifs et négatifs et transmet les informations de timing pour que le mouvement et le rythme s'alignent avec votre choix de fps. Si vous changez le taux de trame dans les paramètres, mettez-le à jour ici pour que la dynamique de mouvement reste cohérente. Des négatifs forts aident à prévenir les images fixes, les filigranes, ou les superpositions indésirables de s'infiltrer dans la séquence.
Samplers (#5278)#
Le bloc d'échantillonneur en deux étapes coordonne le bruit, la guidance, et la planification pour transformer les latents d'image et d'audio en une vidéo cohérente. Les ajustements les plus impactants sont le total des steps, la force de l'image de l'étape initiale I2V, et le noise_seed pour la reproductibilité. Ajustez-les soigneusement pour échanger la fidélité à l'image de référence contre la volonté de suivre de nouveaux mouvements et actions.
RIFE VFI (#5554)#
Interpoles les images pour un mouvement plus fluide ou pour atteindre un fps effectif plus élevé sans régénérer la séquence. Augmentez l'interpolation lorsque votre fps de base est faible ou lorsque le mouvement semble saccadé; diminuez-la pour préserver le rythme génératif original. Le modèle est largement utilisé pour un VFI de haute qualité; voir le projet RIFE sur GitHub.
Extras optionnels#
- Astuce de dialogue avec LTX 2.3 VBVR : écrivez une phrase naturelle avec l'espace réservé, par exemple La femme dit "<Transcript1>", puis fournissez la ligne dans Speech Line ou laissez Whisper transcrire l'audio pour que l'invite et les lèvres s'alignent.
- Incitation au raisonnement : indiquez qui fait quoi, où, et pourquoi. Utilisez des noms de sujets cohérents et des indices temporels tels que alors, tandis que, et lorsque la caméra se déplace pour tirer parti des forces de VBVR.
- Itérations plus rapides : commencez avec une durée plus courte ou un fps de base plus bas, confirmez les temps forts du mouvement, puis augmentez l'interpolation ou les secondes pour terminer.
- Conseils de stabilité : si vous voyez une dérive d'identité, réduisez légèrement la force image-à-vidéo ou augmentez le poids du LoRA VBVR; si vous voyez une sur-contrainte, faites l'inverse.
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement @Benji’s AI Playground pour la source du flux de travail 2.3 VBVR pour leurs contributions et leur maintenance. Pour des détails faisant autorité, veuillez vous référer à la documentation et aux référentiels originaux liés ci-dessous.
Ressources#
- Source du flux de travail LTX/2.3 VBVR
- Docs / Notes de version : Source du flux de travail LTX 2.3 VBVR @Benji’s AI Playground
Remarque : L'utilisation des modèles, jeux de données, et code référencés est soumise aux licences et termes respectifs fournis par leurs auteurs et mainteneurs.
