
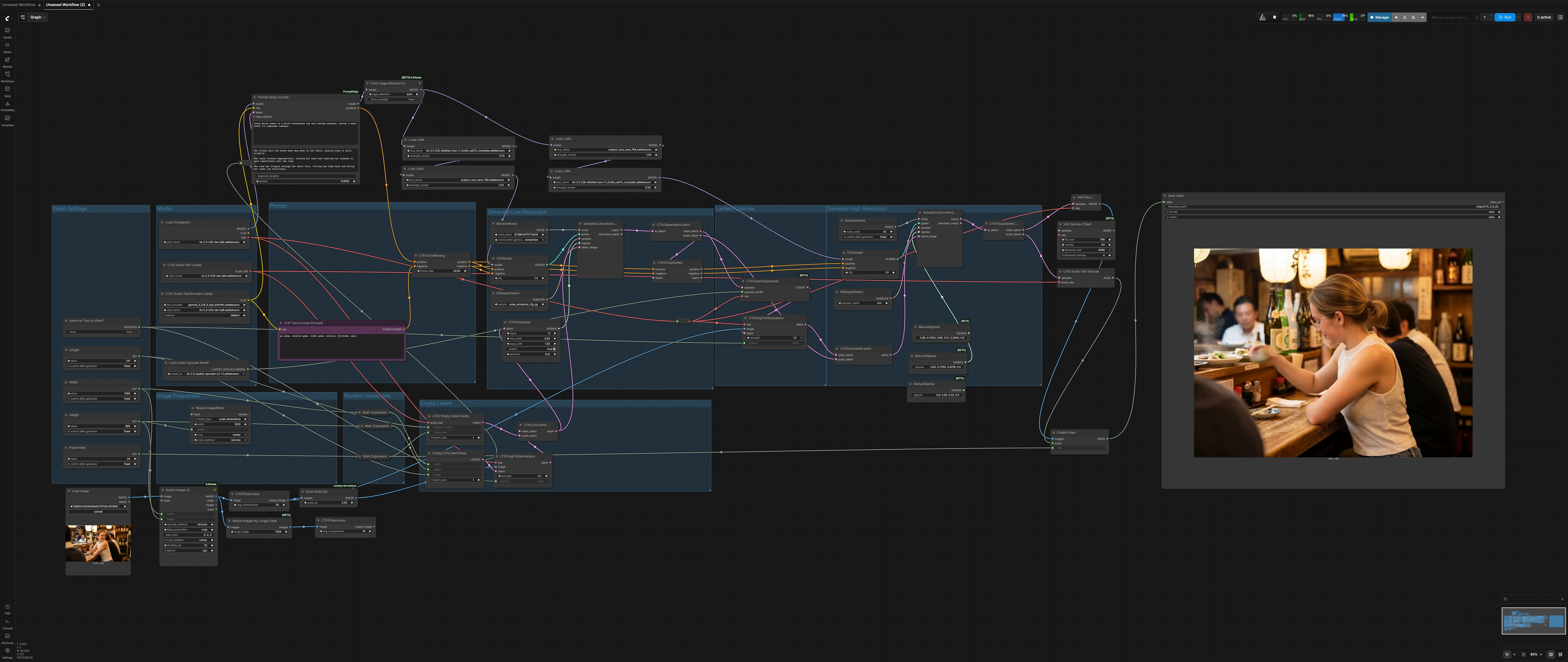
LTX 2.3 Sulphur image to video workflow : image-à-vidéo cinématographique avec mouvement contrôlable#
Ce workflow LTX 2.3 Sulphur image to video transforme une seule image fixe en une prise cinématographique prête à être publiée avec des micro-expressions naturelles, un mouvement de personnage crédible et une continuité atmosphérique stable. Il est conçu pour des prises de vue narratives où vous souhaitez contrôler le ressenti de la caméra, l'ambiance et la dynamique de la scène sans vous perdre dans les détails de configuration.
Le workflow exécute un pipeline de diffusion en deux étapes autour de LTX-2.3 : un passage basse résolution pour établir le mouvement et le timing, suivi d'un upscale latent et d'un passage de raffinement haute résolution pour le détail final. Un style Sulphur LoRA guide l'apparence et les tons de peau, tandis que la segmentation des prompts soutient l'évolution des rythmes à travers la prise. Basculer un seul interrupteur pour exécuter l'image-à-vidéo classique ou le texte-à-vidéo pur selon les besoins.
Modèles clés dans Comfyui LTX 2.3 Sulphur image to video workflow#
- Lightricks LTX-2.3-22B dev FP8. Le point de contrôle de diffusion vidéo de base qui pilote la génération et le décodage tout en gardant l'utilisation de la mémoire pratique. Model card
- LTX-2.3 Spatial Upscaler x2. Un modèle de super-résolution latent utilisé entre les passages pour préserver le mouvement tout en ajoutant de la fidélité spatiale. Model page
- Gemma 3 12B encodeur de texte ajusté par instruction emballé pour LTX-2. Permet un conditionnement riche et ancré pour les prompts globaux et segmentés. Repository
- Style Sulphur LoRA et LTX-2.3 LoRA distillé 1.1. LoRAs jumelés qui stabilisent le réalisme facial et le ton cinématographique tout en conservant le contrôle des prompts.
Comment utiliser Comfyui LTX 2.3 Sulphur image to video workflow#
Flux global : définissez les dimensions et la durée de votre prise, préparez votre image fixe, définissez un prompt global plus des rythmes de prompt locaux optionnels, puis rendez. L'étape basse résolution construit le mouvement et le timing, le upscaler latent ajoute du détail, et l'étape haute résolution finalise la texture et l'éclairage avant le décodage en MP4.
Paramètres vidéo#
Choisissez votre Width, Height, Length (images), et Frame Rate cible. Les dimensions sont définies pour être divisibles par les tailles de grille de diffusion courantes pour éviter les artefacts. Un booléen unique, Switch to Text to Video? (#28), contrôle si l'image fixe est injectée ou contournée. Gardez le ratio d'aspect cohérent avec l'image d'entrée pour un cadrage le plus propre, surtout pour les visages et les mains.
Prétraitement de l'image#
Votre source fixe est chargée, redimensionnée et légèrement compressée pour la diffusion à l'aide de ImageResizeKJv2 (#75) et LTXVPreprocess (#76). Une version mise à l'échelle est transmise au passage basse résolution pour un semis de mouvement stable, tandis que la version à plus haute résolution est disponible pour le passage haute résolution. Utilisez cette section pour aligner le cadrage et la marge avant la génération. Des ajustements subtils de pré-découpage ici se traduisent par des lignes de regard plus cohérentes et une continuité de fond.
Latent Vide#
EmptyLTXVLatentVideo (#21) et LTXVEmptyLatentAudio (#33) construisent des latents vidéo et audio synchronisés en utilisant vos paramètres de prise. Ils sont fusionnés par LTXVConcatAVLatent (#32) pour établir un échafaudage de timeline que les nœuds en aval affineront. La branche audio crée une piste silencieuse et valide pour que le MP4 final joue de manière fiable partout. Ces latents ancrent également les segments de prompt pour que les changements de mouvement atterrissent là où vous vous y attendez.
Prompt#
Écrivez votre description de prise dans PromptRelayEncode (#80). Utilisez un prompt global concis pour l'apparence générale, puis ajoutez des lignes spécifiques au rythme en tant que prompts locaux, séparés par le caractère |, pour faire évoluer les micro-actions à travers le clip. L'encodeur de texte LTX de LTXAVTextEncoderLoader (#5) gère la sémantique, tandis que CLIPTextEncode (#41) fournit un prompt négatif orienté vers le réalisme fort. LTXVConditioning (#31) mélange les conditionnements positif et négatif et les synchronise avec le taux de trame.
Modèle#
CheckpointLoaderSimple (#44) charge le LTX-2.3 de base. PathchSageAttentionKJ (#67) optimise l'attention pour les grandes images. Une courte chaîne LoRA applique le style Sulphur et une stabilité LoRA distillée avant chaque étape d'échantillonnage. Cette conception équilibre la cohérence de l'apparence avec la réactivité des prompts pour que l'identité du personnage et l'éclairage restent cohérents entre les passages.
Générer basse résolution#
Ce premier passage de diffusion établit le mouvement. LTXVImgToVideoInplace (#22) injecte votre image fixe prétraitée dans la timeline; si Switch to Text to Video? est activé, son entrée bypass désactive proprement l'injection d'image pour le T2V pur. LTXVScheduler (#47) façonne le calendrier sigma pour contrôler l'amplitude du mouvement et la fluidité temporelle. SamplerCustomAdvanced (#9), dirigé par CFGGuider (#42) et KSamplerSelect (#17), synthétise un latent A/V cohérent basse résolution. LTXVSeparateAVLatent (#35) sépare ensuite les chemins vidéo et audio et transmet les informations de cadrage à LTXVCropGuides (#10) pour la composition guidée par guide.
Upscale Latent#
LTXVLatentUpsampler (#13) avec le LTX-2.3 Spatial Upscaler ajoute du détail spatial dans l'espace latent tout en préservant le mouvement appris lors du premier passage. L'upscaling ici évite de réinventer le timing et réduit le scintillement souvent observé avec la régénération naïve du second passage. Il remet un latent plus net et cohérent avec le mouvement à l'étape de raffinement final.
Générer haute résolution#
L'étape de raffinement recombine le latent vidéo upscalé et le latent audio via LTXVConcatAVLatent (#3). CFGGuider (#8) et KSamplerSelect (#6) dirigent un échantillonneur rapide et orienté vers le détail dans SamplerCustomAdvanced (#36) en utilisant un calendrier sigma ajusté pour la finition. Si vous avez laissé l'injection d'image activée, une seconde LTXVImgToVideoInplace (#14) aide le modèle à honorer l'image fixe en haute résolution sans perdre le mouvement déjà établi. Le résultat est une séquence cinématographique stable avec des dynamiques naturelles des yeux et de la bouche.
Sortie#
VAEDecode (#68) transforme le latent vidéo final en images tandis que LTXVAudioVAEDecode (#23) reconstruit la piste audio silencieuse. CreateVideo (#38) multiplexe les images et l'audio à votre taux de trame sélectionné, et SaveVideo (#45) écrit un MP4 H.264 pour un examen immédiat et un partage. Utilisez un préfixe de nom de fichier descriptif par prise pour garder les itérations organisées.
Conversion des nombres#
Un petit bloc utilitaire calcule des tailles à demi-échelle pour la construction latente pour gérer la VRAM et la vitesse. Vous n'avez généralement pas besoin de toucher à ceux-ci, mais ils garantissent que la largeur et la hauteur en amont dirigent tout de manière cohérente. Si vous changez la résolution de base, ceux-ci s'adaptent automatiquement.
Nœuds clés dans Comfyui LTX 2.3 Sulphur image to video workflow#
PromptRelayEncode(#80). Centralise un prompt global et des prompts locaux rythme-par-rythme alignés sur la timeline. Utilisez-le pour scénariser des micro-expressions et de petites révélations de caméra à travers la prise. Gardez les prompts locaux courts et spécifiques pour qu'ils complètent plutôt qu'ils ne combattent l'apparence globale.LTXVImgToVideoInplace(#22, #14). Injecte l'image fixe dans les latents basse et haute résolution. Augmentez lastrengthlorsque vous souhaitez que le final adhère étroitement au cadre de référence; réduisez-la pour plus de liberté. L'entréebypassest câblée à l'interrupteur Texte-à-Vidéo pour que vous puissiez désactiver proprement l'injection d'image pour les exécutions T2V.LTXVScheduler(#47). Contrôle comment les niveaux de bruit évoluent pendant le passage basse résolution, ce qui affecte directement l'intensité et la fluidité du mouvement. Utilisez-le pour apprivoiser les prises trop actives ou pour ajouter une poussée subtile lorsque les choses semblent statiques. Les ajustements ici sont les plus notables sur les visages, les cheveux et l'énergie de caméra de type main tenue.LTXVLatentUpsampler(#13). Effectue un upscaling latent x2 avec le spatial upscaler de LTX, préservant les indices de mouvement appris lors du premier passage. Utilisez-le pour ajouter une texture nette et une définition des bords avant le raffinement haute résolution sans réinventer le timing.CFGGuider(#42, #8). Équilibre la force avec laquelle le modèle suit vos prompts par rapport à ses prieurs appris. Si les visages dérivent ou si le style s'affaiblit, augmentez le guidage; si les détails semblent forcés ou plastiques, diminuez-le. Associez les changements à un coup d'œil rapide au prompt négatif pour maintenir le réalisme.KSamplerSelect(#17, #6). Vous permet de choisir l'algorithme d'échantillonnage par étape. Favorisez un échantillonneur robuste et expressif pour le passage basse résolution et une option rapide et orientée vers le détail pour le passage de finition. Gardez le choix cohérent à travers les itérations lors de la comparaison des apparences.
Extras optionnels#
- Pour un comportement de caméra délibéré, vous pouvez ajouter un LoRA de contrôle de caméra comme Dolly-Left de la famille LTX à votre chaîne de chargeur LoRA lorsque vous souhaitez une poussée latérale cohérente. Model page
- Gardez la largeur et la hauteur divisibles par 32 pour éviter les désalignements dans les opérations latentes et pour maintenir l'efficacité de la VRAM.
- Utilisez des verbes courts et actifs dans les prompts locaux pour chorégraphier les rythmes, par exemple serrer la prise, détourner le regard, adoucir le sourire.
- Si vous ciblez des tailles de sortie très élevées, envisagez de remplacer
VAEDecodeparVAEDecodeTiled(#43) pour décoder les images de manière plus efficace en mémoire. - Lorsque les visages comptent le plus, itérez en ajustant uniquement le texte de prompt et
CFGGuideravant de changer d'échantillonneur ou de résolution. Cela garde les comparaisons significatives et fait ressortir le meilleur libellé pour le workflow LTX 2.3 Sulphur image to video.
Remerciements#
Ce workflow implémente et construit à partir des travaux et ressources suivants. Nous remercions chaleureusement RunningHub pour la référence de workflow, Lightricks pour la famille LTX 2.3 (modèle, spatial upscaler et LoRA de contrôle de caméra), et Comfy-Org pour l'encodeur de texte LTX pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux référentiels liés ci-dessous.
Ressources#
- RunningHub/RunningHub workflow reference
- Docs / Notes de version : runninghub.ai post
- Lightricks/LTX 2.3 model source
- Hugging Face : Lightricks/LTX-2.3-fp8
- Lightricks/LTX 2.3 spatial upscaler source
- Hugging Face : Lightricks/LTX-2.3
- Lightricks/LTX camera-control LoRA source
- Hugging Face : Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Comfy-Org/LTX text encoder source
- Hugging Face : Comfy-Org/ltx-2
Note : L'utilisation des modèles, ensembles de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.
