
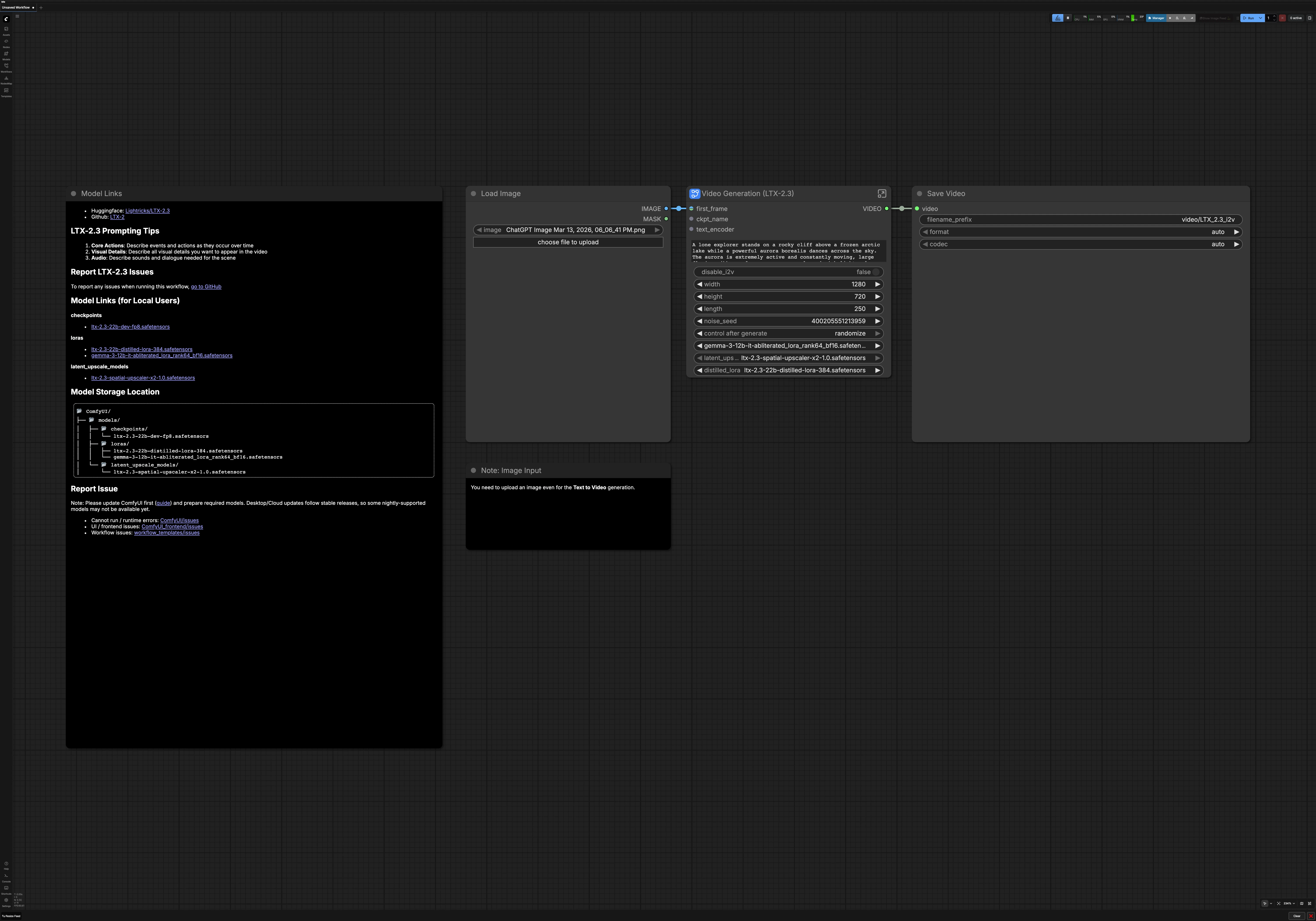
LTX 2.3 Image vers Vidéo pour ComfyUI#
Ce workflow transforme une image unique ou un prompt textuel pur en vidéo IA fluide et cinématique avec LTX 2.3 Image vers Vidéo. Il est conçu pour les créateurs qui veulent une haute cohérence visuelle, une forte consistance de scène et un mouvement soigné sans câblage manuel. Utilisez-le sur RunComfy ou tout environnement ComfyUI pour générer des résultats dynamiques et stylisés qui restent fidèles à votre prompt.
Le graphe supporte deux modes créatifs : image vers vidéo avec votre première frame comme ancre visuelle, ou texte vers vidéo guidé entièrement par le langage. Il inclut également l'amélioration automatique des prompts, l'upscaling latent pour des détails plus nets, et le décodage audio optionnel pour que votre rendu final LTX 2.3 Image vers Vidéo arrive prêt à publier.
Modèles clés du workflow ComfyUI LTX 2.3 Image vers Vidéo#
- Modèle vidéo Lightricks LTX 2.3 22B. Le transformer de diffusion vidéo principal qui synthétise un mouvement temporellement cohérent et des visuels à partir de texte et de guidage optionnel par image. Les fichiers du modèle et la documentation sont disponibles sur Hugging Face et les références au niveau du code sur GitHub.
- LTX Audio VAE. L'autoencodeur variationnel audio utilisé pour décoder le latent audio du modèle en piste audio pour le muxage avec les frames. Distribué avec la release LTX 2.3 sur Hugging Face.
- LTX 2.3 Spatial Upscaler x2. Un modèle de super-résolution dans l'espace latent qui améliore la netteté et la fidélité spatiale avant la passe finale de sampling haute résolution. Disponible dans le dépôt LTX 2.3 sur Hugging Face.
- Encodeur de texte Gemma 3 12B Instruct plus LoRA. Un encodeur de texte compact ajusté pour les instructions et un LoRA utilisés ici pour améliorer la compréhension des prompts et le phrasé pour la vidéo. L'encodeur empaqueté et les poids LoRA utilisés par ce template sont fournis dans les assets Comfy-Org LTX-2 sur Hugging Face.
Comment utiliser le workflow ComfyUI LTX 2.3 Image vers Vidéo#
À un niveau élevé, votre prompt et la première frame optionnelle sont encodés, une vidéo latente basse résolution est échantillonnée, puis upscalée dans l'espace latent et raffinée à plus haute résolution. Le résultat est décodé en frames et audio, puis composé en MP4 final. Vous pouvez basculer entre image vers vidéo et texte vers vidéo à tout moment avant l'exécution.
- Model
- Ce groupe charge le checkpoint LTX 2.3, l'audio VAE et l'encodeur de texte. Il applique également le LoRA LTX 2.3 au modèle de base pour un meilleur suivi des instructions. Ensemble, ils définissent la fondation sur laquelle le reste du pipeline LTX 2.3 Image vers Vidéo s'appuie. Vous n'aurez généralement rien à changer ici sauf si vous changez de variantes de modèle ou de styles LoRA.
- Prompt
- Entrez votre description de scène et les négatifs optionnels. Le texte est encodé pour le conditioning positif et négatif et associé à votre fréquence d'images sélectionnée pour que la planification du mouvement s'aligne avec le timing. Gardez un langage temporellement conscient avec des verbes qui décrivent le changement, par exemple « la caméra avance » ou « les feuilles tourbillonnent dans le vent ». Les prompts négatifs aident à éviter les artefacts indésirables comme les filigranes ou les simplifications cartoonesques.
- Prompt Enhancement
- Le graphe inclut un helper qui analyse votre image et texte, puis génère un brouillon de prompt plus fort et temporellement conscient que vous pouvez adopter ou modifier. Cela facilite l'orientation de LTX 2.3 Image vers Vidéo vers des descriptions cinématiques et axées sur l'action. C'est particulièrement utile quand vous partez d'une image fixe unique et voulez un mouvement qui semble intentionnel. Le nœud de prévisualisation vous permet d'inspecter le texte amélioré avant la génération.
- Video Settings
- Choisissez d'exécuter image vers vidéo ou de basculer vers texte vers vidéo avec un simple interrupteur. Définissez largeur, hauteur, durée et fréquence d'images pour correspondre à votre plateforme cible. Ces paramètres pilotent l'allocation latente et le décodage en aval, gardez-les en phase avec votre intention créative. Si vous prévoyez de publier largement, privilégiez des dimensions et un timing compatibles avec les codecs.
- Image Preprocess
- Votre première frame est redimensionnée et normalisée à un ratio compatible avec le modèle tout en préservant la composition. Un léger préfiltre aide à stabiliser les bords et réduire le bruit de compression qui peut causer des scintillements pendant le mouvement. Cette étape est importante même quand vous n'utilisez l'image que pour suggérer la mise en page et la couleur.
- Empty Latent
- Le workflow alloue des latents vidéo et audio vides basés sur vos dimensions, durée et fréquence d'images. Cela fournit un canevas propre pour le sampler et assure que l'audio et la vidéo restent alignés en longueur. Le bruit est généré de manière déterministe quand vous voulez la reproductibilité ou randomisé pour la variation entre les exécutions.
- Generate Low Resolution
- Une première passe de sampling sculpte le mouvement et la structure dans une vidéo latente compacte. Si vous utilisez image vers vidéo,
LTXVImgToVideoInplace(#249) injecte votre première frame comme ancre visuelle pour que le mouvement évolue depuis un point de départ cohérent. Le conditioning de votre texte positif et négatif guide le contenu et le style, tandis queManualSigmas(#252) etKSamplerSelectdéfinissent l'agressivité de la suppression du bruit dans le temps.LTXVCropGuides(#212) aide à maintenir un cadrage qui correspond à votre prompt. Le latent audio-vidéo résultant est ensuite séparé pour un traitement distinct.
- Une première passe de sampling sculpte le mouvement et la structure dans une vidéo latente compacte. Si vous utilisez image vers vidéo,
- Latent Upscale
- Avant de s'engager dans le raffinement haute résolution,
LTXVLatentUpsampler(#253) applique l'upscaler spatial x2 au latent basse résolution. Faire cela dans l'espace latent est rapide et préserve le mouvement appris tout en augmentant la capacité de détail. C'est un moyen sûr d'ajouter de la netteté sans introduire d'artefacts.
- Avant de s'engager dans le raffinement haute résolution,
- Generate High Resolution
- Un second sampler raffine le latent upscalé à une taille spatiale plus grande pour fixer les textures, l'éclairage et les petits mouvements. En mode texte vers vidéo, l'étape image-vers-vidéo précédente peut être contournée et
LTXVImgToVideoInplace(#230) passe simplement le latent.VAEDecodeTiled(#251) décode ensuite efficacement le latent vidéo en frames. En parallèle, le latent audio est décodé avec le LTX Audio VAE pour que les deux flux soient précis en termes de frames.
- Un second sampler raffine le latent upscalé à une taille spatiale plus grande pour fixer les textures, l'éclairage et les petits mouvements. En mode texte vers vidéo, l'étape image-vers-vidéo précédente peut être contournée et
- Export
CreateVideo(#242) muxe les frames et l'audio en une seule vidéo à la fréquence d'images choisie. Le nœudSaveVideode niveau supérieur écrit le fichier final dans votre sortie ComfyUI pour un téléchargement immédiat. Votre rendu LTX 2.3 Image vers Vidéo est maintenant prêt à prévisualiser ou publier.
Nœuds clés du workflow ComfyUI LTX 2.3 Image vers Vidéo#
LTXVImgToVideoInplace(#249 et #230)- Convertit une image fixe en latent vidéo ou passe le latent quand désactivé. Utilisez-le quand vous voulez que la première frame définisse la mise en page, la palette et le placement des personnages. Basculez l'interrupteur texte-vers-vidéo si vous préférez que le mouvement émerge uniquement du prompt. La documentation de la famille d'opérateurs est maintenue dans l'intégration ComfyUI sur GitHub.
LTXVConditioning(#239)- Combine le texte positif et négatif encodé avec votre fréquence d'images pour produire un conditioning qui oriente le contenu et le tempo du mouvement. Privilégiez des phrases courtes et claires qui décrivent le changement dans le temps et réservez les négatifs aux artefacts que vous voyez régulièrement et voulez supprimer. Ce nœud est l'endroit le plus efficace pour ajuster le style et le comportement de la scène sans toucher aux samplers.
ManualSigmas(#252) avecKSamplerSelect- Le planning de bruit et le sampler travaillent ensemble pour trouver le compromis entre grand mouvement et détail fin. Un bruit initial élevé encourage un mouvement plus large tandis que les étapes ultérieures consolident la texture. N'ajustez ceux-ci qu'après avoir de bons prompts et un guidage par image en place. Les contrôles de sampling sous-jacents suivent la sémantique standard de ComfyUI, voir les implémentations de référence dans le dépôt LTX sur GitHub.
LTXVLatentUpsampler(#253)- Applique l'upscaler spatial LTX 2.3 dans l'espace latent pour raffiner à plus haute résolution dans l'étape suivante. Utilisez-le quand vous avez besoin de netteté supplémentaire ou prévoyez de livrer des formats plus grands. Le modèle x2 est distribué avec LTX 2.3 sur Hugging Face.
VAEDecodeTiled(#251) etCreateVideo(#242)- Le décodage par tuiles empêche les pics de mémoire aux résolutions plus élevées et assure une qualité de frame consistante.
CreateVideoassemble ensuite les frames et la piste audio décodée en un MP4 final à vos fps sélectionnés. Gardez vos fps cohérents avec la valeur utilisée pendant le conditioning pour éviter les dérives de lecture.
- Le décodage par tuiles empêche les pics de mémoire aux résolutions plus élevées et assure une qualité de frame consistante.
Extras optionnels#
- Vous devez quand même télécharger une image de première frame même en mode texte vers vidéo. L'interrupteur l'ignorera pendant la génération mais l'interface nécessite une image placeholder.
- Pour le prompt LTX 2.3 Image vers Vidéo, commencez par l'action principale, puis les spécificités visuelles, puis l'atmosphère. Les mots temporels comme « lentement », « soudainement » et « continue » aident le modèle à planifier le mouvement.
- Utilisez les prompts négatifs pour éviter les superpositions et artefacts d'interface comme « filigrane », « sous-titres » ou « image fixe ».
- Si le style semble trop fort ou trop faible, essayez un LoRA différent ou ajustez son poids dans le LoRA loader. Vous pouvez aussi retirer le LoRA pour vous appuyer sur le rendu du modèle de base.
- Réutilisez un seed de bruit fixe pour la reproductibilité lors de l'itération sur le texte, puis randomisez pour la variation une fois le plan verrouillé.
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Lightricks pour LTX-2.3 et EyeForAILabs pour le tutoriel YouTube EyeForAILabs pour leurs contributions et leur maintenance. Pour les détails officiels, veuillez consulter la documentation et les dépôts originaux liés ci-dessous.
Ressources#
- Lightricks/LTX-2.3
- GitHub : Lightricks/LTX-2
- Hugging Face : Lightricks/LTX-2.3
- arXiv : LTX-2: Efficient Joint Audio-Visual Foundation Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes : EyeForAILabs YouTube Tutorial
Note : L'utilisation des modèles, datasets et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.