
Inférence LTX 2.3 LoRA ComfyUI : sortie LoRA AI Toolkit correspondant à la formation avec le pipeline LTX 2.3#
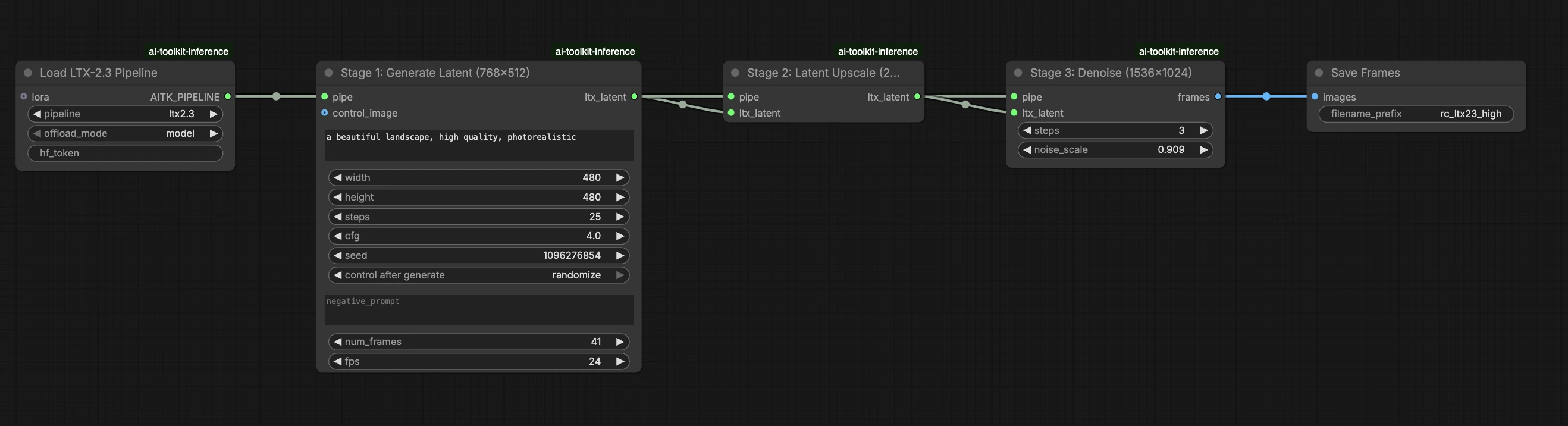
Ce workflow prêt pour la production RunComfy exécute l'inférence LTX 2.3 LoRA dans ComfyUI via RC LTX 2.3 (LTX2Pipeline) (alignement au niveau du pipeline, pas un graphe d'échantillonneur générique). RunComfy a construit et open-sourcé ce nœud personnalisé—voir les dépôts runcomfy-com—et vous contrôlez l'application de l'adaptateur avec lora_path et lora_scale.
Remarque : Ce workflow nécessite une machine 2X Large ou plus grande pour fonctionner.
Pourquoi l'inférence LTX 2.3 LoRA ComfyUI semble souvent différente dans ComfyUI#
Les aperçus de formation de l'AI Toolkit sont rendus à travers un pipeline spécifique au modèle LTX 2.3, où l'encodage de texte, la planification et l'injection LoRA sont conçus pour fonctionner ensemble. Dans ComfyUI, reconstruire LTX 2.3 avec un graphe différent (ou un chemin de chargeur LoRA différent) peut modifier ces interactions, donc copier le même prompt, étapes, CFG, et seed produit toujours une dérive visible. Les nœuds de pipeline RC RunComfy comblent cet écart en exécutant LTX 2.3 de bout en bout dans LTX2Pipeline et en appliquant votre LoRA dans ce pipeline, gardant l'inférence alignée avec le comportement d'aperçu. Source : Dépôts open-source RunComfy.
Comment utiliser le workflow d'inférence LTX 2.3 LoRA ComfyUI#
Étape 1 : Obtenez le chemin LoRA et chargez-le dans le workflow (2 options)#
Option A — Résultat de formation RunComfy → téléchargez sur ComfyUI localement :
- Allez sur Trainer → LoRA Assets
- Trouvez le LoRA que vous souhaitez utiliser
- Cliquez sur le menu ⋮ (trois points) à droite → sélectionnez Copier le lien LoRA
- Dans la page de workflow ComfyUI, collez le lien copié dans le champ d'entrée Télécharger en haut à droite de l'UI
- Avant de cliquer sur Télécharger, assurez-vous que le dossier cible est défini sur ComfyUI > models > loras (ce dossier doit être sélectionné comme cible de téléchargement)
- Cliquez sur Télécharger — cela garantit que le fichier LoRA est enregistré dans le répertoire
models/lorascorrect - Après la fin du téléchargement, rafraîchissez la page
- Le LoRA apparaît maintenant dans le menu déroulant de sélection LoRA dans le workflow — sélectionnez-le
Option B — URL directe LoRA (remplace l'Option A) :
- Collez l'URL directe de téléchargement
.safetensorsdans le champ d'entréepath / urldu nœud LoRA - Lorsqu'une URL est fournie ici, elle remplace l'Option A — le workflow charge le LoRA directement depuis l'URL à l'exécution
- Aucun téléchargement local ou placement de fichier n'est requis
Conseil : confirmez que l'URL résout vers le fichier .safetensors réel (pas une page d'atterrissage ou une redirection).
Étape 2 : Faites correspondre les paramètres d'inférence avec vos paramètres d'échantillons de formation#
Dans le nœud LoRA, sélectionnez votre adaptateur dans lora_path (Option A), ou collez un lien direct .safetensors dans path / url (Option B remplace le menu déroulant). Ensuite, définissez lora_scale à la même intensité que vous avez utilisée pendant les aperçus de formation et ajustez à partir de là.
Les paramètres restants sont sur le nœud Generate (et, selon le graphe, le nœud Load Pipeline) :
prompt: votre texte de prompt (incluez des mots déclencheurs si vous avez formé avec eux)width/height: résolution de sortie ; faites correspondre à la taille de votre aperçu de formation pour la comparaison la plus nette (les multiples de 32 sont recommandés pour LTX 2.3)num_frames: nombre de frames vidéo de sortiesample_steps: nombre d'étapes d'inférence (30 est une valeur par défaut courante)guidance_scale: valeur de CFG/guidance (5.5 est une valeur par défaut courante ; ne dépassez pas 7)seed: seed fixe pour reproduire ; changez-le pour explorer des variationsseed_mode(seulement si présent) : choisissezfixedourandomizeframe_rate: FPS de sortie ; gardez cohérent avec les paramètres de formation pour l'alignement du mouvement
Conseil d'alignement de formation : si vous avez personnalisé les valeurs d'échantillonnage pendant la formation (seed, guidance_scale, sample_steps, mots déclencheurs, résolution), reflétez ces valeurs exactes ici. Si vous avez formé sur RunComfy, ouvrez Trainer → LoRA Assets > Config pour voir le YAML résolu et copier les paramètres d'aperçu/échantillon dans les nœuds de workflow.
Étape 3 : Exécutez l'inférence LTX 2.3 LoRA ComfyUI#
Cliquez sur Queue/Run — le nœud SaveVideo écrit les résultats dans votre dossier de sortie ComfyUI.
Liste de vérification rapide :
- ✓ Le LoRA est soit : téléchargé dans
ComfyUI/models/loras(Option A), soit chargé via une URL directe.safetensors(Option B) - ✓ Page rafraîchie après le téléchargement local (Option A uniquement)
- ✓ Les paramètres d'inférence correspondent à la configuration de l'échantillon de formation (si personnalisée)
Si tout ce qui précède est correct, les résultats d'inférence ici devraient correspondre de près à vos aperçus de formation.
Dépannage de l'inférence LTX 2.3 LoRA ComfyUI#
La plupart des écarts "aperçu de formation vs inférence ComfyUI" de LTX 2.3 proviennent des différences au niveau du pipeline (comment le modèle est chargé, planifié, et comment le LoRA est fusionné), pas d'un simple mauvais réglage. Ce workflow RunComfy restaure la base "correspondant à la formation" la plus proche en exécutant l'inférence via RC LTX 2.3 (LTX2Pipeline) de bout en bout et en appliquant votre LoRA dans ce pipeline via lora_path / lora_scale (au lieu d'empiler des nœuds de chargeur/échantillonneur génériques).
(1) Incompatibilités de forme LoRA ou avertissements "clé non chargée"#
Pourquoi cela se produit Le LoRA a été formé pour une famille de modèles différente ou une variante LTX différente. Vous verrez de nombreuses lignes lora key not loaded et potentiellement des erreurs de non-concordance de forme.
Comment réparer (recommandé)
- Assurez-vous que le LoRA a été formé spécifiquement pour LTX 2.3 avec AI Toolkit (les LoRAs LTX 2.0 / 2.1 / 2.2 ne sont pas interchangeables).
- Gardez le graphe "à un seul chemin" pour LoRA : chargez l'adaptateur uniquement via l'entrée
lora_pathdu workflow et laissez LTX2Pipeline gérer la fusion. N'empilez pas un chargeur LoRA générique supplémentaire en parallèle. - Si vous avez déjà rencontré une non-concordance et que ComfyUI commence à produire des erreurs CUDA/OOM non liées par la suite, redémarrez le processus ComfyUI pour réinitialiser complètement l'état du GPU + modèle, puis réessayez avec un LoRA compatible.
(2) Les résultats d'inférence ne correspondent pas aux aperçus de formation#
Pourquoi cela se produit Même lorsque le LoRA se charge, les résultats peuvent encore dériver si votre graphe ComfyUI ne correspond pas au pipeline d'aperçu de formation (différents paramètres par défaut, chemin d'injection LoRA différent, planification différente).
Comment réparer (recommandé)
- Utilisez ce workflow et collez votre lien direct
.safetensorsdanslora_path. - Copiez les valeurs d'échantillonnage de votre configuration de formation AI Toolkit (ou RunComfy Trainer → LoRA Assets Config) :
width,height,num_frames,sample_steps,guidance_scale,seed,frame_rate. - Gardez "les piles de vitesse supplémentaires" hors de la comparaison à moins que vous n'ayez formé/échantillonné avec elles.
(3) Utiliser des LoRAs augmente considérablement le temps d'inférence#
Pourquoi cela se produit Un LoRA peut rendre LTX 2.3 beaucoup plus lent lorsque le chemin LoRA force un travail de patching/déquantification supplémentaire ou applique des poids dans un chemin de code plus lent que le modèle de base seul.
Comment réparer (recommandé)
- Utilisez le chemin RC LTX 2.3 (LTX2Pipeline) de ce workflow et passez votre adaptateur via
lora_path/lora_scale. Dans cette configuration, le LoRA est fusionné une fois pendant le chargement du pipeline (style AI Toolkit), donc le coût d'échantillonnage par étape reste proche du modèle de base. - Lorsque vous recherchez un comportement correspondant à l'aperçu, évitez d'empiler plusieurs chargeurs LoRA ou de mélanger les chemins de chargeur. Limitez-vous à un
lora_path+ unlora_scalejusqu'à ce que la base corresponde.
(4) Erreurs OOM sur de grandes résolutions ou de longues vidéos#
Pourquoi cela se produit LTX 2.3 est un modèle de 22 milliards de paramètres et la génération vidéo est intensive en VRAM. De hautes résolutions ou de nombreux frames peuvent dépasser la mémoire GPU, surtout avec la surcharge LoRA.
Comment réparer (recommandé)
- Utilisez une machine 2X Large (80 GB VRAM) ou plus grande. Ce workflow n'est pas compatible avec les machines Medium, Large, ou X Large.
- Réduisez la résolution ou le nombre de frames si vous avez besoin d'itérer rapidement, puis augmentez pour les rendus finaux.
- Activez le tiling VAE si disponible — cela peut économiser ~3 GB VRAM avec une perte de qualité minimale.
Exécutez maintenant l'inférence LTX 2.3 LoRA ComfyUI#
Ouvrez le workflow, définissez lora_path, et cliquez sur Queue/Run pour obtenir des résultats LTX 2.3 LoRA qui restent proches de vos aperçus de formation AI Toolkit.

