
La vidéo Hunyuan, un modèle d'IA open-source développé par Tencent, vous permet de générer des visuels époustouflants et dynamiques avec facilité. Le modèle Hunyuan utilise une architecture avancée et des techniques d'entraînement pour comprendre et générer un contenu de haute qualité, diversifié en mouvements et stable.
À propos du workflow Hunyuan Vidéo à Vidéo#
Ce workflow Hunyuan dans ComfyUI utilise le modèle Hunyuan pour créer un nouveau contenu visuel en combinant des invites texte avec une vidéo existante. En tirant parti des capacités du modèle Hunyuan, vous pouvez générer des traductions vidéo impressionnantes qui intègrent parfaitement le mouvement et les éléments clés de la vidéo de référence tout en alignant le résultat sur votre invite texte souhaitée.
Comment utiliser le workflow Hunyuan Vidéo à Vidéo#
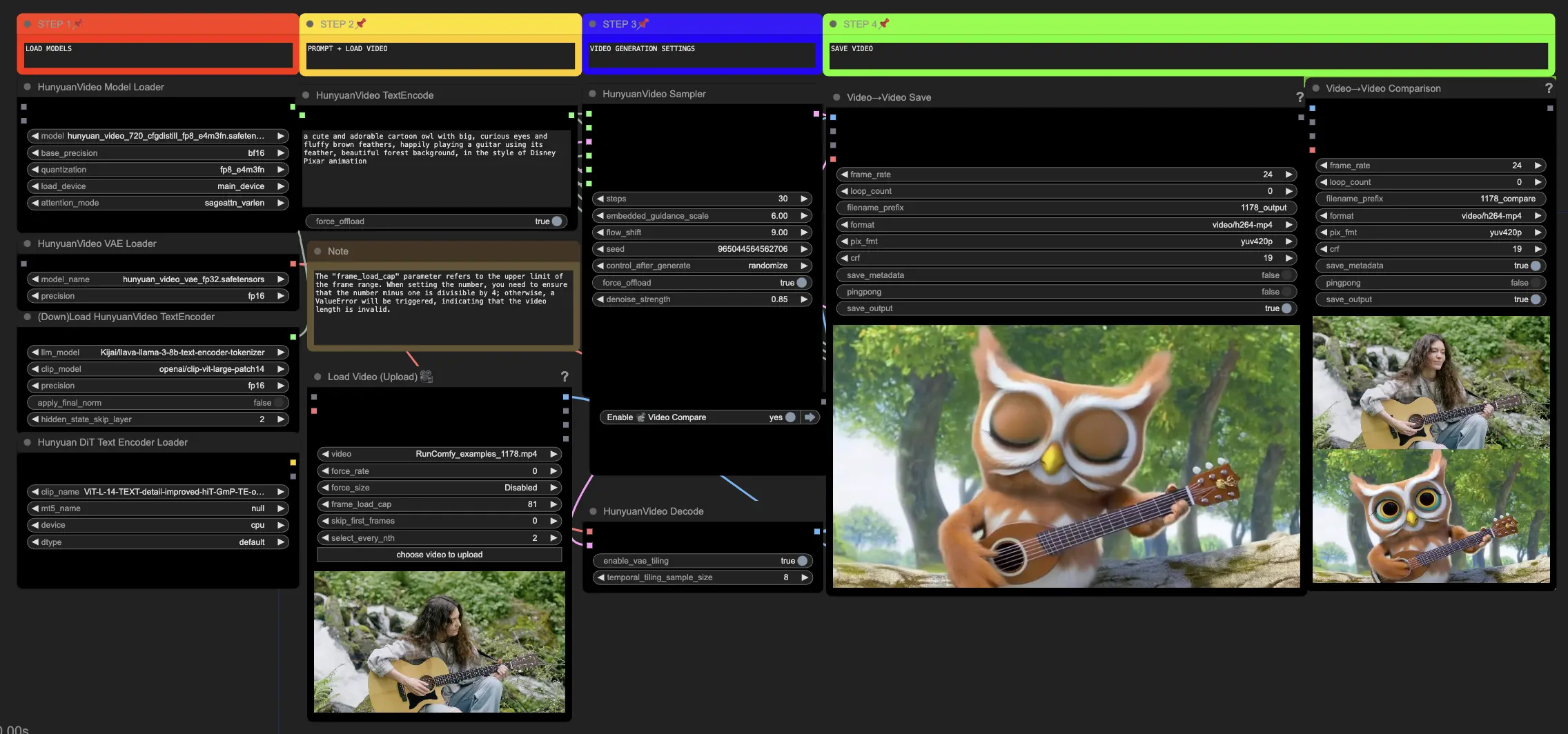
🟥 Étape 1 : Charger les modèles Hunyuan
- Chargez le modèle Hunyuan en sélectionnant le fichier "hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors" dans le nœud HyVideoModelLoader. C'est le modèle transformateur principal.
- Le modèle HunyuanVideo VAE sera automatiquement téléchargé dans le nœud HunyuanVideoVAELoader. Il est utilisé pour l'encodage/décodage des images vidéo.
- Chargez un encodeur de texte dans le nœud DownloadAndLoadHyVideoTextEncoder. Le workflow utilise par défaut l'encodeur LLM "Kijai/llava-llama-3-8b-text-encoder-tokenizer" et l'encodeur CLIP "openai/clip-vit-large-patch14", qui seront téléchargés automatiquement. Vous pouvez également utiliser d'autres encodeurs CLIP ou T5 qui ont fonctionné avec des modèles précédents.
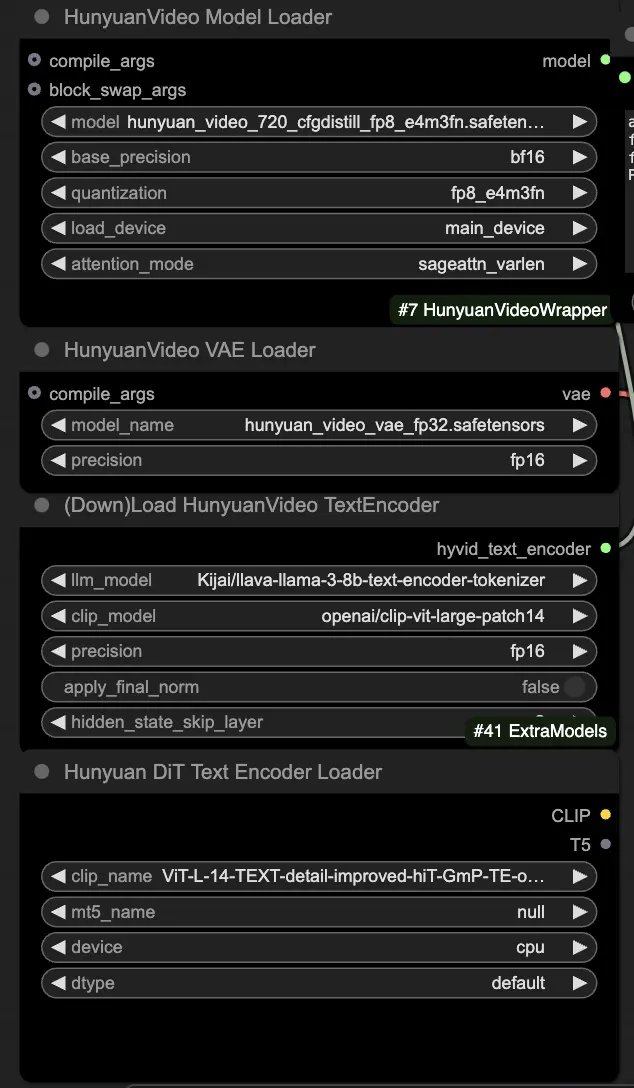
🟨 Étape 2 : Entrer l'invite & Charger la vidéo de référence
- Entrez votre invite texte décrivant le visuel que vous souhaitez générer dans le nœud HyVideoTextEncode.
- Chargez la vidéo de référence que vous souhaitez utiliser comme référence de mouvement dans le nœud VHS_LoadVideo.
- frame_load_cap : Nombre d'images à générer. Lors de la définition du nombre, vous devez vous assurer que le nombre moins un est divisible par 4 ; sinon, une ValueError sera déclenchée, indiquant que la longueur de la vidéo est invalide.
- skip_first_frames : Ajustez ce paramètre pour contrôler quelle partie de la vidéo est utilisée.
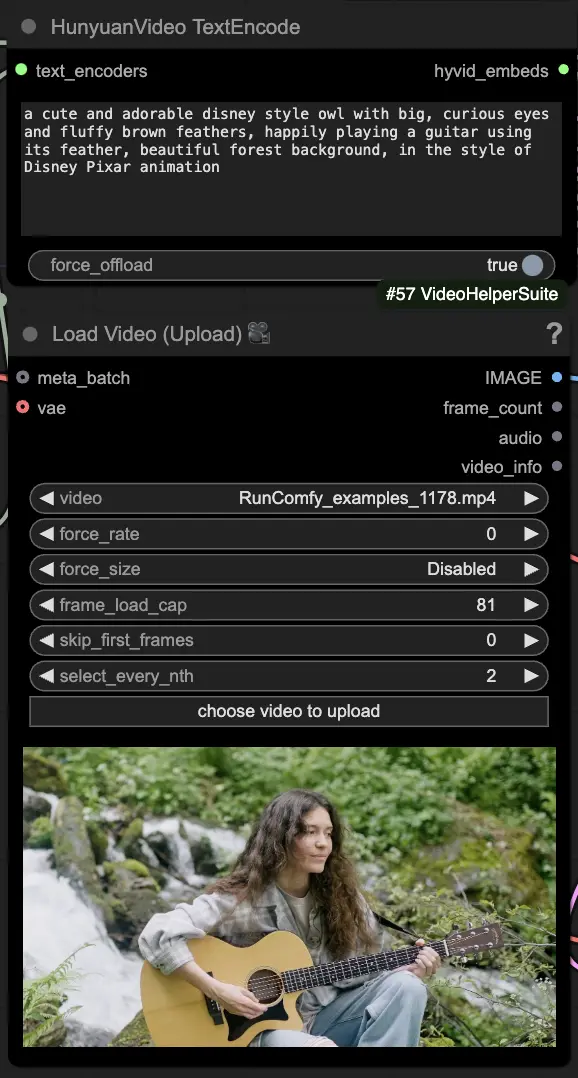
🟦 Étape 3 : Paramètres de génération Hunyuan
- Dans le nœud HyVideoSampler, configurez les hyperparamètres de génération vidéo :
- Steps : Nombre d'étapes de diffusion par image, plus élevé signifie une meilleure qualité mais une génération plus lente. Par défaut 30.
- Embedded_guidance_scale : À quel point s'en tenir à l'invite, des valeurs plus élevées adhèrent davantage à l'invite.
- Denoise_strength : Contrôle la force de l'utilisation de la vidéo de référence initiale. Des valeurs plus basses (par exemple 0,6) rendent le résultat plus semblable à l'initial.
- Choisissez des addons et des bascules dans le nœud "Fast Groups Bypasser" pour activer/désactiver des fonctionnalités supplémentaires comme la vidéo de comparaison.
🟩 Étape 4 : Générer la vidéo Huanyuan
- Les nœuds VideoCombine génèreront et enregistreront deux sorties par défaut :
- Le résultat vidéo traduit
- Une vidéo de comparaison montrant la vidéo de référence et le résultat généré
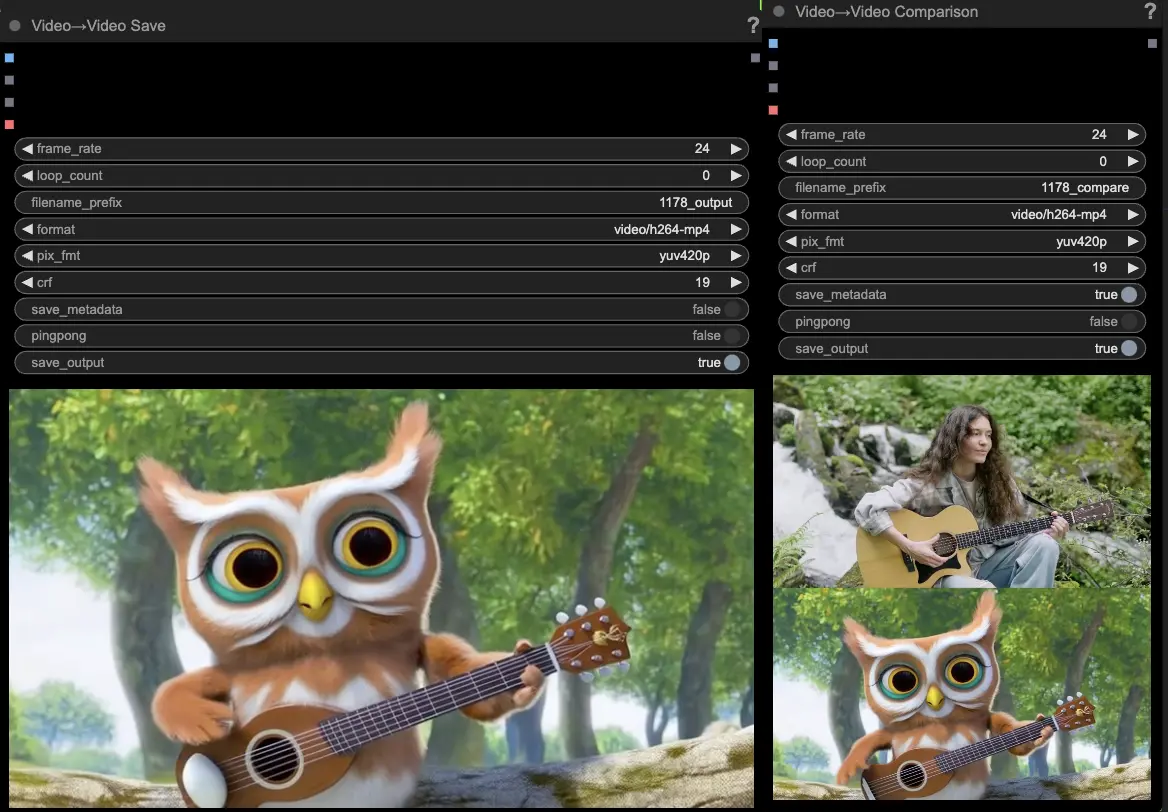
Modifier l'invite et les paramètres de génération permet une flexibilité impressionnante dans la création de nouvelles vidéos entraînées par le mouvement d'une vidéo existante en utilisant le modèle Hunyuan. Amusez-vous à explorer les possibilités créatives de ce workflow Hunyuan !
Ce workflow Hunyuan a été conçu par Black Mixture. Veuillez visiter la chaîne Youtube de Black Mixture pour plus d'informations. Remerciements spéciaux à Kijai pour les wrappers Hunyuan et les exemples de workflow.