
Fish Audio S2 TTS pour ComfyUI : TTS de haute qualité, clonage de voix, et dialogue multi-interlocuteurs#
Fish Audio S2 TTS est un flux de travail ComfyUI prêt à l'emploi qui transforme le texte en parole naturelle, clone une voix à partir d'un court extrait de référence, et génère des conversations multi-interlocuteurs. Il est propulsé par la famille Fish Audio S2-Pro et prend en charge un contrôle de style riche via des balises d'émotion et de prosodie telles que [excited], [whisper], et [laughing].
Ce flux de travail est idéal pour les créateurs, les équipes produit et les développeurs qui souhaitent une synthèse vocale flexible et expressive dans ComfyUI. Il inclut une option de reconnaissance vocale pour une capture rapide de transcription, une détection automatique de la langue, et plusieurs choix de précision incluant fp8 et sage_attention pour une inférence efficace.
Remarque : Exécutez ce flux de travail sur une machine 2X Large ou plus grande. Les instances plus petites peuvent manquer de mémoire (OOM).
Modèles clés dans le flux de travail Comfyui Fish Audio S2 TTS#
- Fish Audio S2-Pro — le modèle de synthèse vocale génératif central utilisé pour le TTS à un seul interlocuteur, le clonage de voix, et le dialogue multi-interlocuteurs. Il prend en charge de nombreuses balises de style et la synthèse multilingue model card et fait partie du projet Fish-Speech repo.
- Fish Audio S2-Pro FP8 — une variante économe en mémoire du S2-Pro qui réduit les besoins en VRAM avec un compromis minimal sur la qualité, recommandé pour les GPU contraints model card.
- OpenAI Whisper large-v3 — un modèle de reconnaissance vocale optionnel utilisé pour transcrire automatiquement votre audio de référence lors de la préparation de prompts de clonage de voix repo.
Comment utiliser le flux de travail Comfyui Fish Audio S2 TTS#
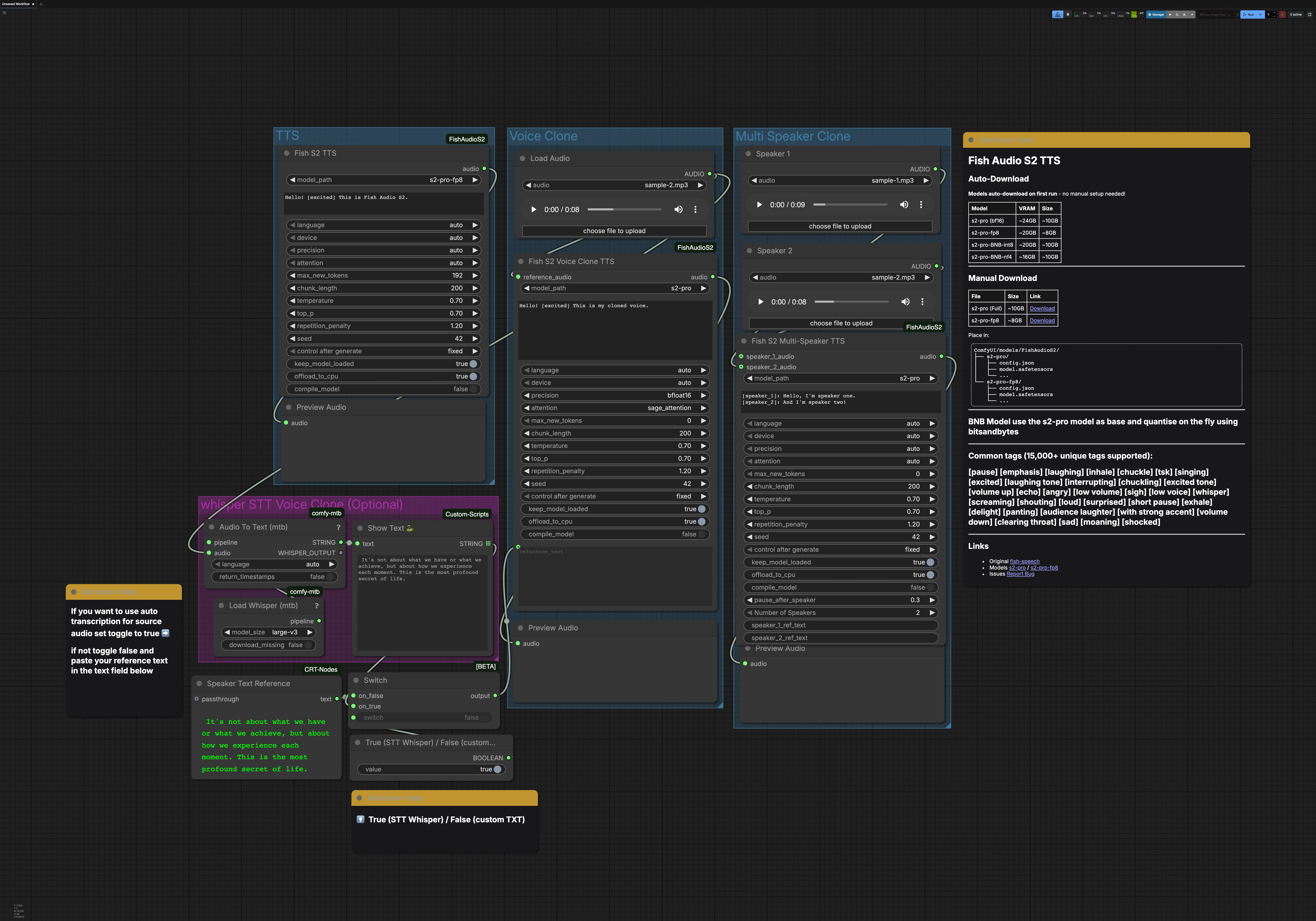
Ce flux de travail contient trois chemins principaux qui peuvent être exécutés indépendamment : TTS, Clone de Voix, et Clone Multi Interlocuteurs. Un groupe optionnel Whisper STT peut générer la transcription pour le clonage de voix. Chaque chemin se termine par un aperçu audio afin que vous puissiez surveiller les résultats rapidement.
Groupe TTS#
Le nœud FishS2TTS (#42) effectue une synthèse vocale directe avec Fish Audio S2 TTS. Entrez votre script dans la boîte de texte du nœud et ajoutez des balises de style comme [excited], [pause], ou [whisper] pour façonner l'émotion et le rythme. La détection de la langue est automatique, vous pouvez donc écrire dans la langue cible et le modèle s'adapte. Choisissez la variante S2-Pro qui correspond à la mémoire de votre GPU, par exemple fp8 pour des charges plus légères. La sortie est dirigée vers PreviewAudio pour une écoute instantanée.
Groupe Clone de Voix#
Utilisez LoadAudio pour fournir un extrait de référence court et propre de la voix cible, puis dirigez-le vers FishS2VoiceCloneTTS (#14). Fournissez la transcription qui correspond au style de parole souhaité ; un texte précis aide le modèle à préserver le rythme et l'accent. Vous pouvez générer le texte de référence à partir du groupe STT ou taper le vôtre, et vous pouvez ajouter des balises de style pour affiner l'émotion et la livraison. Les choix de précision et de backend d'attention équilibrent la vitesse, la mémoire, et la stabilité pour les longues lignes. Le clone synthétisé est envoyé à PreviewAudio pour vous permettre d'itérer rapidement.
Groupe Clone Multi Interlocuteurs#
Chargez un extrait de référence par interlocuteur à l'aide des nœuds LoadAudio, puis connectez-les à FishS2MultiSpeakerTTS (#41). Fournissez un script de dialogue qui étiquette chaque tour avec [speaker_1], [speaker_2], et ainsi de suite. Ce modèle inclut deux interlocuteurs par défaut, et le nœud prend en charge l'extension jusqu'à huit voix distinctes lorsqu'il est configuré en conséquence. Vous pouvez mélanger prose narrative, balises, et dialogue pour contrôler le flux et l'émotion de chaque personnage. Le mix final est prévisualisé pour vérifier le timing et la clarté.
Whisper STT pour le clonage de voix (optionnel)#
Load Whisper (mtb) (#6) avec large-v3 alimente Audio To Text (mtb) (#7) pour transcrire automatiquement un extrait de référence. Le texte reconnu est affiché par ShowText|pysssss (#8). Un petit commutateur construit avec ComfySwitchNode (#34) et un contrôle booléen vous permet de choisir entre la sortie STT (true) ou votre propre texte tapé à partir de Text Box line spot (#31) (false). Ceci est utile lorsque vous souhaitez une transcription de base rapide ou lors de la création d'un prompt précis pour le clonage.
Nœuds clés dans le flux de travail Comfyui Fish Audio S2 TTS#
FishS2TTS (#42)#
Génère un discours à un seul interlocuteur à partir de texte avec des balises de style optionnelles et une détection automatique de la langue. Ajustez la variante du modèle pour correspondre à votre matériel, par exemple en choisissant fp8 lorsque la VRAM est serrée. Utilisez le contrôle de la graine pour des prises répétables et introduisez de petits changements lors de l'exploration de livraisons alternatives. Pour les longs scripts, sélectionnez un backend d'attention optimisé pour la stabilité.
FishS2VoiceCloneTTS (#14)#
Crée une voix clonée en se basant sur reference_audio et reference_text. De meilleurs résultats proviennent d'un discours propre avec un ton cohérent et une transcription qui reflète le rythme souhaité. Des balises de style peuvent être mélangées dans le texte final pour orienter l'humeur sans nuire à l'identité. Les paramètres de précision et d'attention aident à équilibrer la qualité et la mémoire pour les lignes prolongées.
FishS2MultiSpeakerTTS (#41)#
Synthétise des conversations multi-interlocuteurs en associant l'audio de référence de chaque interlocuteur à un dialogue marqué par des étiquettes [speaker_n]. Augmentez le nombre d'interlocuteurs selon les besoins et assignez des extraits distincts pour une séparation plus forte. Gardez le ton de référence de chaque interlocuteur cohérent pour éviter le mélange. Utilisez la graine pour un mixage déterministe lors du rendu de scènes multi-prises.
Extras optionnels#
- Utilisez les balises de style judicieusement. Commencez avec quelques-unes comme [excited], [whisper], [emphasis], [pause], et développez uniquement si nécessaire pour la clarté.
- Pour le clonage de voix, coupez le silence au début et à la fin de la référence et évitez le bruit de fond pour préserver le timbre.
- Si la mémoire du GPU est limitée, préférez S2-Pro fp8 ou les options quantifiées à l'exécution. Pour une fidélité maximale, utilisez une précision plus élevée.
- La ponctuation compte. Les virgules et les points améliorent la phraséologie, et les balises placées aux limites des clauses tendent à sonner plus naturel.
- Pour les scripts multi-interlocuteurs, gardez une déclaration par ligne et préfixez toujours avec la bonne étiquette [speaker_n] pour maintenir la séparation.
Ressources :
- Fish Audio S2-Pro model card: Hugging Face
- S2-Pro fp8 variant: Hugging Face
- Fish-Speech project: GitHub
- ComfyUI Fish Audio S2 nodes: GitHub
- Whisper large-v3: GitHub
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Saganaki22 pour ComfyUI-FishAudioS2 Custom Nodes, et Fish Audio pour le modèle S2-Pro pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Ressources#
- Saganaki22/ComfyUI-FishAudioS2 Custom Nodes
- GitHub: Saganaki22/ComfyUI-FishAudioS2
- Fish Audio/S2-Pro Model
- Hugging Face: fishaudio/s2-pro
Note : L'utilisation des modèles, des ensembles de données et du code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.
