
InfiniteTalk : vidéo portrait synchronisée sur les lèvres à partir d'une seule image dans ComfyUI#
Ce workflow InfiniteTalk de ComfyUI crée des vidéos portrait naturelles et synchronisées sur le discours à partir d'une seule image de référence et d'un clip audio. Il combine la génération d'image à vidéo WanVideo 2.1 avec le modèle de tête parlante MultiTalk pour produire un mouvement labial expressif et une identité stable. Si vous avez besoin de courts clips sociaux, de doublages vidéo ou de mises à jour d'avatar, InfiniteTalk transforme une photo statique en une vidéo parlante fluide en quelques minutes.
InfiniteTalk s'appuie sur l'excellente recherche MultiTalk de MeiGen-AI. Pour les informations de base et les attributions, voir le projet open source : MeiGen-AI/MultiTalk.
Modèles clés dans le workflow Comfyui InfiniteTalk#
- MultiTalk (GGUF, variante InfiniteTalk) : Pilote le mouvement facial conscient des phonèmes à partir de l'audio pour que les mouvements de la bouche et de la mâchoire suivent naturellement le discours. Référence : Kijai/WanVideo_comfy_GGUF › InfiniteTalk et idée en amont : MeiGen-AI/MultiTalk.
- WanVideo 2.1 I2V 14B (GGUF) : Le générateur d'image à vidéo principal qui préserve l'identité, l'éclairage et la pose tout en animant les images. Poids recommandés : city96/Wan2.1-I2V-14B-480P-gguf.
- Wan 2.1 VAE (bf16) : Décode les images latentes en RGB avec un changement de couleur minimal ; fourni dans les packs WanVideo ci-dessus.
- UMT5-XXL encodeur de texte : Interprète vos invites positives et négatives pour influencer le style, la scène et le contexte du mouvement. Famille de modèles : google/umt5-xxl.
- CLIP Vision : Extrait les embeddings visuels de votre image de référence pour verrouiller l'identité et l'apparence générale.
- Wav2Vec2 (Tencent GameMate) : Convertit le discours brut en caractéristiques audio robustes pour les embeddings MultiTalk, améliorant la synchronisation et la prosodie : TencentGameMate/chinese-wav2vec2-base.
Conseil : ce graphe InfiniteTalk est conçu pour GGUF. Gardez les poids MultiTalk InfiniteTalk et l'ossature WanVideo en GGUF pour éviter les incompatibilités. Des constructions fp8/fp16 optionnelles sont également disponibles : Kijai/WanVideo_comfy_fp8_scaled et Kijai/WanVideo_comfy.
Comment utiliser le workflow Comfyui InfiniteTalk#
Le workflow s'exécute de gauche à droite. Vous fournissez trois éléments : une image portrait nette, un fichier audio de discours et une courte invite pour orienter le style. Le graphe extrait alors les indices de texte, d'image et d'audio, les fusionne en latents vidéo conscients du mouvement, et rend un MP4 synchronisé.
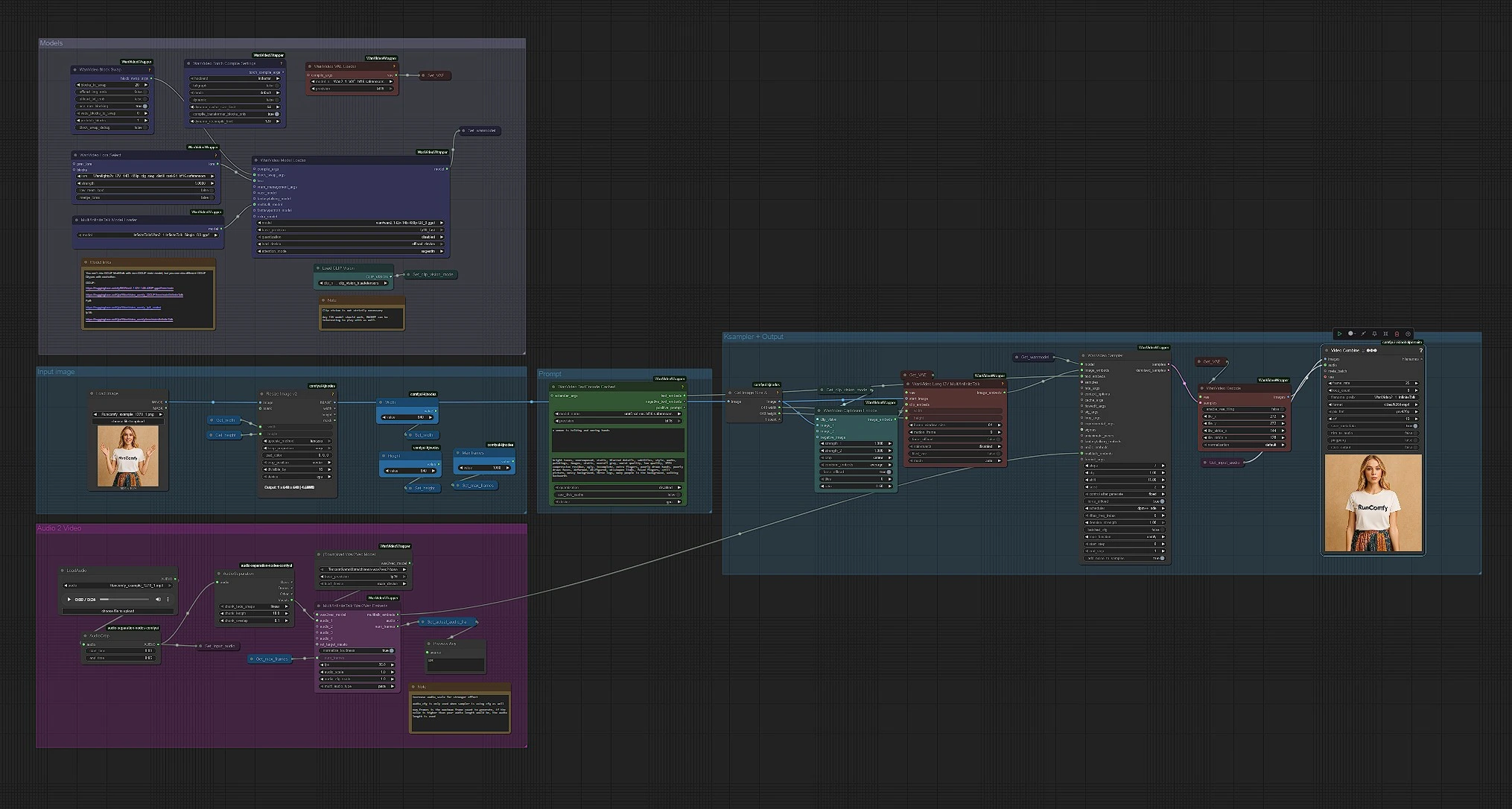
Modèles#
Ce groupe charge WanVideo, VAE, MultiTalk, CLIP Vision et l'encodeur de texte. WanVideoModelLoader (#122) sélectionne l'ossature Wan 2.1 I2V 14B GGUF, tandis que WanVideoVAELoader (#129) prépare le VAE correspondant. MultiTalkModelLoader (#120) charge la variante InfiniteTalk qui alimente le mouvement piloté par le discours. Vous pouvez éventuellement attacher un Wan LoRA dans WanVideoLoraSelect (#13) pour influencer l'apparence et le mouvement. Laissez ces éléments intacts pour un premier essai rapide ; ils sont pré-câblés pour un pipeline 480p qui convient à la plupart des GPU.
Invite#
WanVideoTextEncodeCached (#241) prend vos invites positives et négatives et les encode avec UMT5. Utilisez l'invite positive pour décrire le sujet et le ton de la scène, pas l'identité ; l'identité vient de la photo de référence. Gardez l'invite négative concentrée sur les artefacts que vous souhaitez éviter (flous, membres supplémentaires, arrière-plans gris). Les invites dans InfiniteTalk façonnent principalement l'éclairage et l'énergie du mouvement tandis que le visage reste cohérent.
Image d'entrée#
CLIPVisionLoader (#238) et WanVideoClipVisionEncode (#237) intègrent votre portrait. Utilisez une photo nette, de face, tête et épaules, avec une lumière uniforme. Si nécessaire, coupez légèrement pour que le visage ait de la place pour bouger ; une coupe excessive peut déstabiliser le mouvement. Les embeddings d'image sont transmis pour préserver l'identité et les détails vestimentaires à mesure que la vidéo s'anime.
Audio vers MultiTalk#
Chargez votre discours dans LoadAudio (#125) ; coupez-le avec AudioCrop (#159) pour des aperçus rapides. DownloadAndLoadWav2VecModel (#137) récupère Wav2Vec2, et MultiTalkWav2VecEmbeds (#194) transforme le clip en caractéristiques de mouvement conscientes des phonèmes. Des coupes courtes de 4 à 8 secondes sont idéales pour l'itération ; vous pouvez exécuter des prises plus longues une fois que vous aimez le rendu. Les pistes vocales claires et sèches fonctionnent le mieux ; une musique de fond forte peut perturber le timing labial.
Image à vidéo, échantillonnage et sortie#
WanVideoImageToVideoMultiTalk (#192) fusionne votre image, les embeddings CLIP Vision et MultiTalk en embeddings d'image par trame dimensionnés par les constantes Width et Height. WanVideoSampler (#128) génère les images latentes en utilisant le modèle WanVideo de Get_wanmodel et vos embeddings de texte. WanVideoDecode (#130) convertit les latents en images RGB. Enfin, VHS_VideoCombine (#131) multiplexe les images et l'audio en un MP4 à 25 fps avec un réglage de qualité équilibré, produisant le clip final InfiniteTalk.
Nœuds clés dans le workflow Comfyui InfiniteTalk#
WanVideoImageToVideoMultiTalk (#192)#
Ce nœud est le cœur d'InfiniteTalk : il conditionne l'animation de la tête parlante en fusionnant l'image de départ, les caractéristiques CLIP Vision et les instructions MultiTalk à votre résolution cible. Ajustez width et height pour définir l'aspect ; 832×480 est un bon défaut pour la vitesse et la stabilité. Utilisez-le comme principal endroit pour aligner l'identité avec le mouvement avant l'échantillonnage.
MultiTalkWav2VecEmbeds (#194)#
Convertit les caractéristiques Wav2Vec2 en embeddings de mouvement MultiTalk. Si le mouvement labial est trop subtil, augmentez son influence (mise à l'échelle audio) à ce stade ; s'il est trop exagéré, réduisez l'influence. Assurez-vous que l'audio est axé sur le discours pour un timing des phonèmes fiable.
WanVideoSampler (#128)#
Génère les latents vidéo étant donné les embeddings d'image, de texte et de MultiTalk. Pour les premiers essais, gardez le planificateur et les étapes par défaut. Si vous voyez des scintillements, augmenter le nombre total d'étapes ou activer le CFG peut aider ; si le mouvement semble trop rigide, réduisez la force du CFG ou de l'échantillonneur.
WanVideoTextEncodeCached (#241)#
Encode les invites positives et négatives avec UMT5-XXL. Utilisez un langage concis et concret comme "lumière de studio, peau douce, couleur naturelle" et concentrez les invites négatives sur les artefacts. Rappelez-vous que les invites affinent le cadrage et le style, tandis que la synchronisation labiale vient de MultiTalk.
Extras optionnels#
- Gardez MultiTalk et WanVideo dans la même famille de déploiement (tous GGUF ou tous non-GGUF) pour éviter les incompatibilités.
- Itérez avec un recadrage audio de 5 à 8 secondes et la taille par défaut de 480p ; upscalez plus tard si nécessaire.
- Si l'identité vacille, essayez une source photo plus nette ou un LoRA plus doux. Des LoRAs puissants peuvent annuler la ressemblance.
- Enregistrez le discours dans une pièce calme et normalisez les niveaux ; InfiniteTalk suit les phonèmes au mieux avec une voix claire et sèche.
Remerciements#
Le workflow InfiniteTalk représente un saut majeur dans la génération vidéo alimentée par l'IA en combinant le système de nœuds flexible de ComfyUI avec le modèle AI MultiTalk. Cette implémentation a été rendue possible grâce à la recherche originale et à la publication par MeiGen-AI, dont le projet MultiTalk alimente la synchronisation naturelle du discours d'InfiniteTalk. Un merci spécial également à l'équipe de projet InfiniteTalk pour avoir fourni la référence source, et à la communauté de développeurs ComfyUI pour avoir permis une intégration fluide des workflows.
De plus, un crédit est accordé à Kijai, qui a implémenté InfiniteTalk dans le nœud Wan Video Sampler, facilitant ainsi la production par les créateurs de portraits parlants et chantants de haute qualité directement dans ComfyUI. Le lien vers la ressource originale pour InfiniteTalk est disponible ici : InfiniteTalk Example Workflow.
Ensemble, ces contributions permettent aux créateurs de transformer de simples portraits en avatars parlants continus et réalistes, ouvrant de nouvelles opportunités pour la narration, le doublage et le contenu de performance pilotés par l'IA.
