
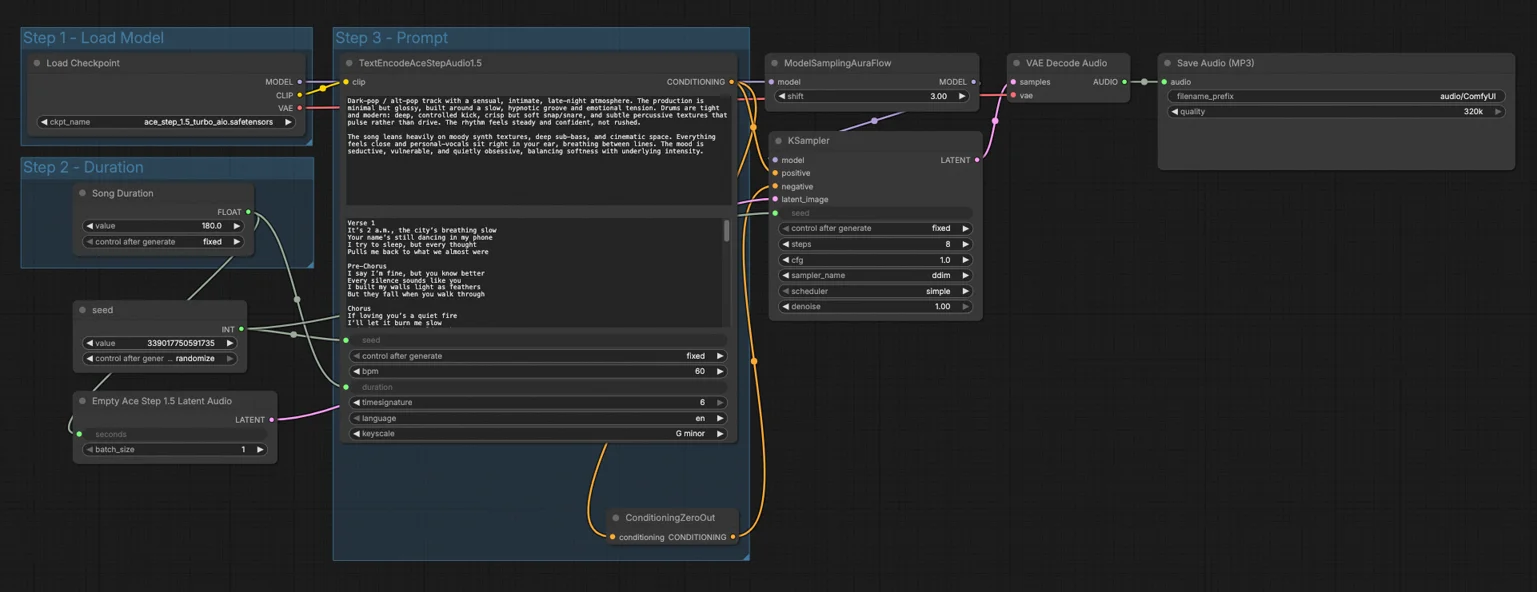
Workflow texte-à-musique Ace Step 1.5 pour ComfyUI#
Ce modèle transforme un court briefing créatif et des paroles optionnelles en un MP3 fini en utilisant Ace Step 1.5. Il est conçu pour les musiciens, producteurs et créateurs qui souhaitent une génération de chansons rapide et de haute qualité avec une structure cohérente, des voix et un contrôle stylistique à partir du texte. Le workflow se concentre sur un chemin direct texte-à-musique pour passer de l'idée à l'audio en une seule étape.
Ace Step 1.5 associe un module de planification à un transformateur de diffusion pour offrir une continuité musicale de qualité commerciale tout en restant suffisamment léger pour le matériel quotidien. Dans ce graph ComfyUI, Ace Step 1.5 accepte une invite de style plus des paroles, planifie l'arrangement, synthétise une représentation audio latente, puis décode et enregistre un fichier prêt à être partagé.
Modèles clés dans le workflow Comfyui Ace Step 1.5#
- Ace Step 1.5 Turbo AIO checkpoint. Le modèle de base qui associe le texte et les paroles à la musique et gère la synthèse basée sur la diffusion dans le domaine audio. Disponible chez Comfy-Org sur Hugging Face dans le cadre de l'ensemble de fichiers ComfyUI : Comfy-Org/ace_step_1.5_ComfyUI_files.
- Ace Step 1.5 text encoder. Inclus avec le checkpoint et utilisé pour convertir votre invite de prose et les paroles optionnelles en conditionnement pour le générateur. Exposé dans le graph par le nœud
TextEncodeAceStepAudio1.5. - Ace Step 1.5 audio VAE. Également inclus dans le checkpoint et utilisé pour décoder le latent synthétisé en une forme d'onde dans le domaine temporel pour l'exportation.
Comment utiliser le workflow Comfyui Ace Step 1.5#
À un niveau élevé, vous chargez le modèle Ace Step 1.5, choisissez la durée de la chanson, décrivez la musique et collez les paroles, puis lancez l'échantillonnage pour synthétiser et décoder en MP3.
Étape 1 - Charger le Modèle#
Ce groupe initialise les actifs principaux via CheckpointLoaderSimple (#97). Sélectionner le fichier Ace Step 1.5 Turbo AIO charge le modèle, son encodeur de texte et le VAE audio en une seule étape. Le nœud ModelSamplingAuraFlow (#78) attache une configuration de sampler compatible Ace Step 1.5 afin que le KSampler en aval puisse fonctionner avec l'algorithme prévu. Une fois cela défini, le reste du workflow peut être piloté uniquement par votre invite et la durée.
Étape 2 - Durée#
Ici, le contrôle Song Duration (#99) alimente les secondes dans EmptyAceStep1.5LatentAudio (#98), qui préalloue la longueur latente cible pour le morceau. Définir une longueur plus courte est idéal pour une idéation rapide et des vérifications de style, tandis que des valeurs plus longues permettent à Ace Step 1.5 de planifier des sections plus complètes. La durée s'écoule vers l'avant pour que l'encodeur et le sampler s'accordent sur la quantité de structure à générer. Si vous prolongez plus tard la chanson, gardez la même graine pour préserver l'ambiance et les motifs.
Étape 3 - Invite#
Utilisez TextEncodeAceStepAudio1.5 (#94) pour décrire le style, l'humeur, l'instrumentation et les notes de production, et collez éventuellement les paroles. Ace Step 1.5 lit cela pour planifier la mélodie, l'harmonie, le rythme et la phraséologie vocale avec des sections cohérentes. La ligne seed (#102) rend les résultats répétables ou aléatoires comme vous le souhaitez. Un ConditioningZeroOut (#47) envoie un conditionnement négatif neutre pour réduire les conflits, ce qui est souvent un bon choix par défaut pour les sorties musicales. Si vous souhaitez une invite négative plus stricte, remplacez ce nœud par votre propre chemin de texte négatif.
KSampler (#3)#
Ce nœud effectue le processus de diffusion réel en utilisant la connexion du modèle Ace Step 1.5 de ModelSamplingAuraFlow (#78), le conditionnement positif de votre invite, le conditionnement négatif neutre, et la longueur latente préallouée. Il transforme le bruit en un latent structuré qui reflète vos instructions textuelles et paroles. Pour une idéation rapide, vous pouvez garder le temps d'exécution conservateur, puis augmenter la qualité lorsque vous verrouillez un concept. La même graine produit une structure cohérente à travers les prises pour que vous puissiez comparer les choix de sampler.
VAEDecodeAudio (#18)#
Après l'échantillonnage, ce nœud convertit la représentation audio latente en une forme d'onde dans le domaine temporel en utilisant le VAE Ace Step 1.5. Il préserve la forme musicale planifiée pendant le codage tout en lissant les détails fins introduits pendant la diffusion. La sortie est un signal audio pleine bande prêt pour l'exportation.
SaveAudioMP3 (#104)#
Enfin, la forme d'onde est écrite dans un fichier MP3 dans vos sorties ComfyUI standards. Choisissez un débit binaire approprié pour votre cible et rendez. Cela vous donne un fichier partageable compact tout en gardant le latent original disponible pour des ré-exécutions si vous ajustez les invites ou les graines.
Nœuds clés dans le workflow Comfyui Ace Step 1.5#
TextEncodeAceStepAudio1.5 (#94)#
Transforme votre briefing créatif et vos paroles en un conditionnement que Ace Step 1.5 comprend. Pour le contrôle, ajustez la langue, la tonalité musicale et le tempo pour orienter la phraséologie et l'harmonie, et définissez la structure de la section lorsque vous souhaitez plus ou moins de changements de forme. Utilisez des notes de production descriptives comme le genre, l'humeur et les indices de mixage pour ancrer le style. Gardez les paroles concises et métriques pour un phrasé vocal plus clair.
KSampler (#3)#
Conduit le processus de diffusion qui transforme la planification en latents audio. Augmentez les étapes pour plus de détails et de stabilité, ou réduisez-les pour des aperçus très rapides. Essayez des méthodes de sampler alternatives si vous souhaitez un comportement transitoire différent, puis gardez la graine fixe pour que les comparaisons soient équitables. Augmentez la force de guidage pour une adhérence plus étroite à votre invite Ace Step 1.5, réduisez-la pour une improvisation plus libre.
EmptyAceStep1.5LatentAudio (#98)#
Alloue la durée de la chanson cible comme un tenseur latent pour que chaque étape en aval fonctionne sur la même durée. Définissez cela au nombre de secondes que vous souhaitez dans le rendu final. Les latents plus longs nécessitent plus de calcul et peuvent bénéficier d'un réglage de qualité légèrement supérieur dans le sampler.
ModelSamplingAuraFlow (#78)#
Attache une stratégie d'échantillonnage compatible Ace Step 1.5 qui équilibre la vitesse et la cohérence musicale. Utilisez-la lorsque vous souhaitez des itérations réactives qui maintiennent encore la structure globale intacte. Si vous expérimentez avec différentes familles de sampler, utilisez la même graine pour évaluer comment le timing et les transitoires changent.
SaveAudioMP3 (#104)#
Exporte la forme d'onde décodée dans un fichier compressé. Sélectionnez le débit binaire pour équilibrer la taille et la fidélité pour votre destination de diffusion ou de partage. Pour l'archivage ou le mixage, vous pouvez remplacer cela par un nœud de sauvegarde WAV à la même position.
ConditioningZeroOut (#47)#
Fournit un conditionnement négatif neutre, ce qui est un choix sûr par défaut pour la génération musicale basée sur les paroles. Remplacez-le par une invite négative personnalisée si vous avez besoin d'exclusions explicites comme pas de voix ou moins d'artefacts haute fréquence. Gardez les instructions positives et négatives conceptuellement distinctes pour éviter les conflits.
Extras optionnels#
- Commencez avec 30 à 60 secondes pour valider le style, puis prolongez la durée pour compléter le morceau tout en gardant la graine fixe.
- Pour les instrumentaux avec Ace Step 1.5, dites-le explicitement dans l'invite ou mettez "pas de voix" dans un chemin d'invite négatif.
- Traitez les paroles comme des lignes chantables avec un phrasé naturel et des comptes de syllabes cohérents pour améliorer les résultats vocaux.
- Enregistrez les graines prometteuses avec les invites pour pouvoir revenir et mettre à l'échelle plus tard sans perdre l'identité de la chanson.
Références utiles : le projet ComfyUI sur GitHub pour des informations générales d'utilisation ComfyUI et les fichiers Ace Step 1.5 ComfyUI sur Hugging Face pour le checkpoint et les actifs Comfy-Org/ace_step_1.5_ComfyUI_files.
Remerciements#
Ce workflow met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Comfy.org pour le workflow Ace Step 1.5 pour leurs contributions et leur maintenance. Pour des détails autorisés, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Source du Workflow Comfy.org/Ace Step 1.5
- Docs / Notes de Version : Ace Step 1.5 est maintenant disponible dans ComfyUI
Note : L'utilisation des modèles, ensembles de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.