

FLUX LoRA ha ganado una inmensa popularidad en la comunidad de IA, particularmente entre aquellos que buscan afinar modelos de IA con sus propios conjuntos de datos. Este enfoque te permite adaptar sin esfuerzo modelos FLUX preexistentes a tus conjuntos de datos únicos, haciéndolo altamente personalizable y eficiente para una amplia gama de esfuerzos creativos. Si ya estás familiarizado con ComfyUI, usar el flujo de trabajo de ComfyUI FLUX LoRA Training para entrenar tu modelo FLUX LoRA será muy sencillo. El flujo de trabajo y los nodos relacionados fueron creados por Kijai, ¡así que muchas gracias a él por su contribución! Consulta Kijai's GitHub para más información.
Tutorial de ComfyUI FLUX LoRA Training#
El flujo de trabajo de ComfyUI FLUX LoRA Training es un proceso poderoso diseñado para entrenar modelos FLUX LoRA. Entrenar con ComfyUI ofrece varias ventajas, particularmente para los usuarios ya familiarizados con su interfaz. Con FLUX LoRA Training, puedes usar los mismos modelos empleados para inferencia, asegurando que no haya problemas de compatibilidad al trabajar dentro del mismo entorno de Python. Además, puedes construir flujos de trabajo para comparar diferentes configuraciones, mejorando tu proceso de entrenamiento. Este tutorial te guiará a través de los pasos para configurar y usar FLUX LoRA Training en ComfyUI.
Cubriremos:
- Preparando Tu Conjunto de Datos para FLUX LoRA Training
- El Proceso de FLUX LoRA Training
- Ejecutando FLUX LoRA Training
- Cómo y Dónde Usar los Modelos FLUX y FLUX LoRA
1. Preparando Tu Conjunto de Datos para FLUX LoRA Training#
Al preparar tus datos de entrenamiento para FLUX LoRA Training, es esencial tener imágenes de alta calidad para tu sujeto objetivo.
En este ejemplo, estamos entrenando un modelo FLUX LoRA para generar imágenes de un influencer específico. Para esto, necesitarás un conjunto de imágenes de alta calidad del influencer en varias poses y entornos. Una forma conveniente de reunir estas imágenes es usar el workflow de ComfyUI Consistent Character, que facilita la generación de una colección de imágenes que muestran el mismo personaje en diferentes poses mientras se mantiene su apariencia consistente. Para nuestro conjunto de datos de entrenamiento, hemos seleccionado cinco imágenes de alta calidad del influencer en varias poses y entornos, asegurando que el conjunto de datos sea lo suficientemente robusto para que FLUX LoRA Training aprenda los detalles intrincados necesarios para producir salidas consistentes y precisas.
Proceso para Obtener Datos de Entrenamiento#
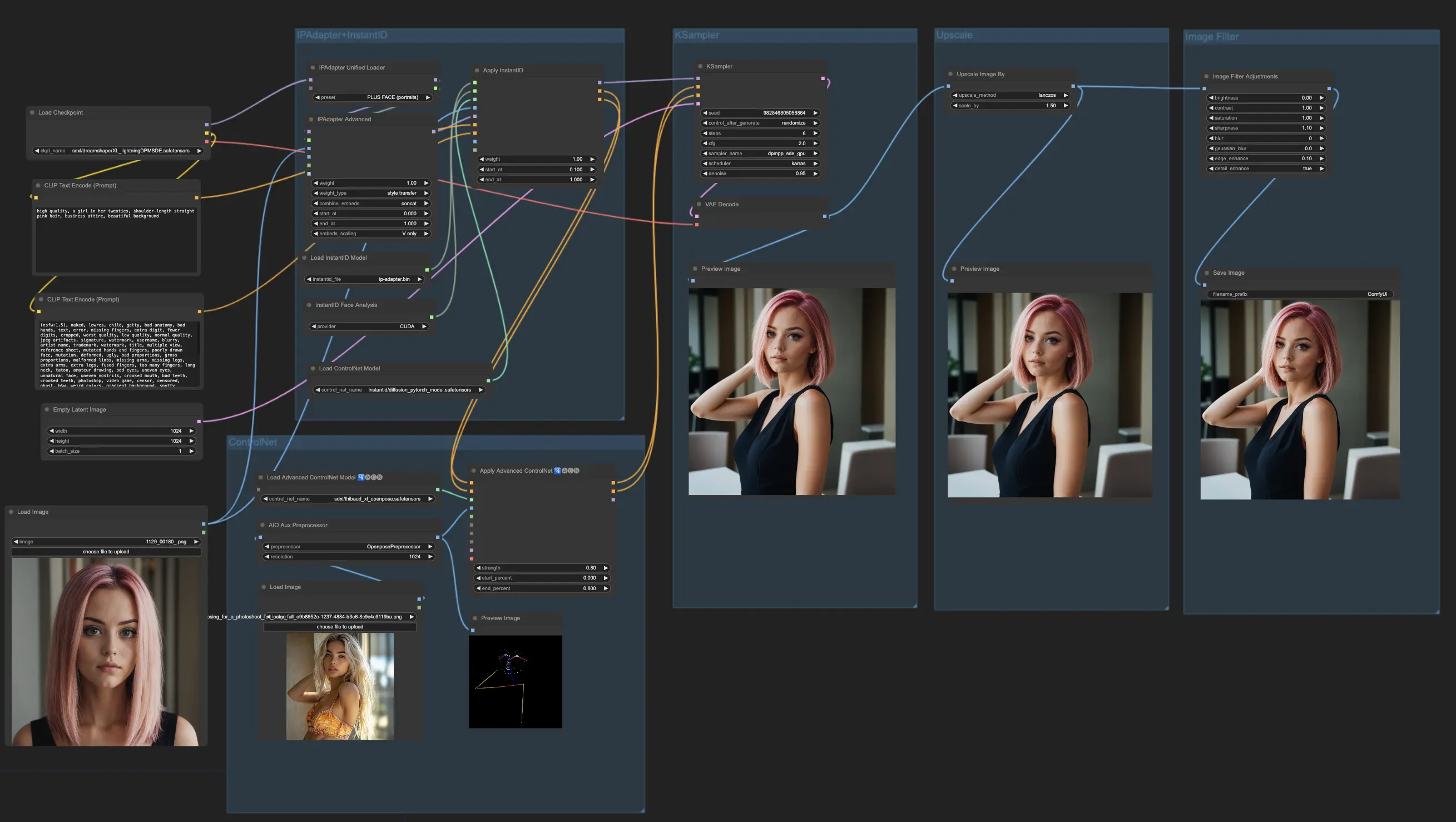
Ejemplo de Datos de Entrenamiento#

También puedes recopilar tu propio conjunto de datos según tus necesidades específicas——FLUX LoRA Training es flexible y funciona con varios tipos de datos.
2. El Proceso de FLUX LoRA Training#
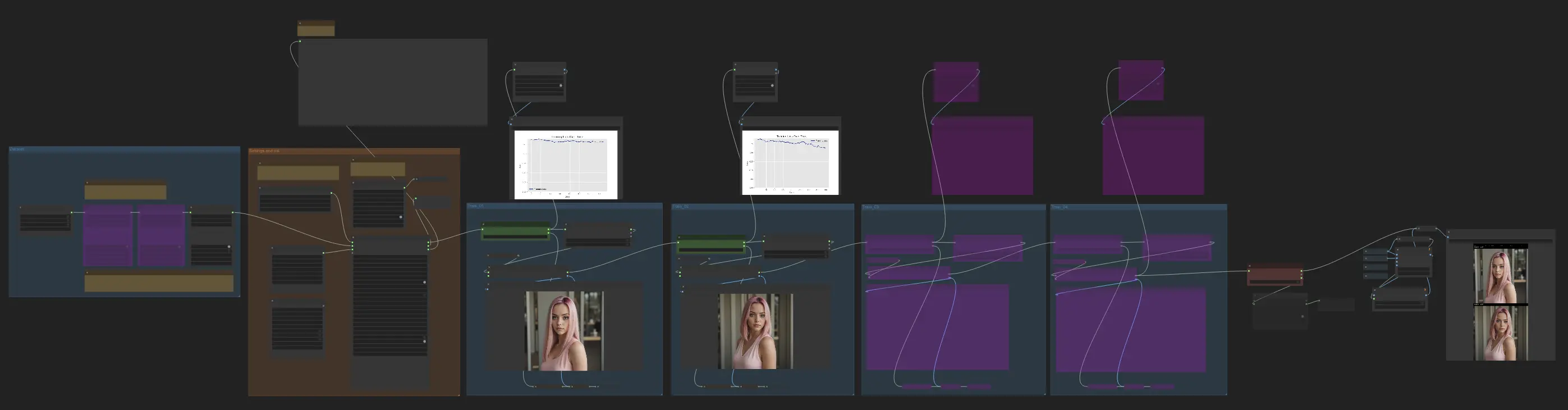
El flujo de trabajo de FLUX LoRA Training consiste en varios nodos clave que trabajan juntos para entrenar y validar tu modelo. Aquí tienes una visión detallada de los nodos principales, separados en tres partes: Dataset, Configuración e Inicialización, y Entrenamiento.
2.1. Establecer Conjuntos de Datos para FLUX LoRA Training#
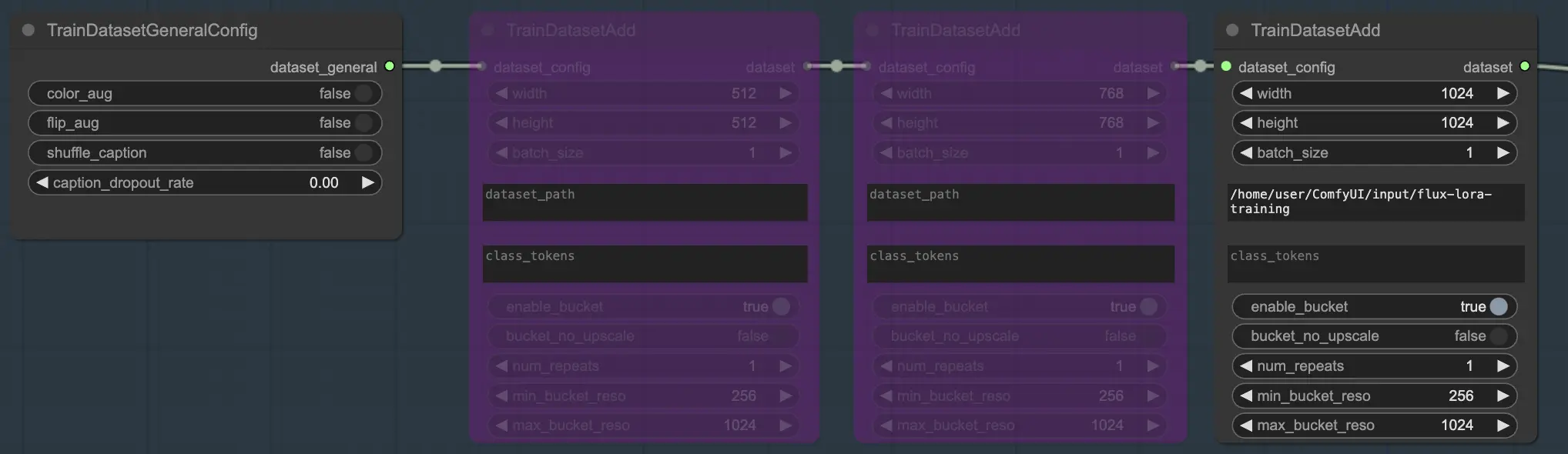
La sección de Dataset consta de dos nodos esenciales que te ayudan a configurar y personalizar tus datos de entrenamiento: TrainDatasetGeneralConfig y TrainDatasetAdd.
2.1.1. TrainDatasetGeneralConfig#
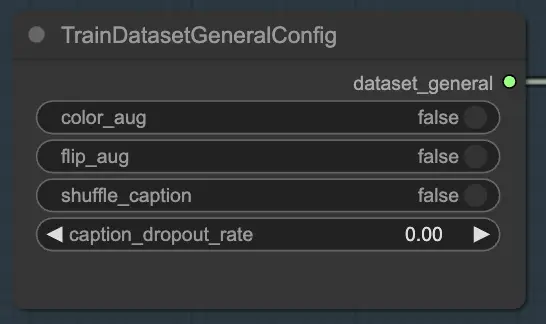
El nodo TrainDatasetGeneralConfig es donde defines la configuración general para tu conjunto de datos de entrenamiento en FLUX LoRA Training. Este nodo te da control sobre varios aspectos de la augmentación y preprocesamiento de datos. Por ejemplo, puedes elegir habilitar o deshabilitar la augmentación de color, que puede ayudar a mejorar la capacidad del modelo para generalizar a través de diferentes variaciones de color. De manera similar, puedes alternar la augmentación de volteo para voltear imágenes aleatoriamente de manera horizontal, proporcionando muestras de entrenamiento más diversas. Además, tienes la opción de barajar las leyendas asociadas con cada imagen, introduciendo aleatoriedad y reduciendo el sobreajuste. La tasa de abandono de leyendas te permite eliminar aleatoriamente leyendas durante el entrenamiento, lo que puede ayudar al modelo a volverse más robusto ante leyendas faltantes o incompletas.
2.1.2. TrainDatasetAdd#
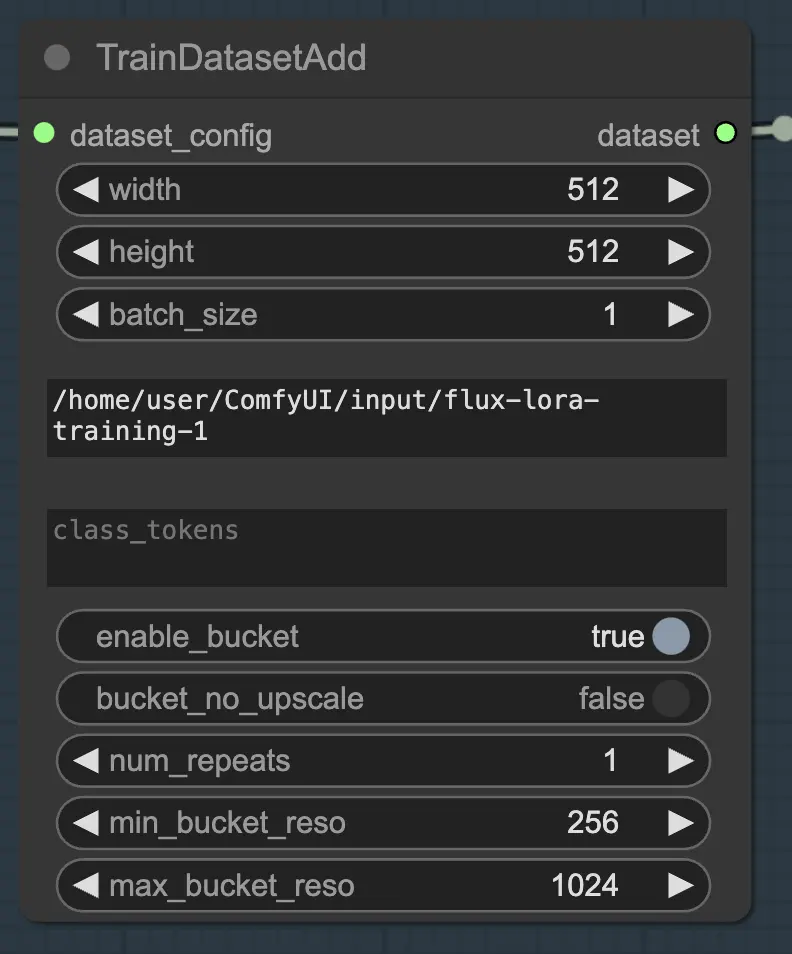
El nodo TrainDatasetAdd es donde especificas los detalles de cada conjunto de datos individual para incluir en tu FLUX LoRA Training.
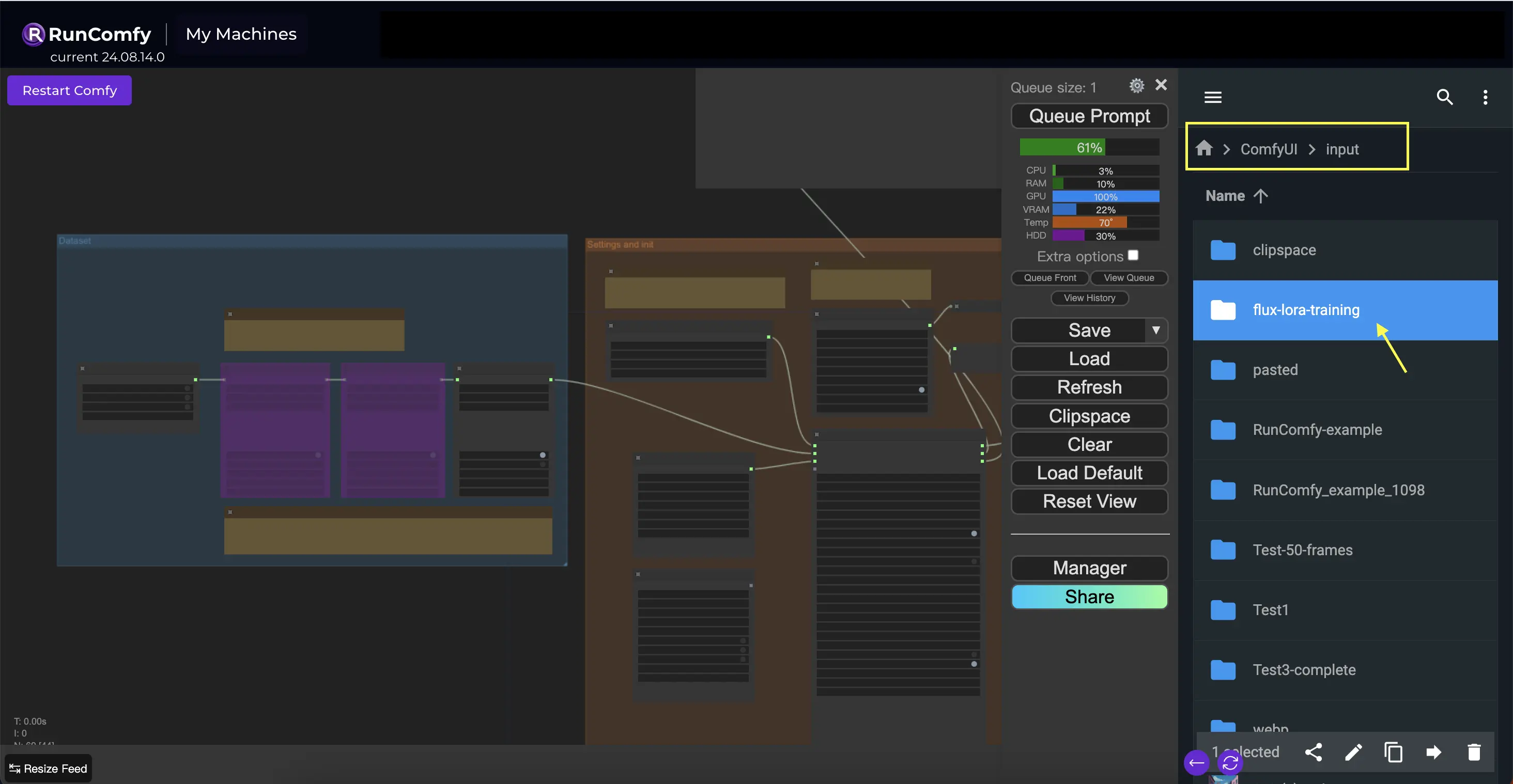
Directorio de entrada: Ruta del Conjunto de Datos de Entrenamiento#
Para aprovechar al máximo este nodo, es importante organizar tus datos de entrenamiento adecuadamente. Al usar el navegador de archivos de RunComfy, coloca los datos de entrenamiento en el directorio /home/user/ComfyUI/input/{file-name}, donde {file-name} es un nombre significativo que asignas a tu conjunto de datos.
Una vez que hayas colocado tus datos de entrenamiento en el directorio adecuado, necesitas proporcionar la ruta a ese directorio en el parámetro image_dir del nodo TrainDatasetAdd. Esto le indica al nodo dónde encontrar tus imágenes de entrenamiento.
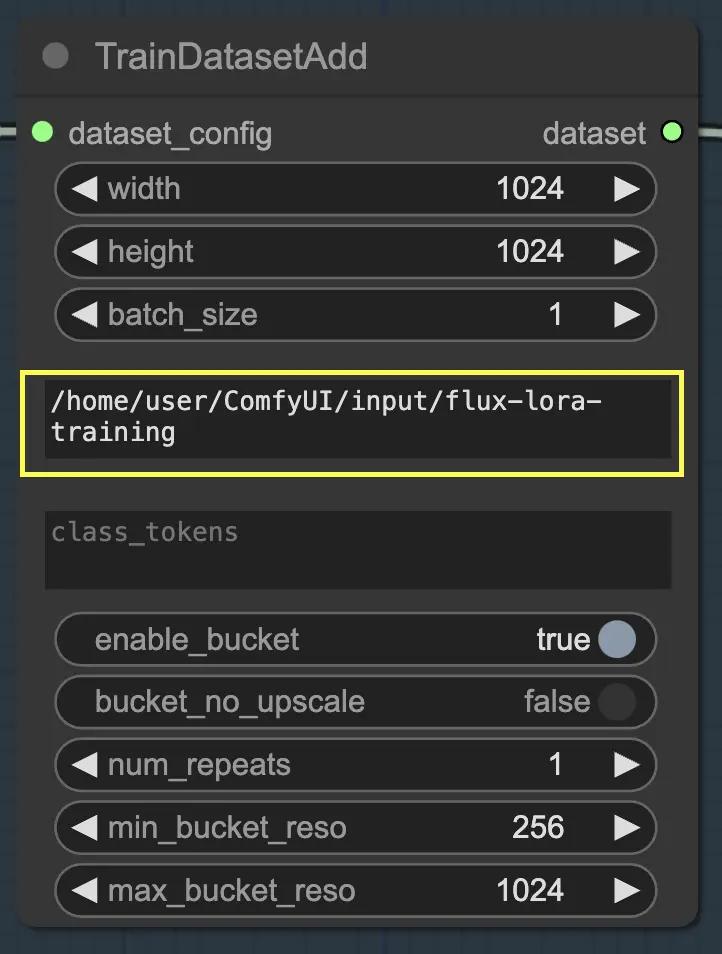
Token de Clase#
Si tu conjunto de datos se beneficia del uso de tokens de clase o palabras clave específicas, puedes ingresarlas en el parámetro class_tokens. Los tokens de clase son palabras o frases especiales que se anteponen a cada leyenda y ayudan a guiar el proceso de generación del modelo. Por ejemplo, si estás entrenando en un conjunto de datos de varias especies animales, podrías usar tokens de clase como "dog", "cat" o "bird" para indicar el animal deseado en las imágenes generadas. Cuando luego uses estos tokens de clase en tus indicaciones, puedes controlar qué aspectos específicos deseas que el modelo genere.
Establecer la resolución (ancho y alto), tamaño de lote#
Además de los parámetros image_dir y class_tokens, el nodo TrainDatasetAdd proporciona varias otras opciones para afinar tu conjunto de datos. Puedes establecer la resolución (ancho y alto) de las imágenes, especificar el tamaño de lote para el entrenamiento y determinar cuántas veces debe repetirse el conjunto de datos por época.
Múltiples conjuntos de datos#
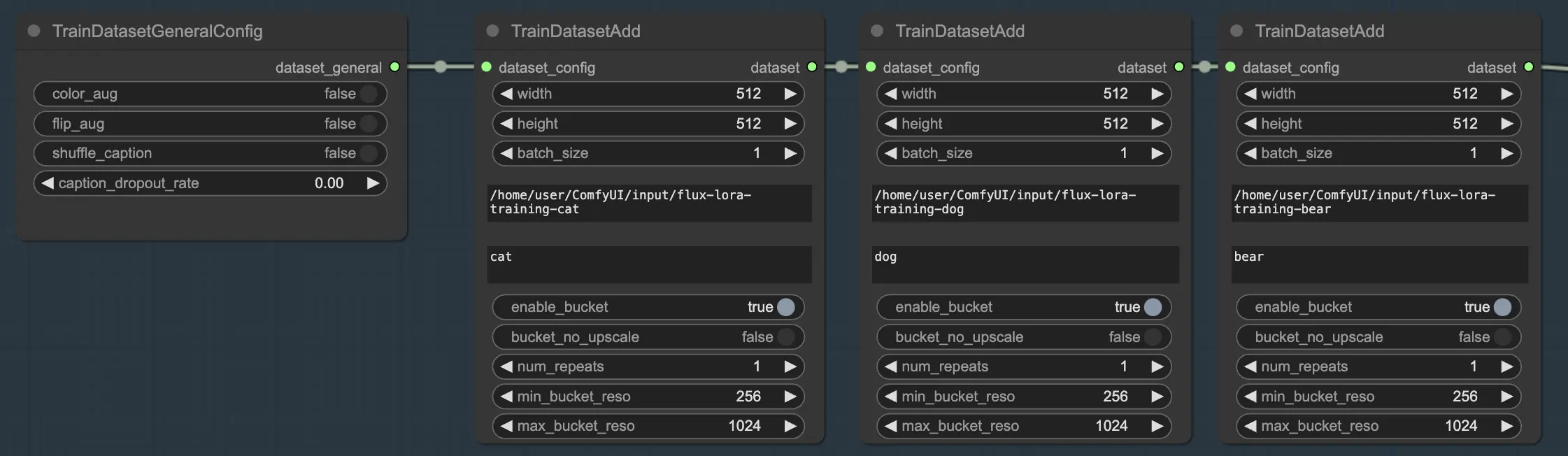
Una de las características poderosas de FLUX LoRA Training es la capacidad de combinar múltiples conjuntos de datos sin problemas. En el flujo de trabajo de FLUX LoRA Training, hay tres nodos TrainDatasetAdd conectados en secuencia. Cada nodo representa un conjunto de datos distinto con su propia configuración única. Al enlazar estos nodos, puedes crear un conjunto de entrenamiento rico y diverso que incorpore imágenes y leyendas de varias fuentes.
Para ilustrar esto, consideremos un escenario donde tienes tres conjuntos de datos separados: uno para gatos, uno para perros y otro para osos. Puedes configurar tres nodos TrainDatasetAdd, cada uno dedicado a uno de estos conjuntos de datos. En el primer nodo, especificarías la ruta al conjunto de datos "cats" en el parámetro image_dir, establecerías el class token en "cat", y ajustarías otros parámetros como la resolución y el tamaño de lote para satisfacer tus necesidades. De manera similar, configurarías los nodos segundo y tercero para los conjuntos de datos "dogs" y "bears", respectivamente.
Este enfoque permite que el proceso de FLUX LoRA Training aproveche una amplia gama de imágenes, mejorando la capacidad del modelo para generalizar a través de diferentes categorías.
Ejemplo#
En nuestro ejemplo, usamos solo un conjunto de datos para entrenar el modelo, por lo que habilitamos un nodo TrainDatasetAdd y omitimos los otros dos. Así es como puedes configurarlo:
2.2. Configuración e Inicialización#
La sección de Configuración e Inicialización es donde configuras los componentes clave y parámetros para FLUX LoRA Training. Esta sección incluye varios nodos esenciales que trabajan juntos para configurar tu entorno de entrenamiento.
2.2.1. FluxTrainModelSelect#
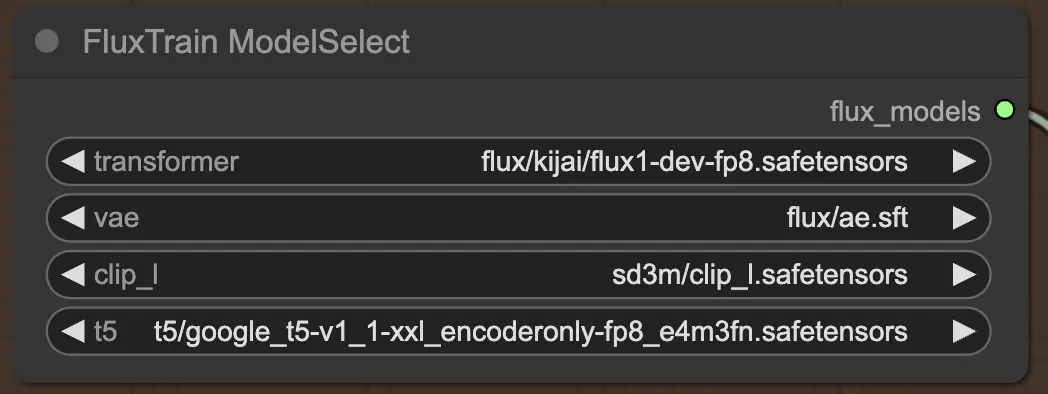
Primero, tienes el nodo FluxTrainModelSelect, que es responsable de seleccionar los modelos FLUX que se usarán durante FLUX LoRA Training. Este nodo te permite especificar las rutas a cuatro modelos críticos: el transformer, VAE (Autoencoder Variacional), CLIP_L (Preentrenamiento de Lenguaje e Imagen Contrastiva) y T5 (Transformador de Transferencia de Texto a Texto). Estos modelos forman la columna vertebral del proceso de entrenamiento de FLUX, y todos se han configurado en la plataforma RunComfy.
2.2.2. OptimizerConfig#
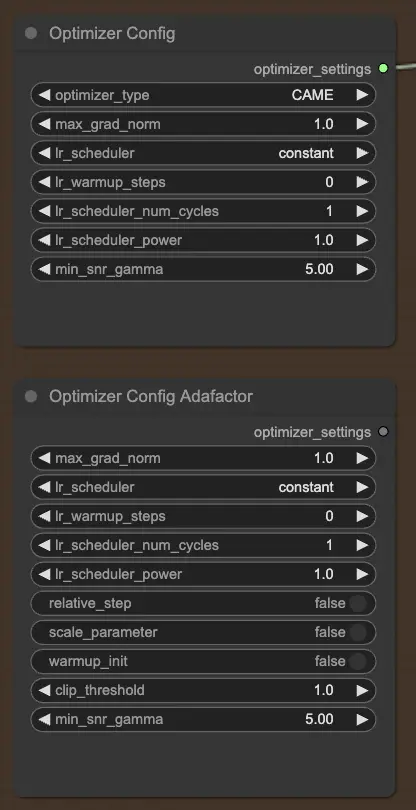
El nodo OptimizerConfig es crucial para configurar el optimizador dentro de FLUX LoRA Training, que determina cómo se actualizan los parámetros del modelo durante el entrenamiento. Puedes elegir el tipo de optimizador (por ejemplo, AdamW, CAME), establecer la norma máxima de gradiente para recortar gradientes y evitar gradientes explosivos, y seleccionar el programador de tasa de aprendizaje (por ejemplo, constante, coseno decreciente). Además, puedes afinar parámetros específicos del optimizador como pasos de calentamiento y potencia del programador, y proporcionar argumentos adicionales para una mayor personalización.
Si prefieres el optimizador Adafactor, conocido por su eficiencia de memoria y capacidad para manejar modelos grandes, puedes usar el nodo OptimizerConfigAdafactor en su lugar.
2.2.3. InitFluxLoRATraining#
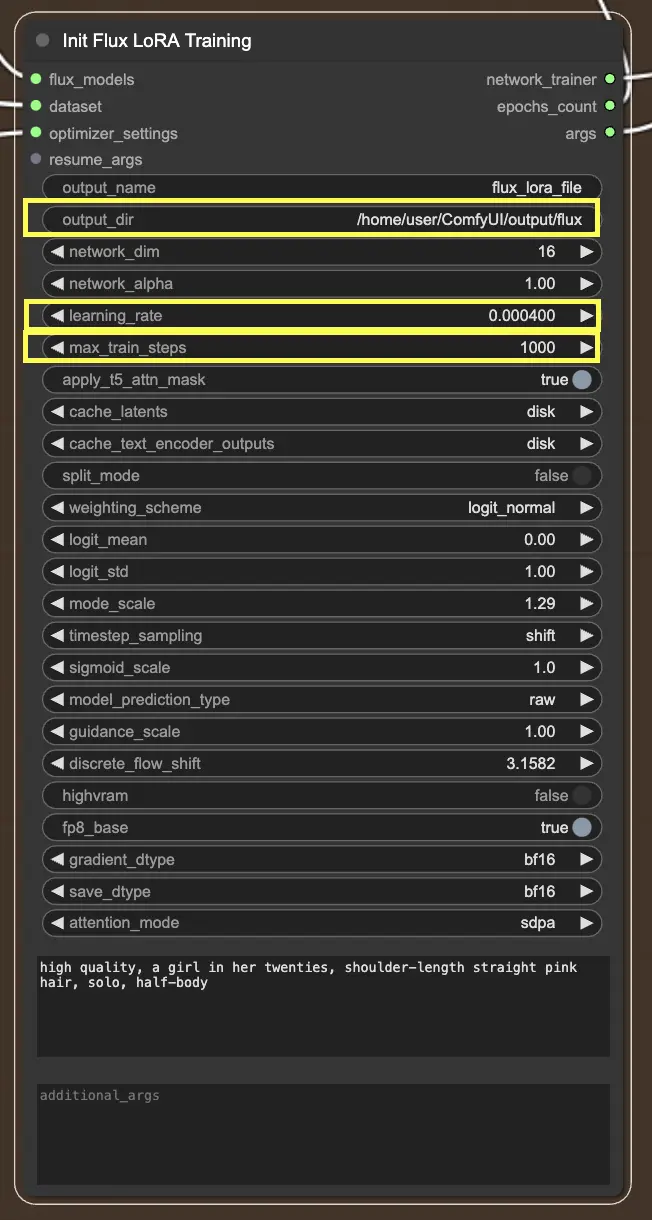
El nodo InitFluxLoRATraining es el centro donde convergen todos los componentes esenciales para iniciar el proceso de FLUX LoRA Training.
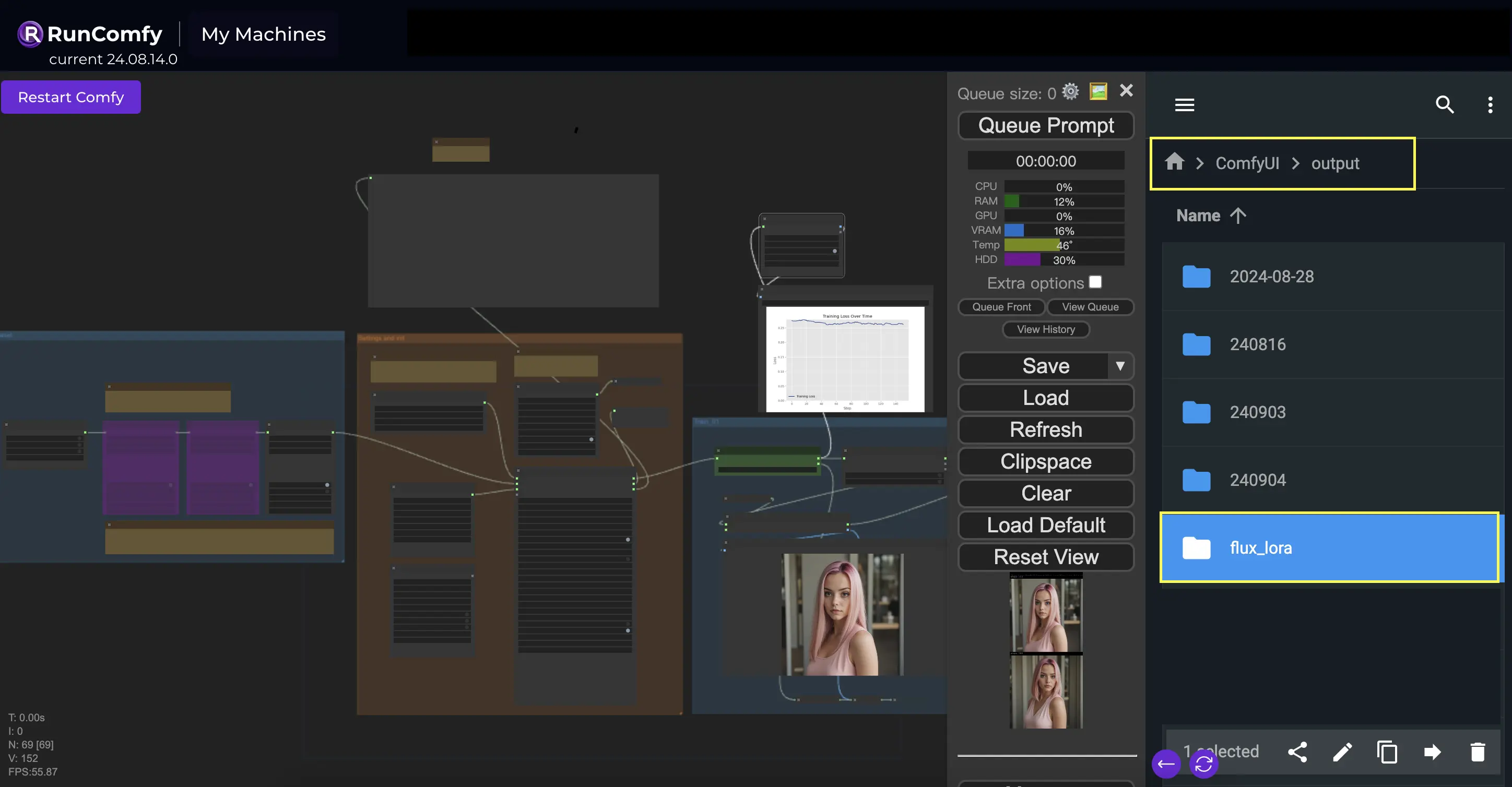
Directorio de salida: Ruta FLUX LoRA#
Una de las cosas clave que necesitarás especificar en el nodo InitFluxLoRATraining es el directorio de salida, donde se guardará tu modelo entrenado. En la plataforma RunComfy, puedes elegir /home/user/ComfyUI/output/{file_name} como la ubicación para tu salida. Una vez que el entrenamiento esté completo, podrás verlo en el navegador de archivos.
Dimensiones de la red y tasas de aprendizaje#
A continuación, querrás establecer las dimensiones de la red y las tasas de aprendizaje. Las dimensiones de la red determinan el tamaño y la complejidad de tu red LoRA, mientras que las tasas de aprendizaje controlan la rapidez con la que tu modelo aprende y se adapta.
Máximos pasos de entrenamiento#
Otro parámetro importante a considerar es el max_train_steps. Determina cuánto tiempo deseas que dure el proceso de entrenamiento, o en otras palabras, cuántos pasos deseas que tome tu modelo antes de estar completamente entrenado. Puedes ajustar este valor en función de tus necesidades específicas y el tamaño de tu conjunto de datos. Se trata de encontrar ese punto óptimo donde tu modelo ha aprendido lo suficiente para producir salidas de calidad.
2.3.4. FluxTrainValidationSettings#
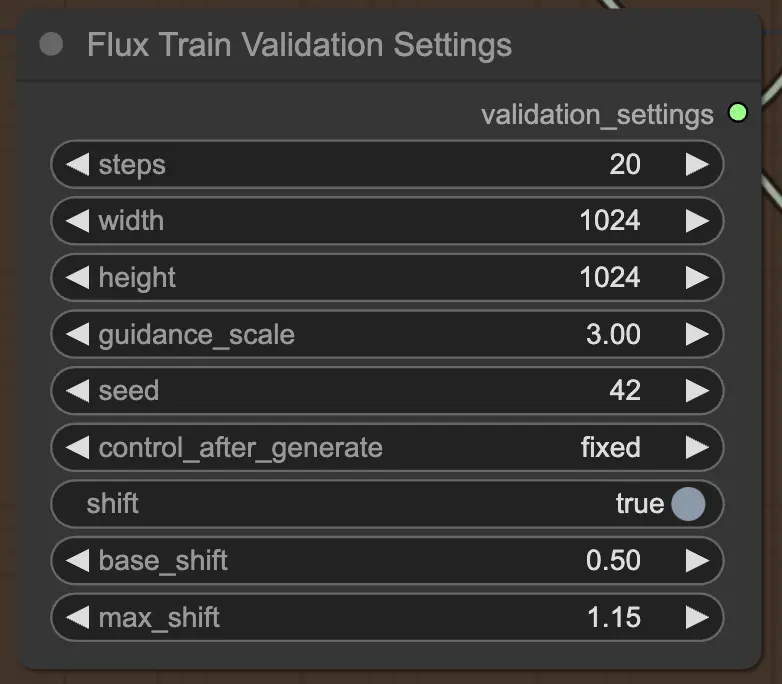
Finalmente, el nodo FluxTrainValidationSettings te permite configurar los ajustes de validación para evaluar el rendimiento de tu modelo durante el proceso de FLUX LoRA Training. Puedes establecer el número de pasos de validación, tamaño de imagen, escala de orientación y semilla para reproducibilidad. Además, puedes elegir el método de muestreo de pasos de tiempo y ajustar los parámetros de escala y cambio sigmoide para controlar la programación de pasos de tiempo y mejorar la calidad de las imágenes generadas.
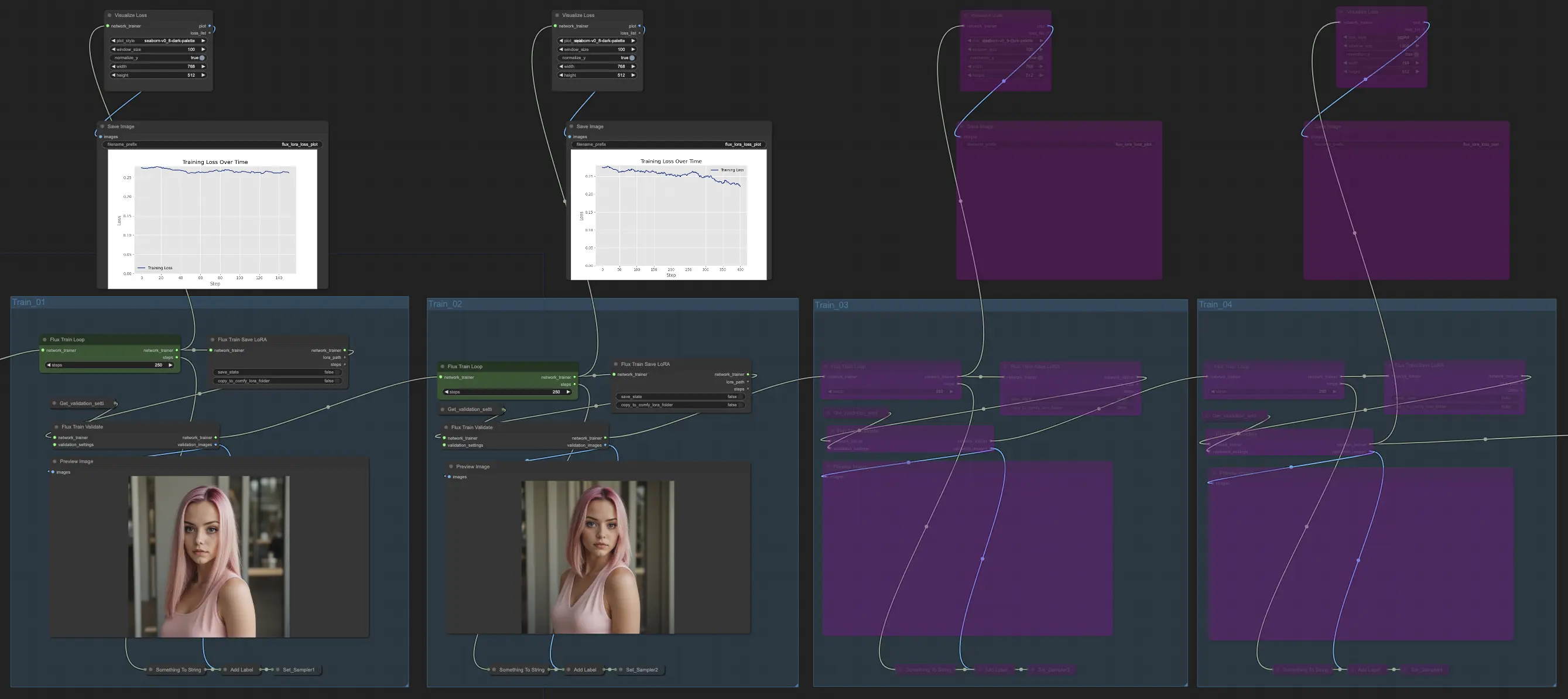
3. Entrenamiento#
La sección de Entrenamiento de FLUX LoRA Training es donde sucede la magia. Está dividida en cuatro partes: Train_01, Train_02, Train_03 y Train_04. Cada una de estas partes representa una etapa diferente en el proceso de FLUX LoRA Training, permitiéndote refinar y mejorar gradualmente tu modelo.
3.1. Train_01#
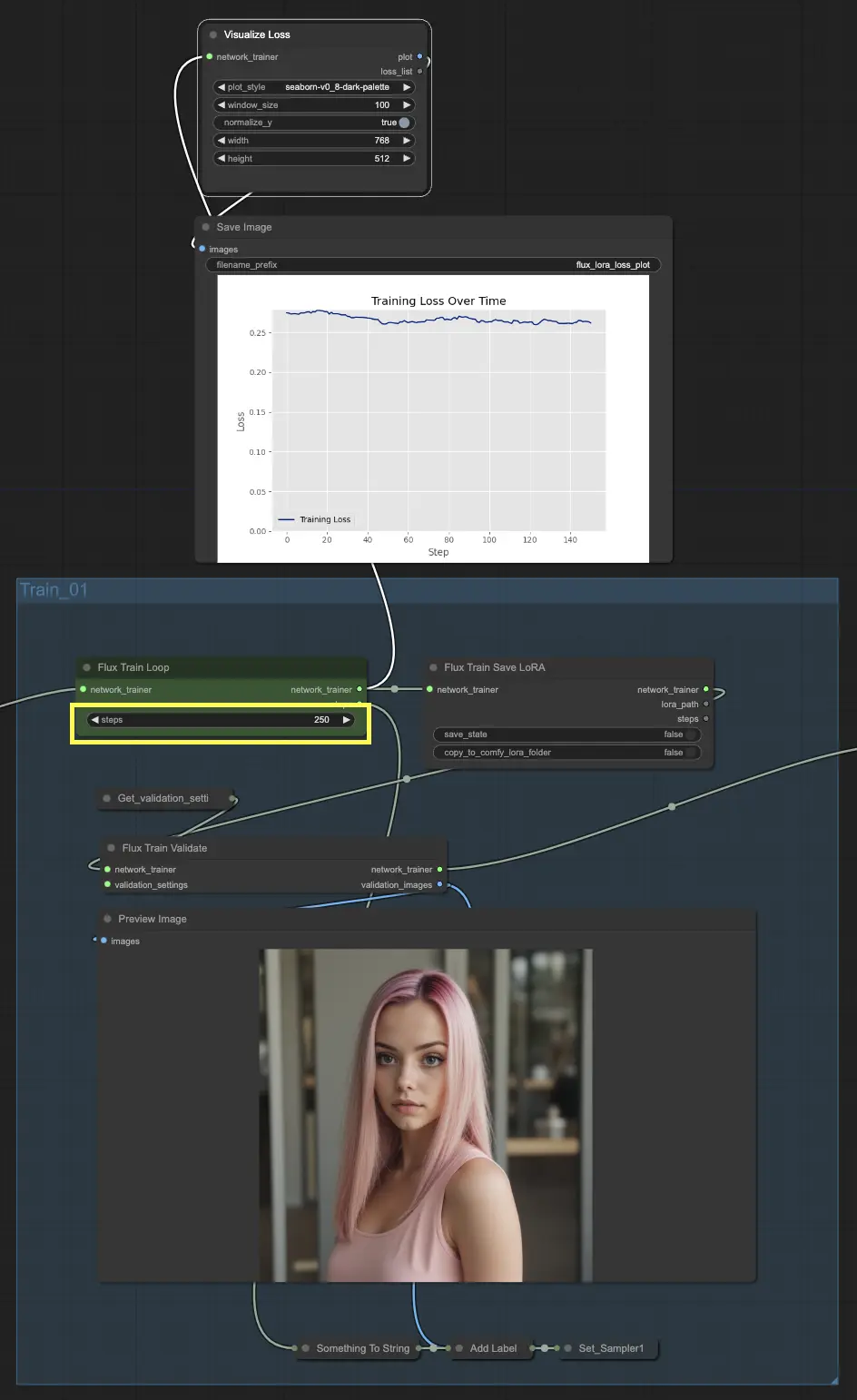
Comencemos con Train_01. Aquí es donde tiene lugar el bucle de entrenamiento inicial. La estrella de esta sección es el nodo FluxTrainLoop, que es responsable de ejecutar el bucle de entrenamiento durante un número especificado de pasos. En este ejemplo, lo hemos configurado a 250 pasos, pero puedes ajustar esto según tus necesidades. Una vez que el bucle de entrenamiento se completa, el modelo entrenado se pasa al nodo FluxTrainSave, que guarda el modelo a intervalos regulares. Esto asegura que tengas puntos de control de tu modelo en diferentes etapas del entrenamiento, lo que puede ser útil para rastrear el progreso y recuperarse de interrupciones inesperadas.
Pero el entrenamiento no se trata solo de guardar el modelo. También necesitamos validar su rendimiento para ver qué tan bien está funcionando. Ahí es donde entra el nodo FluxTrainValidate. Toma el modelo entrenado y lo pone a prueba usando un conjunto de datos de validación. Este conjunto de datos es separado de los datos de entrenamiento y ayuda a evaluar qué tan bien el modelo generaliza a ejemplos no vistos. El nodo FluxTrainValidate genera imágenes de muestra basadas en los datos de validación, dándote una representación visual de la salida del modelo en esta etapa.
Para mantener un ojo en el progreso del entrenamiento, tenemos el nodo VisualizeLoss. Este práctico nodo visualiza la pérdida de entrenamiento a lo largo del tiempo, permitiéndote ver qué tan bien está aprendiendo el modelo y si está convergiendo hacia una buena solución. Es como tener un entrenador personal que rastrea tu progreso y te ayuda a mantener el rumbo.
3.2. Train_02, Train_03, Train_04#
En Train_02, continuando desde Train_01 en el FLUX LoRA Training, la salida se entrena aún más durante un número adicional de pasos especificado (por ejemplo, 250 pasos). Train_03 y Train_04 siguen un patrón similar, extendiendo el entrenamiento con conexiones actualizadas para una progresión fluida. Cada etapa produce un modelo FLUX LoRA, permitiéndote probar y comparar el rendimiento.
Ejemplo#
En nuestro ejemplo, hemos optado por usar solo Train_01 y Train_02, cada uno ejecutándose por 250 pasos. Hemos omitido Train_03json y Train_04 por ahora. Pero siéntete libre de experimentar y ajustar el número de secciones de entrenamiento y pasos según tus necesidades y recursos específicos.
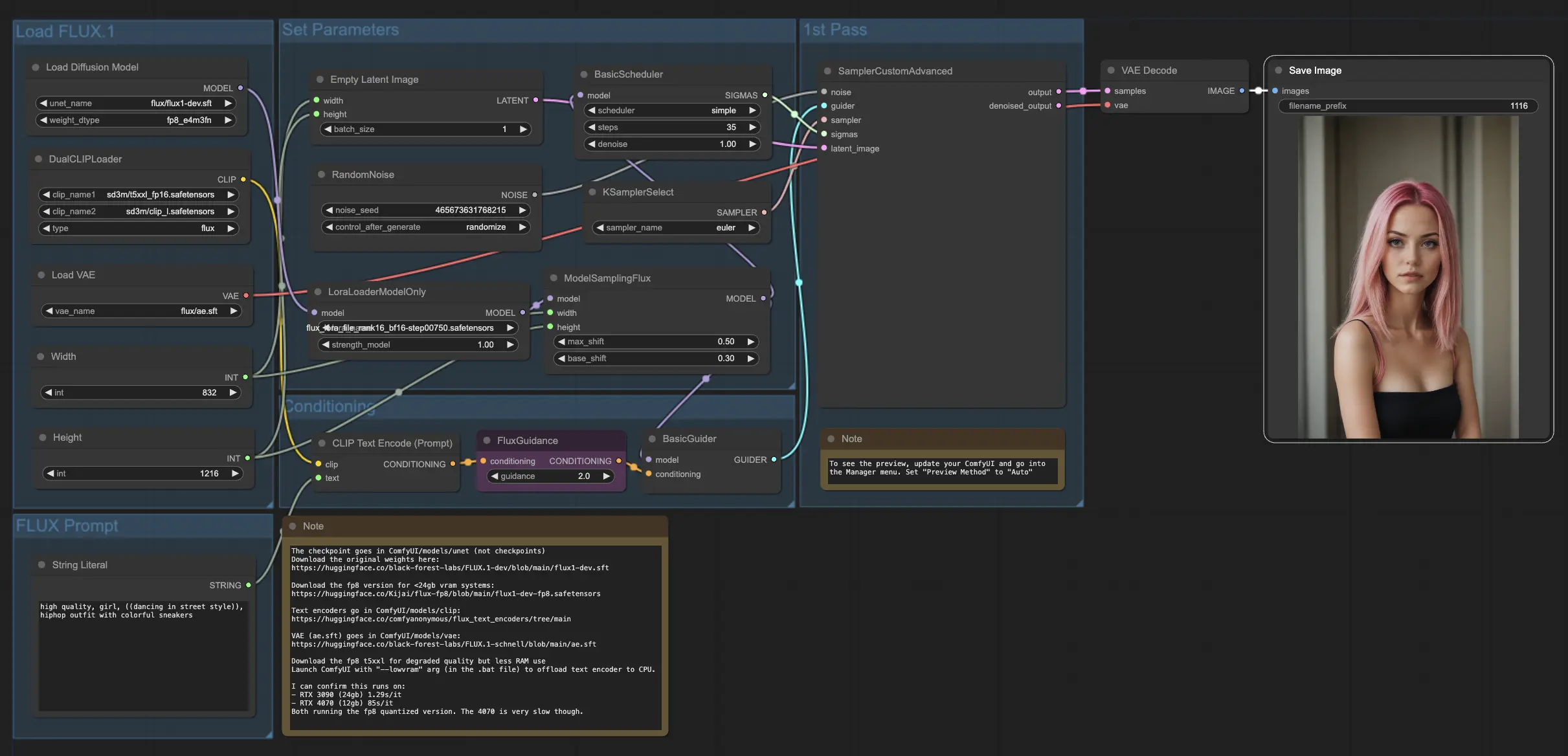
4. Cómo y Dónde Usar los Modelos FLUX y FLUX LoRA#
Una vez que tengas el modelo FLUX LoRA, puedes incorporarlo en el flujo de trabajo FLUX LoRA. Reemplaza el modelo LoRA existente con tu modelo entrenado, luego prueba los resultados para evaluar su rendimiento.
Ejemplo#
En nuestro ejemplo, usamos el flujo de trabajo FLUX LoRA para generar más imágenes del influencer aplicando el modelo FLUX LoRA y observando su rendimiento.
Licencia#
Ver archivos de licencia:
flux/model_licenses/LICENSE-FLUX1-dev
flux/model_licenses/LICENSE-FLUX1-schnell
El Modelo FLUX.1 [dev] está licenciado por Black Forest Labs. Inc. bajo la Licencia No Comercial FLUX.1 [dev]. Derechos de autor Black Forest Labs. Inc.
EN NINGÚN CASO BLACK FOREST LABS, INC. SERÁ RESPONSABLE DE NINGUNA RECLAMACIÓN, DAÑOS U OTRA RESPONSABILIDAD, YA SEA EN UNA ACCIÓN DE CONTRATO, AGRAVIO O DE OTRO MODO, QUE SURJA DE, O EN CONEXIÓN CON EL USO DE ESTE MODELO.






