
Character AI Ovi: imagen a video con habla sincronizada en ComfyUI#
Character AI Ovi es un flujo de generación audiovisual que convierte una sola imagen en un personaje parlante y en movimiento con sonido coordinado. Construido sobre la familia de modelos Wan e integrado a través del WanVideoWrapper, genera video y audio en una sola pasada, ofreciendo animación expresiva, sincronización labial inteligible y ambiente consciente del contexto. Si haces historias cortas, anfitriones virtuales o clips sociales cinematográficos, Character AI Ovi te permite pasar de arte estático a una actuación completa en minutos.
Este flujo de trabajo de ComfyUI acepta una imagen más un aviso de texto que contiene marcado ligero para diseño de habla y sonido. Compone cuadros y forma de onda juntos para que la boca, el ritmo y el audio de la escena se sientan naturalmente alineados. Character AI Ovi está diseñado para creadores que quieren resultados pulidos sin ensamblar herramientas TTS y de video por separado.
Modelos clave en el flujo de trabajo de Comfyui Character AI Ovi#
- Ovi: Fusión Multimodal de Backbone Gemelo para Generación de Audio-Video. El modelo central que produce conjuntamente video y audio a partir de avisos de texto o texto+imagen. character-ai/Ovi
- Backbone de video Wan 2.2 y VAE. El flujo de trabajo utiliza el VAE de video de alta compresión de Wan para generación eficiente de 720p, 24 fps mientras preserva el detalle y la coherencia temporal. Wan-AI/Wan2.2-TI2V-5B-Diffusers • Wan-Video/Wan2.2
- Codificador de texto Google UMT5-XXL. Codifica el aviso, incluidas las etiquetas de habla, en representaciones multilingües ricas que impulsan ambas ramas. google/umt5-xxl
- MMAudio VAE con vocoder BigVGAN. Decodifica los latentes de audio del modelo a habla y efectos de alta calidad con timbre natural. hkchengrex/MMAudio • nvidia/bigvgan_v2_44khz_128band_512x
- Pesos Ovi listos para ComfyUI por Kijai. Checkpoints curados para la rama de video, rama de audio y VAE en variantes escaladas bf16 y fp8. Kijai/WanVideo_comfy/Ovi • Kijai/WanVideo_comfy_fp8_scaled/TI2V/Ovi
- Nodos WanVideoWrapper para ComfyUI. Wrapper que expone características de Wan y Ovi como nodos composables. kijai/ComfyUI-WanVideoWrapper
Cómo usar el flujo de trabajo Comfyui Character AI Ovi#
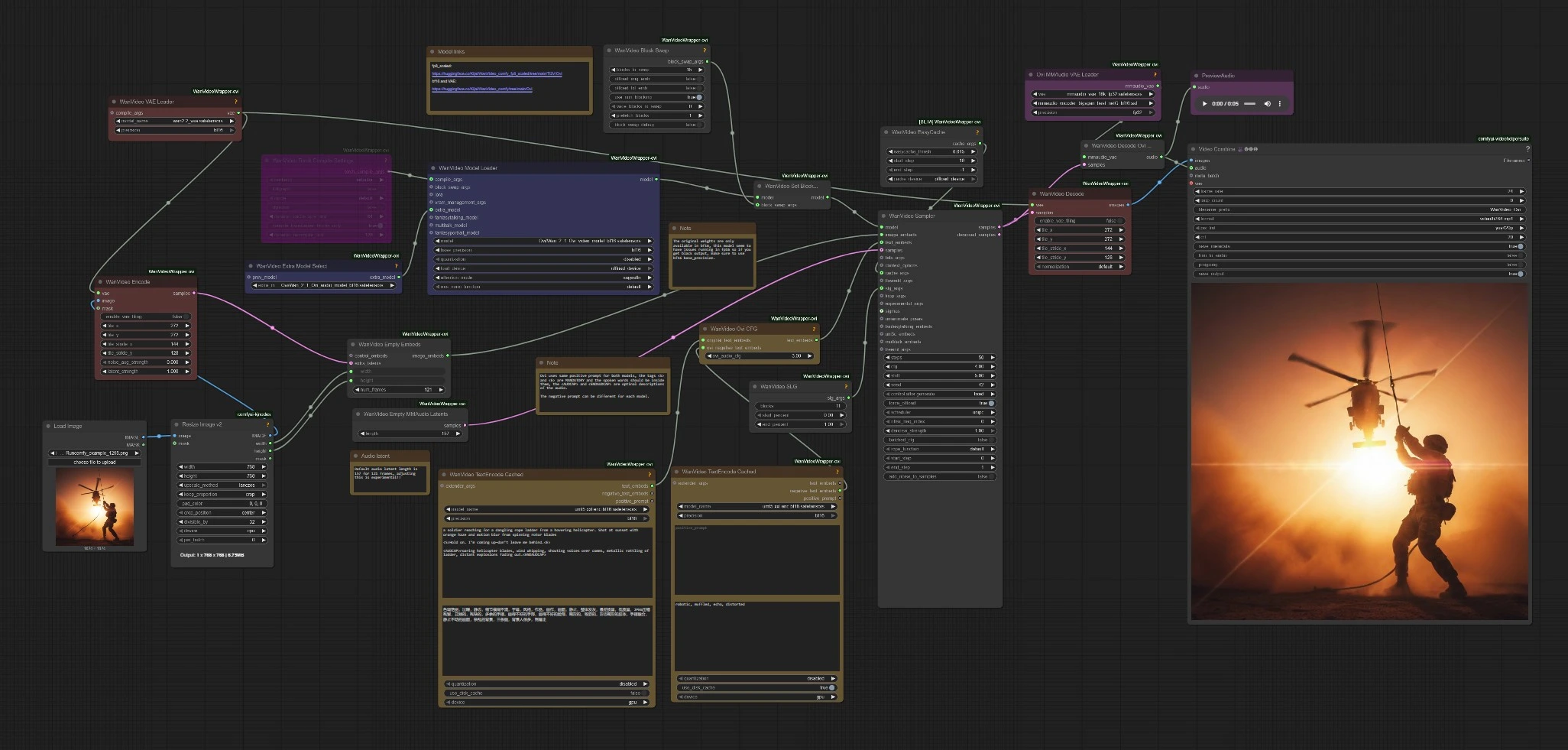
Este flujo sigue un camino simple: codifica tu aviso e imagen, carga los checkpoints de Ovi, muestrea latentes conjuntos de audio+video, luego decodifica y combina a MP4. Las subsecciones a continuación mapean los clústeres de nodos visibles para que sepas dónde interactuar y qué cambios afectan los resultados.
Redacción de avisos para habla y sonido#
Escribe un aviso positivo para la escena y la línea hablada. Usa las etiquetas Ovi exactamente como se muestran: envuelve las palabras a ser habladas con <S> y <E>, y opcionalmente describe audio no hablado con <AUDCAP> y <ENDAUDCAP>. El mismo aviso positivo condiciona tanto la rama de video como la de audio para que el movimiento de los labios y el tiempo se alineen. Puedes usar diferentes avisos negativos para video y audio para suprimir artefactos de manera independiente. Character AI Ovi responde bien a instrucciones escénicas concisas más una sola línea clara de diálogo.
Ingesta y acondicionamiento de imágenes#
Carga un solo retrato o imagen de personaje, luego el flujo de trabajo la redimensiona y codifica a latentes. Esto establece identidad, pose y encuadre inicial para el muestreador. El ancho y la altura de la etapa de redimensionamiento establecen el aspecto del video; elige cuadrado para avatares o vertical para cortos. Los latentes codificados y los incrustados derivados de la imagen guían al muestreador para que el movimiento se sienta anclado al rostro original.
Carga de modelos y ayudas de rendimiento#
Character AI Ovi carga tres elementos esenciales: el modelo de video Ovi, el VAE Wan 2.2 para cuadros y el MMAudio VAE más BigVGAN para audio. La compilación de Torch y un caché ligero están incluidos para acelerar los inicios en caliente. Un ayudante de intercambio de bloques está conectado para reducir el uso de VRAM descargando bloques de transformadores cuando sea necesario. Si tienes restricciones de VRAM, aumenta la descarga de bloques en el nodo de intercambio de bloques y mantén el caché habilitado para ejecuciones repetidas.
Muestreo conjunto con guía#
El muestreador ejecuta las espinas dorsales gemelas de Ovi juntas para que la banda sonora y los cuadros co-evolucionen. Un ayudante de guía de capa de omisión mejora la estabilidad y el detalle sin sacrificar el movimiento. El flujo de trabajo también enruta tus incrustaciones de texto originales a través de un mezclador CFG específico de Ovi para que puedas inclinar el balance entre la estricta adherencia al aviso y una animación más libre. Character AI Ovi tiende a producir el mejor movimiento de labios cuando la línea hablada es corta, literal y solo está encerrada por las etiquetas <S> y <E>.
Decodificación, vista previa y exportación#
Después del muestreo, los latentes de video se decodifican a través del VAE Wan mientras que los latentes de audio se decodifican a través de MMAudio con BigVGAN. Un combinador de video combina cuadros y audio en un MP4 a 24 fps, listo para compartir. También puedes previsualizar el audio directamente para verificar la inteligibilidad del habla antes de guardar. La ruta predeterminada de Character AI Ovi apunta a 5 segundos; extiende con cautela para mantener los labios y el ritmo sincronizados.
Nodos clave en el flujo de trabajo Comfyui Character AI Ovi#
WanVideoTextEncodeCached(#85)
Codifica el aviso principal positivo y el aviso negativo de video en incrustaciones utilizadas por ambas ramas. Mantén el diálogo dentro de <S>…<E> y coloca el diseño de sonido dentro de <AUDCAP>…<ENDAUDCAP>. Para mejor alineación, evita múltiples oraciones en una etiqueta de habla y mantén la línea concisa.
WanVideoTextEncodeCached(#96)
Proporciona una incrustación de texto negativo dedicada para audio. Úsala para suprimir artefactos como tono robótico o reverberación intensa sin afectar los visuales. Comienza con descriptores cortos y expande solo si aún escuchas el problema.
WanVideoOviCFG(#94)
Mezcla las incrustaciones de texto originales con los negativos específicos de audio a través de una guía libre de clasificador consciente de Ovi. Auméntala cuando el contenido del habla se desvíe de la línea escrita o los movimientos de labios se sientan desactivados. Redúcela ligeramente si el movimiento se vuelve rígido o demasiado restringido.
WanVideoSampler(#80)
El corazón de Character AI Ovi. Consume incrustaciones de imagen, incrustaciones de texto conjunto y guía opcional para muestrear un único latente que contiene tanto video como audio. Más pasos aumentan la fidelidad pero también el tiempo de ejecución. Si ves presión de memoria o bloqueos, combina un mayor intercambio de bloques con caché activado, y considera deshabilitar la compilación de torch para una solución de problemas rápida.
WanVideoEmptyMMAudioLatents(#125)
Inicializa la línea de tiempo latente de audio. La longitud predeterminada está ajustada para un clip de 121 cuadros, 24 fps. Ajustar esto para cambiar la duración es experimental; cámbialo solo si entiendes cómo debe seguir el conteo de cuadros.
VHS_VideoCombine(#88)
Combina cuadros decodificados y audio a MP4. Establece la tasa de cuadros para que coincida con tu objetivo de muestreo y activa cortar al audio si deseas que el corte final siga la forma de onda generada. Usa el control CRF para equilibrar el tamaño del archivo y la calidad.
Extras opcionales#
- Usa bf16 para video Ovi y Wan 2.2 VAE. Si encuentras cuadros negros, cambia la precisión base a
bf16para los cargadores de modelos y el codificador de texto. - Mantén los discursos cortos. Character AI Ovi sincroniza los labios de manera más confiable con diálogos cortos de una sola oración dentro de
<S>y<E>. - Separa negativos. Pon artefactos visuales en el aviso negativo de video y artefactos tonales en el aviso negativo de audio para evitar compensaciones no deseadas.
- Previsualiza primero. Usa la previsualización de audio para confirmar claridad y ritmo antes de exportar el MP4 final.
- Obtén los pesos exactos utilizados. El flujo de trabajo espera checkpoints de video y audio Ovi más el VAE Wan 2.2 de los espejos de modelos de Kijai. WanVideo_comfy/Ovi • WanVideo_comfy_fp8_scaled/TI2V/Ovi
Con estas piezas en su lugar, Character AI Ovi se convierte en una tubería compacta y amigable para creadores para avatares parlantes expresivos y escenas narrativas que suenan tan bien como se ven.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos sinceramente a kijai y Character AI por Ovi por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- Fuente de Character AI Ovi
- Flujo de trabajo: wanvideo_2_2_5B_ovi_testing @kijai
- Github: character-ai/Ovi
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.

