
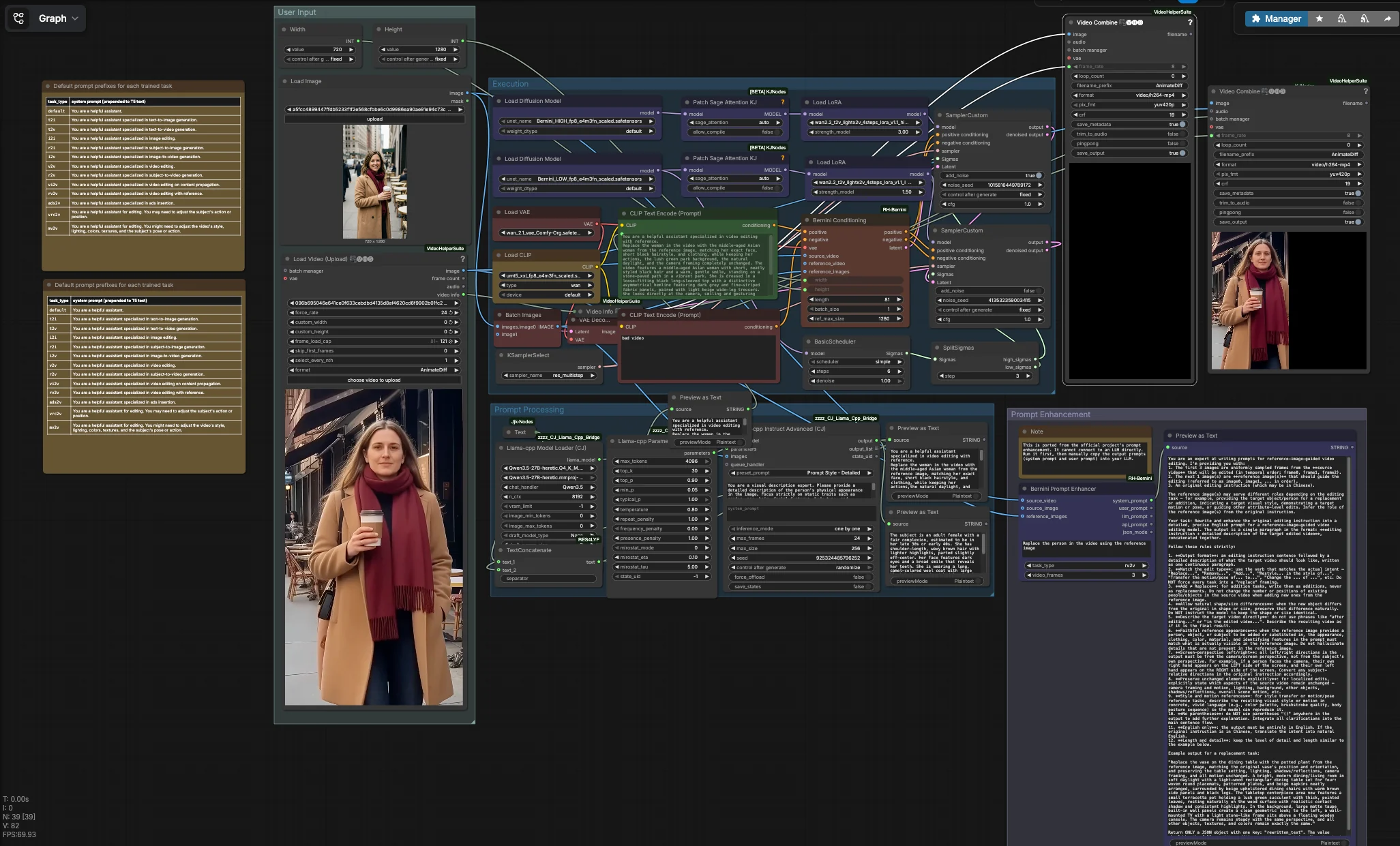
Flujo de trabajo de generación y edición de video multimodal Bernini#
Este flujo de trabajo de generación y edición de video multimodal Bernini es una canalización llave en mano de ComfyUI para la edición de video consciente de la identidad y guiada por referencia, y la transformación de video a video. Combina un video fuente, una o más imágenes de referencia y un texto enfocado para preservar el movimiento y el comportamiento de la cámara mientras reemplaza o reestiliza al sujeto. El flujo de trabajo combina las espinas de difusión alta y baja de Bernini con la codificación de texto estilo Wan, un VAE compatible con Bernini, LightX2V LoRAs y un acondicionamiento específico de Bernini para que los resultados se vean consistentes de cuadro a cuadro.
Diseñado para creadores e investigadores que evalúan Bernini dentro de ComfyUI, el flujo de trabajo sobresale en el reemplazo de personajes, ediciones que preservan el movimiento, imitaciones y generación de forma corta consciente de la cámara. Exporta un MP4 editado más una comparación opcional lado a lado, lo que facilita revisar el impacto de tu texto y conjunto de referencia. A lo largo de este README, el término flujo de trabajo de generación y edición de video multimodal Bernini se refiere a este gráfico de extremo a extremo.
Modelos clave en el flujo de trabajo de generación y edición de video multimodal Bernini en ComfyUI#
- Familia de modelos de difusión Bernini de ByteDance (espinas ALTA y BAJA). Proporciona las redes de denoising principales usadas en un programa de dos etapas: el modelo ALTO maneja la estructura bajo un ruido más fuerte mientras que el modelo BAJO refina detalles y consistencia temporal. Consulta el hub de modelos para referencias de pesos y notas: ByteDance/Bernini.
- Codificador de texto Wan (umT5-XXL). Un codificador T5 estilo Wan que convierte tu instrucción en acondicionamiento para Bernini; expuesto en ComfyUI a través de una interfaz compatible con CLIP. Los activos adecuados para ComfyUI están disponibles aquí: Kijai/WanVideo_comfy_fp8_scaled.
- Wan 2.1 VAE. Realiza la decodificación latente para convertir latentes desruidos en cuadros de video con fidelidad de color que coincide con el entrenamiento de Wan/Bernini. Un VAE listo para ComfyUI está incluido en el mismo paquete de activos: Kijai/WanVideo_comfy_fp8_scaled.
- Par de LoRA LightX2V (high_noise y low_noise). Adaptadores ligeros que guían a Bernini hacia un movimiento estable mientras preservan la identidad de referencia a través de los cuadros. Los pesos de LoRA FP8 proporcionados se alinean con el muestreo de dos etapas usado en este flujo de trabajo y están empaquetados con los activos de Bernini mencionados anteriormente: Kijai/WanVideo_comfy_fp8_scaled.
Cómo usar el flujo de trabajo de generación y edición de video multimodal Bernini en ComfyUI#
Este flujo de trabajo tiene cuatro grupos coordinados. Proporcionas un video fuente y una o más imágenes de referencia, das forma al texto de la instrucción, luego el grupo de Ejecución realiza un pase Bernini de dos fases que decodifica a cuadros y ensambla tu video de salida. Una utilidad paralela puede generar textos de sistema y de usuario estructurados para escritura de texto asistida por LLM.
Entrada del Usuario#
Carga tu video fuente con VHS_LoadVideo (#90). El nodo lee el clip y expone sus metadatos para que el render final herede la tasa de cuadros original, lo que ayuda a preservar la sensación de movimiento. Añade una o más referencias de identidad con LoadImage (#31); las caras frontales, bien iluminadas y con expresiones neutrales funcionan mejor. Establece el tamaño objetivo usando Width (#109) y Height (#110), idealmente igualando la relación de aspecto fuente para evitar estiramientos. Un texto negativo predeterminado es codificado por CLIPTextEncode (#4) para suprimir artefactos comunes en video de baja calidad; puedes refinarlo si es necesario.
Procesamiento de Texto#
Si deseas que la instrucción coincida precisamente con la identidad de referencia, el gráfico puede resumir rasgos estáticos de tus imágenes de referencia usando un LLM local. llama_cpp_model_loader (#93) y llama_cpp_instruct_adv (#92) analizan imágenes agrupadas por BatchImagesNode (#74) y devuelven una descripción concisa de atributos inmutables como cabello, edad y vestimenta. Esa descripción se concatena con tu directiva de tarea desde JjkText (#104) a través de TextConcatenate (#102). El resultado fluye hacia CLIPTextEncode (#3), que se convierte en el acondicionamiento positivo para Bernini. Los nodos de vista previa muestran el texto compuesto para que puedas iterar rápidamente antes de ejecutar las etapas pesadas.
Mejora de Texto#
BerniniPromptEnhancer (#60) genera "textos de sistema" y "de usuario" estructurados adaptados al tipo de tarea seleccionado y a las entradas. Ejecútalo para obtener instrucciones más fuertes que puedes pegar en tu LLM para una expansión de texto más rica; por diseño, no está conectado al gráfico principal. Esta utilidad proviene del paquete de nodos personalizados de Bernini: ComfyUI-RH-Bernini. Trátalo como una herramienta de pre-escritura para estandarizar el lenguaje que funciona bien con el acondicionamiento de Bernini.
Ejecución#
El camino principal comienza cargando los UNets ALTO y BAJO de Bernini y adjuntando LightX2V LoRAs para cada etapa. BerniniConditioning (#34) fusiona tus codificaciones positivas y negativas, VAE, cuadros de video fuente e imágenes de referencia para construir el acondicionamiento específico de Bernini y un latente inicial alineado con tu resolución y conteo de cuadros. Un BasicScheduler (#18) crea el programa de denoising, luego SplitSigmas (#17) lo divide en rangos ALTO y BAJO. El muestreador ALTO SamplerCustom (#19) establece la estructura y la identidad bajo un ruido más fuerte, pasando su latente al muestreador BAJO SamplerCustom (#15) para detalles y pulido temporal. KSamplerSelect (#27) elige el algoritmo de muestreo, VAEDecode (#16) convierte el latente final en cuadros, y VHS_VideoCombine (#87) renderiza un MP4 que hereda la tasa de cuadros fuente. En paralelo, ImageConcanate (#97) y un segundo VHS_VideoCombine (#96) producen una comparación lado a lado para verificaciones rápidas de calidad. La E/S de video y el ensamblaje son proporcionados por la Suite de Ayuda de Video: ComfyUI-VideoHelperSuite.
Nodos clave en el flujo de trabajo de generación y edición de video multimodal Bernini en ComfyUI#
BerniniConditioning (#34) Construye el acondicionamiento nativo de Bernini combinando tus codificaciones de texto, VAE, video fuente e imágenes de referencia. También prepara el volumen latente inicial y maneja el tamaño espacial y temporal. Ajusta width y height para igualar tu resolución objetivo y usa length para controlar el número de cuadros generados. Si el sujeto de referencia es pequeño en la imagen, aumenta ref_max_size para que el modelo perciba mejor los detalles de identidad. Este nodo es parte del paquete personalizado de Bernini: ComfyUI-RH-Bernini.
LoraLoaderModelOnly (#11) Aplica el LoRA de LightX2V high_noise a la espina ALTA. Aumentar su strength_model incrementa la adhesión a la referencia en la etapa estructural, útil cuando la silueta o las características gruesas del sujeto no coinciden con el video fuente. Redúcelo si la edición se vuelve demasiado rígida o suprime el movimiento natural. Úsalo en conjunto con el LoRA de la etapa BAJA para equilibrar la fidelidad y la fluidez.
LoraLoaderModelOnly (#29) Aplica el LoRA de LightX2V low_noise a la espina BAJA. Este LoRA refina texturas como cabello, piel y vestimenta mientras mantiene el movimiento establecido por la etapa ALTA. Si los detalles de identidad se desvían entre cuadros, aumenta ligeramente la fortaleza; si las texturas se agudizan demasiado o parecen sobreajustadas, redúcela. Junto con el LoRA de la etapa ALTA forma un par complementario.
SplitSigmas (#17) Divide el programa de denoising en rangos ALTO y BAJO. Mover la división antes produce ediciones más suaves que mantienen más del video original, mientras que moverla después otorga más influencia a la etapa ALTA para reemplazos más fuertes. Ajusta la división cuando cambies textos o fortalezas de LoRA para que ambas etapas permanezcan equilibradas. Este control es especialmente útil para ediciones que preservan el movimiento con la cámara fija.
KSamplerSelect (#27) Selecciona el algoritmo de muestreo usado por ambas etapas de denoising. Algunos muestreadores favorecen la estabilidad y la suavidad temporal mientras que otros enfatizan el detalle o la velocidad. Si ves parpadeo, prueba un muestreador conocido por su consistencia; si necesitas más nitidez, prueba un algoritmo que inyecte más variación. Mantén la misma elección para ambas etapas para mantener un comportamiento predecible.
VHS_VideoCombine (#87) Codifica los cuadros decodificados en un MP4 final mientras hereda la tasa de cuadros reportada por VHS_VideoInfo para que la velocidad de reproducción coincida con el clip fuente. Usa controles de nombre de archivo para organizar las ejecuciones y habilita el guardado de metadatos si planeas auditar configuraciones. Una segunda instancia (#96) produce una renderización lado a lado para una comparación visual rápida. Proporcionado por ComfyUI-VideoHelperSuite.
Extras opcionales#
- Para tareas críticas de identidad, proporciona dos o tres imágenes de referencia de alta calidad que muestren cabello, iluminación y expresión consistentes. Usa la entrada por lotes para alimentarlas juntas.
- Mantén la relación de aspecto objetivo cercana al video fuente. Grandes desajustes pueden estirar caras y desestabilizar el movimiento.
- Si el fondo o la cámara se desplazan, fortalece el lenguaje en tu instrucción que bloquee la posición de la cámara y la escena, y refuerza con un texto negativo conciso.
- Usa la exportación lado a lado al ajustar fortalezas de LoRA o la división de sigma. Acorta el tiempo de iteración al hacer diferencias obvias.
- Para pruebas más rápidas, limita el número de cuadros que cargas, luego escala una vez que estés satisfecho con la coincidencia de identidad y calidad de movimiento.
Este flujo de trabajo de generación y edición de video multimodal Bernini está diseñado para ser editado de manera segura: comienza con los valores predeterminados, itera en la instrucción y las referencias, luego ajusta las fortalezas de LoRA y la división de sigma para tu sujeto y escena.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos profundamente a ByteDance por Bernini, RH-RunningHub por ComfyUI-RH-Bernini y Kosinkadink por ComfyUI-VideoHelperSuite por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- RunningHub/Bernini Multimodal Video Generation and Editing (ComfyUI Workflow)
- Docs / Release Notes: RunningHub workflow reference
- RunComfy/Cloud Save workflow
- Docs / Release Notes: RunComfy Cloud Save workflow
- ByteDance/Bernini-R
- GitHub: bytedance/Bernini
- Hugging Face: ByteDance/Bernini-R
- arXiv: arXiv:2605.22344
- Docs / Release Notes: ByteDance Bernini model source
- Kijai/WanVideo_comfy_fp8_scaled (Bernini assets)
- Hugging Face: Kijai/WanVideo_comfy_fp8_scaled
- Docs / Release Notes: Kijai Bernini ComfyUI fp8 model assets
- RH-RunningHub/ComfyUI-RH-Bernini
- GitHub: RH-RunningHub/ComfyUI-RH-Bernini
- Docs / Release Notes: RunComfy Bernini custom nodes
- Kosinkadink/ComfyUI-VideoHelperSuite
- GitHub: Kosinkadink/ComfyUI-VideoHelperSuite
- Docs / Release Notes: ComfyUI Video Helper Suite
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.

