
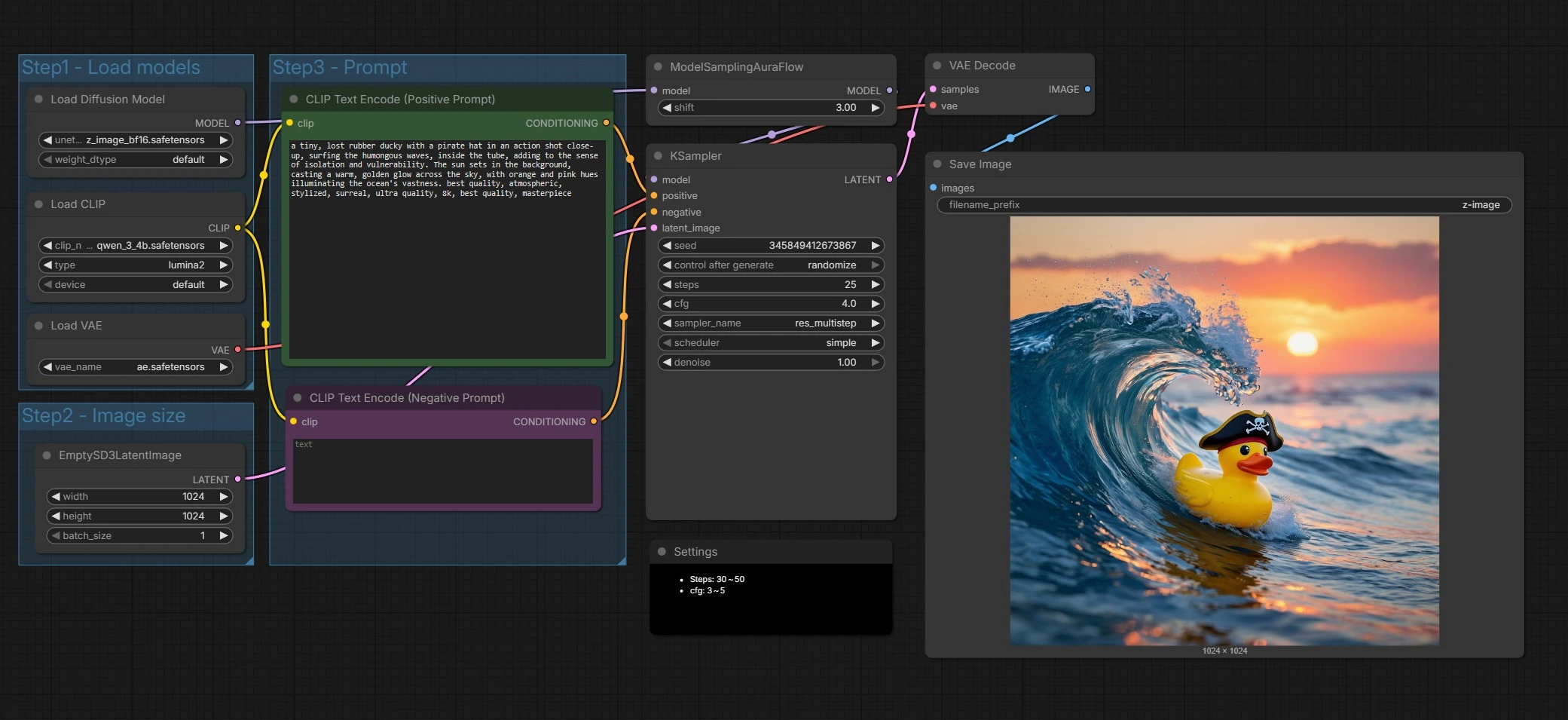
















Z-Image Text-zu-Bild-Workflow für ComfyUI#
Dieser ComfyUI-Workflow präsentiert Z-Image, einen Diffusionstransformer der nächsten Generation, der für schnelle, hochqualitative Bildgenerierung entwickelt wurde. Basierend auf einer skalierbaren Single-Stream-Architektur mit rund 6 Milliarden Parametern balanciert Z-Image Fotorealismus, starke Eingabeaufforderungstreue und zweisprachiges Textrendering.
Out of the box ist der Graph für Z-Image Base eingerichtet, um die Qualität zu maximieren und dabei auf gängigen GPUs effizient zu bleiben. Er funktioniert auch gut mit der Z-Image Turbo-Variante, wenn es auf Geschwindigkeit ankommt, und seine Struktur macht es einfach, ihn in Richtung Z-Image Edit für Bild-zu-Bild-Aufgaben zu erweitern. Wenn Sie einen zuverlässigen, minimalen Graphen möchten, der klare Eingabeaufforderungen in saubere Ergebnisse umwandelt, ist dieser Z-Image-Workflow ein solider Ausgangspunkt.
Wichtige Modelle im Comfyui Z-Image-Workflow#
- Z-Image Base Diffusionstransformer (bf16). Kern-Generator, der latente Bilder mit Z-Image’s Single-Stream-Topologie und Eingabeaufforderungskontrolle entrauscht. Model page • bf16 weights
- Qwen 3 4B Text-Encoder. Kodiert Eingabeaufforderungen für Z-Image mit starker zweisprachiger Abdeckung und klarer Tokenisierung für Textrendering. encoder weights
- Z-Image Autoencoder VAE. Komprimiert und rekonstruiert Bilder zwischen Pixel-Raum und dem Z-Image-Latent-Raum. VAE weights
So verwenden Sie den Comfyui Z-Image-Workflow#
Auf hoher Ebene lädt der Graph Z-Image-Komponenten, bereitet eine latente Leinwand vor, kodiert Ihre positiven und negativen Eingabeaufforderungen, führt einen für Z-Image abgestimmten Sampler aus, dann dekodiert und speichert das Ergebnis. Sie geben hauptsächlich die Eingabeaufforderung an und wählen die Ausgabengröße; der Rest ist für sinnvolle Voreinstellungen verdrahtet.
Schritt 1 - Modelle laden#
Diese Gruppe initialisiert den Z-Image UNet, den Qwen 3 4B Text-Encoder und den VAE, sodass alle Komponenten übereinstimmen. Der UNETLoader (#66) verweist standardmäßig auf Z-Image Base, was Treue und Bearbeitungsspielraum begünstigt. Der CLIPLoader (#62) bringt den auf Qwen basierenden Encoder, der mehrsprachige Eingabeaufforderungen und Texttokens gut handhabt. Der VAELoader (#63) setzt den Autoencoder, der später zum Dekodieren verwendet wird. Tauschen Sie hier Gewichte aus, wenn Sie Z-Image Turbo für schnellere Entwürfe ausprobieren möchten.
Schritt 2 - Bildgröße#
Diese Gruppe richtet die latente Leinwand über EmptySD3LatentImage (#68) ein. Wählen Sie die Breite und Höhe, die Sie generieren möchten, und beachten Sie das Seitenverhältnis für die Komposition. Z-Image funktioniert gut in gängigen kreativen Größen, daher wählen Sie Abmessungen, die zu Ihren Storyboards oder Ihrem Ausgabeformat passen. Größere Größen erhöhen Details und Rechenaufwand.
Schritt 3 - Eingabeaufforderung#
Hier schreiben Sie Ihre Geschichte. Der CLIP Text Encode (Positive Prompt) (#67) Knoten nimmt Ihre Szenenbeschreibung und Stilvorgaben für Z-Image auf. Der CLIP Text Encode (Negative Prompt) (#71) hilft, Artefakte oder unerwünschte Elemente zu vermeiden. Z-Image ist für zweisprachiges Textrendering abgestimmt, sodass Sie Textinhalte in mehreren Sprachen direkt in die Eingabeaufforderung einfügen können, wenn dies erforderlich ist. Halten Sie die Eingabeaufforderungen spezifisch und visuell für die konsistentesten Ergebnisse.
Beispiel und Entrauschen#
ModelSamplingAuraFlow (#70) wendet eine Sampling-Politik an, die mit Z-Image’s Single-Stream-Design übereinstimmt, dann treibt KSampler (#69) den Entrauschungsprozess an, um das Rauschen in ein Bild zu verwandeln, das Ihren Eingabeaufforderungen entspricht. Der Sampler kombiniert Ihre positive und negative Konditionierung mit der latenten Leinwand, um Struktur und Details iterativ zu verfeinern. Sie können hier Geschwindigkeit gegen Qualität eintauschen, indem Sie die Samplereinstellungen wie unten beschrieben anpassen. In dieser Phase zeigt sich wirklich die Eingabeaufforderungstreue und Textklarheit von Z-Image.
Dekodieren und Speichern#
VAEDecode (#65) wandelt das finale Latent in ein RGB-Bild um. SaveImage (#9) schreibt Dateien mit dem im Knoten gesetzten Präfix, sodass Ihre Z-Image-Ausgaben leicht zu finden und zu organisieren sind. Dies vervollständigt einen vollständigen Durchlauf von Eingabeaufforderung zu Pixeln.
Wichtige Knoten im Comfyui Z-Image-Workflow#
UNETLoader (#66)#
Lädt das Z-Image-Rückgrat, das das eigentliche Entrauschen durchführt. Wechseln Sie hier zu einer anderen Z-Image-Variante, wenn Sie Geschwindigkeit oder Bearbeitungsanwendungsfälle erkunden. Wenn Sie Varianten ändern, halten Sie den Encoder und VAE kompatibel, um Farb- oder Kontrastverschiebungen zu vermeiden.
CLIP Text Encode (Positive Prompt) (#67)#
Kodiert die Hauptbeschreibung für Z-Image. Schreiben Sie prägnante, visuelle Phrasen, die Subjekt, Beleuchtung, Kamera, Stimmung und jeden auf dem Bild befindlichen Text spezifizieren. Für Textrendering setzen Sie die gewünschten Worte in Anführungszeichen und halten Sie sie kurz für beste Lesbarkeit.
CLIP Text Encode (Negative Prompt) (#71)#
Definiert, was vermieden werden soll, damit sich Z-Image auf die richtigen Details konzentrieren kann. Verwenden Sie es, um Unschärfe, zusätzliche Gliedmaßen, unordentliche Typografie oder stilfremde Elemente zu unterdrücken. Halten Sie es kurz und themenbezogen, damit es die Komposition nicht übermäßig einschränkt.
EmptySD3LatentImage (#68)#
Erstellt die latente Leinwand, auf der Z-Image malen wird. Wählen Sie Abmessungen, die zur endgültigen Nutzung passen, und halten Sie sie in Vielfachen von 64 px für effiziente Speichernutzung. Breitere oder höhere Leinwände beeinflussen Komposition und Perspektive, passen Sie daher die Eingabeaufforderungen entsprechend an.
ModelSamplingAuraFlow (#70)#
Wählt ein Sampler-Preset aus, das mit Z-Image’s Training und latentem Raum übereinstimmt. Sie müssen dies selten ändern, es sei denn, Sie testen alternative Sampler. Lassen Sie es, wie bereitgestellt, für stabile, artefaktfreie Ergebnisse.
KSampler (#69)#
Steuert den Qualitäts-Geschwindigkeits-Kompromiss für Z-Image. Erhöhen Sie steps für mehr Detail und Stabilität, verringern Sie für schnellere Entwürfe. Halten Sie cfg moderat, um Eingabeaufforderungstreue mit natürlichen Texturen auszubalancieren; typische Werte in diesem Graphen sind steps: 30 bis 50 und cfg: 3 bis 5. Setzen Sie einen festen seed für Reproduzierbarkeit oder randomisieren Sie ihn, um Variationen zu erkunden.
VAEDecode (#65)#
Transformiert das finale Latent von Z-Image in ein RGB-Bild. Wenn Sie jemals den VAE ändern, halten Sie ihn an die Modelfamilie angepasst, um Farbgenauigkeit und Schärfe zu bewahren.
SaveImage (#9)#
Schreibt das Ergebnis mit einem klaren Dateinamenpräfix, sodass Z-Image-Ausgaben leicht zu katalogisieren sind. Passen Sie das Präfix an, um Experimente, Modellvarianten oder Seitenverhältnisse zu trennen.
Optionale Extras#
- Verwenden Sie Z-Image Turbo für schnelle Ideenfindung, dann wechseln Sie zurück zu Z-Image Base und erhöhen Sie die Schritte für endgültige Renderings.
- Für zweisprachige Eingabeaufforderungen und auf dem Bild befindlichen Text halten Sie die Formulierungen kurz und mit hohem Kontrast in der Eingabeaufforderung, um Z-Image beim Rendern klarer Typografie zu unterstützen.
- Sperren Sie den Seed, wenn Sie kleine Eingabeaufforderungsänderungen vergleichen, damit die Unterschiede Ihre Änderungen widerspiegeln und nicht neues Rauschen.
- Wenn Sie Übersättigung oder Halos sehen, senken Sie
cfgleicht oder stärken Sie die negative Eingabeaufforderung, um das Gleichgewicht wiederherzustellen.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Comfy-Org für das Z-Image Day-0 ComfyUI Workflow-Template für ihre Beiträge und Wartung. Für autoritative Details konsultieren Sie bitte die Originaldokumentation und die unten verlinkten Repositorys.
Ressourcen#
- Comfy-Org/Z-Image Day-0 Unterstützung in ComfyUI
- GitHub: Comfy-Org/workflow_templates
- Docs / Release Notes: Source
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.

