
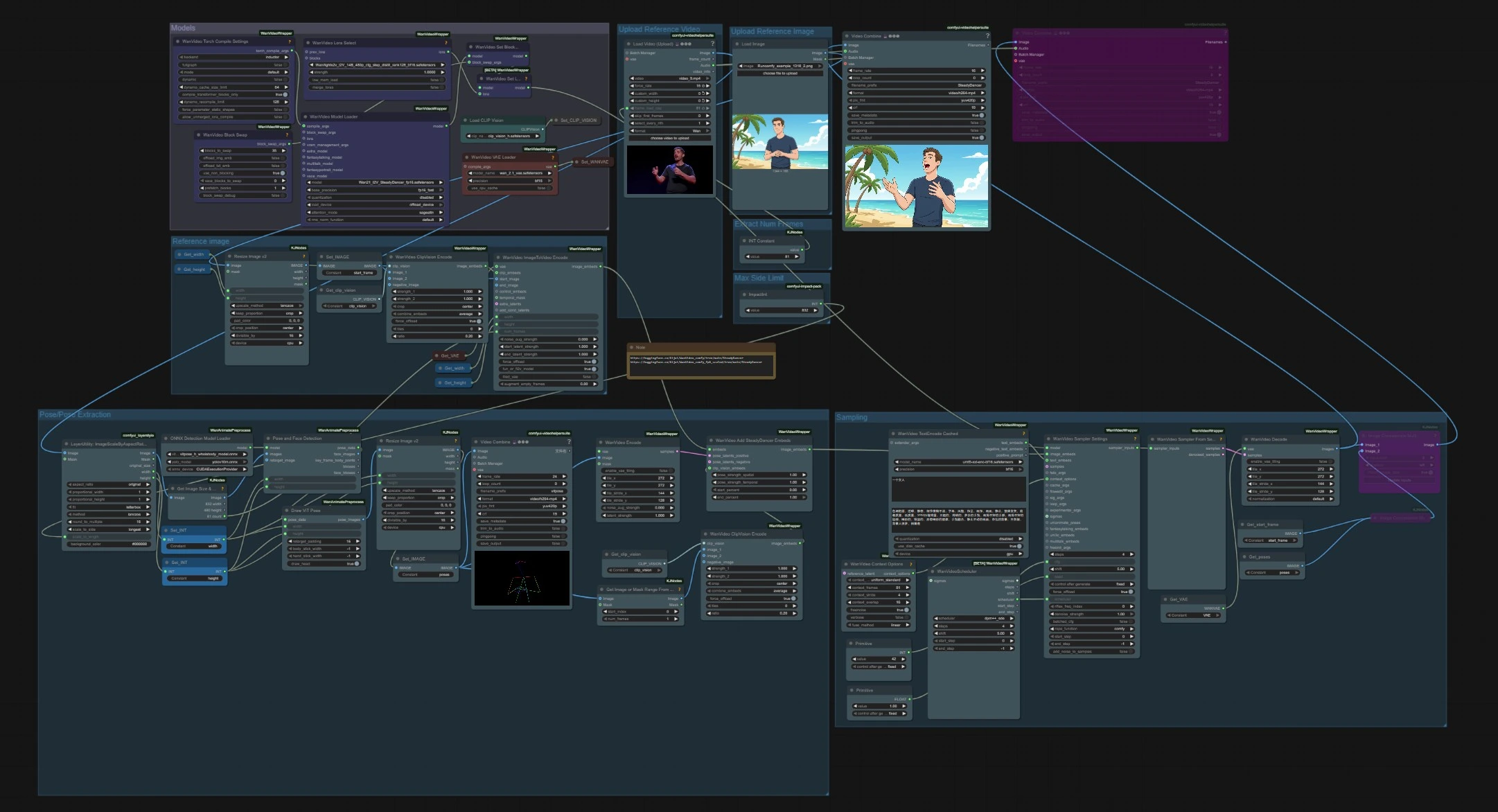
SteadyDancer Bild-zu-Video Posen-Animations-Workflow#
Dieser ComfyUI-Workflow verwandelt ein einzelnes Referenzbild in ein kohärentes Video, das durch die Bewegung einer separaten Posenquelle gesteuert wird. Er basiert auf dem Bild-zu-Video-Paradigma von SteadyDancer, sodass der allererste Frame die Identität und das Erscheinungsbild Ihres Eingabebildes bewahrt, während die restliche Sequenz der Zielbewegung folgt. Der Graph vereint Pose und Erscheinungsbild durch SteadyDancer-spezifische Einbettungen und eine Posen-Pipeline, die eine glatte, realistische Ganzkörperbewegung mit starker zeitlicher Kohärenz erzeugt.
SteadyDancer ist ideal für menschliche Animationen, Tanzgenerierung und das Erwecken von Charakteren oder Porträts zum Leben. Geben Sie ein Standbild plus einen Bewegungsclip ein, und die ComfyUI-Pipeline übernimmt die Posenextraktion, Einbettung, Abtastung und Dekodierung, um ein teilbares Video zu liefern.
Schlüsselmodelle im ComfyUI SteadyDancer-Workflow#
- SteadyDancer. Forschungsmodell für identitätsbewahrende Bild-zu-Video mit einem Condition-Reconciliation Mechanism und Synergistic Pose Modulation. Hier als Kernmethode für I2V verwendet. GitHub
- Wan 2.1 I2V SteadyDancer Gewichte. Checkpoints, die für ComfyUI portiert wurden und SteadyDancer auf dem Wan 2.1 Stack implementieren. Hugging Face: Kijai/WanVideo_comfy (SteadyDancer) und Kijai/WanVideo_comfy_fp8_scaled (SteadyDancer)
- Wan 2.1 VAE. Video VAE, das für latentes Kodieren und Dekodieren innerhalb der Pipeline verwendet wird. Inklusive mit dem WanVideo-Port auf Hugging Face oben.
- OpenCLIP CLIP ViT-H/14. Vision-Encoder, der robuste Erscheinungs-Einbettungen aus dem Referenzbild extrahiert. Hugging Face
- ViTPose-H WholeBody (ONNX). Hochwertiges Keypoint-Modell für Körper, Hände und Gesicht, das zur Ableitung der treibenden Posen-Sequenz verwendet wird. GitHub
- YOLOv10 (ONNX). Detektor, der die Personenlokalisierung vor der Posenabschätzung in diversen Videos verbessert. GitHub
- umT5-XXL Encoder. Optionaler Text-Encoder für Stil- oder Szenenführung neben dem Referenzbild. Hugging Face
Wie man den ComfyUI SteadyDancer-Workflow benutzt#
Der Workflow hat zwei unabhängige Eingaben, die sich bei der Abtastung treffen: ein Referenzbild für die Identität und ein Treibervideo für die Bewegung. Modelle werden einmal zu Beginn geladen, die Pose wird aus dem Treiberclip extrahiert, und SteadyDancer-Einbettungen vermischen Pose und Erscheinungsbild vor der Generierung und Dekodierung.
Modelle#
Diese Gruppe lädt die Kerngewichte, die im gesamten Graphen verwendet werden. WanVideoModelLoader (#22) wählt den Wan 2.1 I2V SteadyDancer-Checkpoint aus und verwaltet Aufmerksamkeit und Präzisionseinstellungen. WanVideoVAELoader (#38) stellt das Video VAE bereit, und CLIPVisionLoader (#59) bereitet das CLIP ViT-H Vision-Backbone vor. Ein LoRA-Auswahlknoten und BlockSwap-Optionen sind für fortgeschrittene Benutzer vorhanden, die das Speicherverhalten ändern oder zusätzliche Gewichte anhängen möchten.
Referenzvideo hochladen#
Importieren Sie die Bewegungsquelle mit VHS_LoadVideo (#75). Der Knoten liest Frames und Audio, sodass Sie eine Zielbildrate festlegen oder die Anzahl der Frames begrenzen können. Der Clip kann jede menschliche Bewegung wie einen Tanz oder Sportbewegung sein. Der Videostream fließt dann zur Seitenverhältnis-Skalierung und Posenextraktion.
Anzahl der Frames extrahieren#
Eine einfache Konstante steuert, wie viele Frames aus dem Treibervideo geladen werden. Dies begrenzt sowohl die Posenextraktion als auch die Länge des generierten SteadyDancer-Ausgangs. Erhöhen Sie es für längere Sequenzen, oder verringern Sie es, um schneller iterieren zu können.
Maximale Seitenbegrenzung#
LayerUtility: ImageScaleByAspectRatio V2 (#146) skaliert Frames unter Wahrung des Seitenverhältnisses, sodass sie in die Schrittweite und das Speicherbudget des Modells passen. Setzen Sie eine lange Seitenbegrenzung, die für Ihre GPU und das gewünschte Detailniveau angemessen ist. Die skalierten Frames werden von den nachgelagerten Erkennungsknoten verwendet und als Referenz für die Ausgabengröße verwendet.
Pose/Posenextraktion#
Personenerkennung und Posenabschätzung laufen auf den skalierten Frames. PoseAndFaceDetection (#89) verwendet YOLOv10 und ViTPose-H, um Menschen und Schlüsselpunkte robust zu finden. DrawViTPose (#88) rendert eine saubere Strichmännchen-Darstellung der Bewegung, und ImageResizeKJv2 (#77) passt die resultierenden Posenbilder an die Generationsleinwand an. WanVideoEncode (#72) konvertiert die Posenbilder in Latente, sodass SteadyDancer die Bewegung modulieren kann, ohne das Erscheinungssignal zu stören.
Referenzbild hochladen#
Laden Sie das Identitätsbild, das Sie mit SteadyDancer animieren möchten. Das Bild sollte den zu bewegenden Gegenstand klar zeigen. Verwenden Sie eine Pose und Kamerawinkel, die dem Treibervideo grob entsprechen, um die treueste Übertragung zu erreichen. Das Bild wird an die Referenzbildgruppe zur Einbettung weitergeleitet.
Referenzbild#
Das Standbild wird mit ImageResizeKJv2 (#68) skaliert und als Startbild über Set_IMAGE (#96) registriert. WanVideoClipVisionEncode (#65) extrahiert CLIP ViT-H Einbettungen, die Identität, Kleidung und grobes Layout bewahren. WanVideoImageToVideoEncode (#63) packt Breite, Höhe und Frameanzahl mit dem Startbild, um SteadyDancers I2V-Konditionierung vorzubereiten.
Abtastung#
Hier treffen Erscheinungsbild und Bewegung aufeinander, um das Video zu generieren. WanVideoAddSteadyDancerEmbeds (#71) erhält Bildkonditionierung von WanVideoImageToVideoEncode und ergänzt sie mit Posenlatenten plus einem CLIP-Vision-Referenz, wodurch SteadyDancers Konditionsabgleich ermöglicht wird. Kontextfenster und Überlappung werden in WanVideoContextOptions (#87) für zeitliche Konsistenz gesetzt. Optional fügt WanVideoTextEncodeCached (#92) umT5-Textführung für Stilhinweise hinzu. WanVideoSamplerSettings (#119) und WanVideoSamplerFromSettings (#129) führen die eigentlichen Denoising-Schritte auf dem Wan 2.1-Modell aus, nach denen WanVideoDecode (#28) Latente zurück in RGB-Frames konvertiert. Endvideos werden mit VHS_VideoCombine (#141, #83) gespeichert.
Schlüsselnoten im ComfyUI SteadyDancer-Workflow#
WanVideoAddSteadyDancerEmbeds (#71)#
Dieser Knoten ist das Herzstück des SteadyDancer-Graphen. Er fusioniert die Bildkonditionierung mit Posenlatenten und CLIP-Vision-Hinweisen, sodass der erste Frame die Identität sperrt, während sich die Bewegung natürlich entfaltet. Passen Sie pose_strength_spatial an, um zu steuern, wie eng Gliedmaßen dem erkannten Skelett folgen, und pose_strength_temporal, um die Bewegungsglätte über die Zeit zu regulieren. Verwenden Sie start_percent und end_percent, um zu begrenzen, wo die Posenkontrolle innerhalb der Sequenz angewendet wird, für natürlichere Intros und Outros.
PoseAndFaceDetection (#89)#
Führt YOLOv10-Erkennung und ViTPose-H Schlüsselpunktabschätzung auf dem Treibervideo durch. Wenn Posen kleine Gliedmaßen oder Gesichter verfehlen, erhöhen Sie die Eingabeauflösung stromaufwärts oder wählen Sie Aufnahmen mit weniger Verdeckungen und sauberer Beleuchtung. Wenn mehrere Personen vorhanden sind, halten Sie das Zielobjekt am größten im Bild, damit der Detektor und der Posenkopf stabil bleiben.
VHS_LoadVideo (#75)#
Steuert, welchen Teil der Bewegungsquelle Sie verwenden. Erhöhen Sie die Framebegrenzung für längere Ausgaben oder senken Sie sie, um schnell zu prototypen. Der force_rate-Eingang richtet das Posenabstand mit der Generationsrate aus und kann helfen, Stottern zu reduzieren, wenn die ursprüngliche Bildfrequenz des Clips ungewöhnlich ist.
LayerUtility: ImageScaleByAspectRatio V2 (#146)#
Hält Frames innerhalb einer gewählten langen Seitenbegrenzung, während das Seitenverhältnis beibehalten und auf eine teilbare Größe gebündelt wird. Passen Sie die Skala hier an die Generationsleinwand an, sodass SteadyDancer nicht aggressiv hochskalieren oder zuschneiden muss. Wenn Sie weiche Ergebnisse oder Kantenartefakte sehen, bringen Sie die lange Seite näher an die native Trainingsskala des Modells für eine sauberere Dekodierung.
WanVideoSamplerSettings (#119)#
Definiert den Denoising-Plan für den Wan 2.1 Sampler. Der scheduler und steps setzen die Gesamtqualität gegenüber der Geschwindigkeit, während cfg die Einhaltung des Bildes plus Prompt gegen Vielfalt ausbalanciert. seed sperrt die Reproduzierbarkeit, und denoise_strength kann gesenkt werden, wenn Sie noch näher am Erscheinungsbild des Referenzbildes bleiben möchten.
WanVideoModelLoader (#22)#
Lädt den Wan 2.1 I2V SteadyDancer-Checkpoint und verwaltet Präzision, Aufmerksamkeitsimplementierung und Geräteplatzierung. Lassen Sie diese wie konfiguriert für Stabilität. Fortgeschrittene Benutzer können eine I2V LoRA anhängen, um das Bewegungsverhalten zu ändern oder die Rechenkosten bei Experimenten zu senken.
Optionale Extras#
- Wählen Sie ein klares, gut beleuchtetes Referenzbild. Frontale oder leicht geneigte Ansichten, die der Kamera des Treibervideos ähneln, lassen SteadyDancer die Identität zuverlässiger bewahren.
- Bevorzugen Sie Bewegungsclips mit einem einzigen prominenten Subjekt und minimaler Verdeckung. Belebte Hintergründe oder schnelle Schnitte reduzieren die Posenstabilität.
- Wenn Hände und Füße zittern, erhöhen Sie leicht die zeitliche Posenstärke in
WanVideoAddSteadyDancerEmbedsoder erhöhen Sie die Video-FPS, um die Posen zu verdichten. - Für längere Szenen, verarbeiten Sie in Segmenten mit überlappendem Kontext und nähen Sie die Ausgaben zusammen. Dies hält den Speicherverbrauch vernünftig und bewahrt die zeitliche Kontinuität.
- Verwenden Sie die eingebauten Vorschau-Mosaiken, um die generierten Frames mit dem Startbild und der Posenfolge zu vergleichen, während Sie die Einstellungen optimieren.
Dieser SteadyDancer-Workflow bietet Ihnen einen praktischen, durchgängigen Weg von einem Standbild zu einem treuen, posengesteuerten Video, bei dem die Identität vom allerersten Frame an bewahrt bleibt.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken MCG-NJU für SteadyDancer für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- MCG-NJU/SteadyDancer
- GitHub: MCG-NJU/SteadyDancer
- Hugging Face: MCG-NJU/SteadyDancer-14B
- arXiv: arXiv:2511.19320
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Betreuer.
