




Stability AI hat Stable Diffusion 3.5 (SD3.5) vorgestellt, ein Open-Source-Multimodales generatives KI-Modell, das mehrere Varianten umfasst, wie Stable Diffusion 3.5 (SD3.5) Large, Stable Diffusion 3.5 (SD3.5) Large Turbo und Stable Diffusion 3.5 (SD3.5) Medium. Diese Modelle sind hochgradig anpassbar und können auf Consumer-Hardware ausgeführt werden. Die SD3.5 Large und Large Turbo Modelle sind sofort verfügbar, während die Medium-Version am 29. Oktober 2024 veröffentlicht wird.
1. Wie Stable Diffusion 3.5 (SD3.5) funktioniert#
Auf technischer Ebene nimmt Stable Diffusion 3.5 (SD3.5) eine Textvorgabe als Eingabe, kodiert sie in einen latenten Raum mithilfe von transformatorbasierten Textkodierern und dekodiert diese latente Darstellung dann in ein Ausgabebild mithilfe eines diffusionsbasierten Dekoders. Die Transformator-Textkodierer, wie das CLIP (Contrastive Language-Image Pre-training) Modell, ordnen die Eingabeaufforderung einer semantisch bedeutungsvollen komprimierten Darstellung im latenten Raum zu. Dieser latente Code wird dann iterativ über mehrere Zeitschritte vom Diffusionsdekoder entrauscht, um das endgültige Bildausgabe zu erzeugen. Der Diffusionsprozess beinhaltet das allmähliche Entfernen von Rauschen aus einer anfänglich verrauschten latenten Darstellung, die auf der Texteingabe basiert, bis ein klares Bild entsteht.
Die verschiedenen Modellgrößen in Stable Diffusion 3.5 (SD3.5) (Large, Medium) beziehen sich auf die Anzahl der trainierbaren Parameter - 8 Milliarden für das Large-Modell und 2,5 Milliarden für das Medium-Modell. Mehr Parameter ermöglichen es dem Modell in der Regel, mehr Wissen und Nuancen aus seinen Trainingsdaten zu erfassen. Die Turbo-Modelle sind destillierte Versionen, die einige Qualität für viel schnellere Inferenzgeschwindigkeiten opfern. Die Destillation beinhaltet das Training eines kleineren "Student"-Modells, um die Ausgaben eines größeren "Lehrer"-Modells nachzuahmen, mit dem Ziel, die meisten Fähigkeiten in einer effizienteren Architektur beizubehalten.
2. Stärken der Stable Diffusion 3.5 (SD3.5) Modelle#
2.1. Anpassbarkeit#
Die Stable Diffusion 3.5 (SD3.5) Modelle sind so konzipiert, dass sie leicht feinabgestimmt und für spezifische Anwendungen weiterentwickelt werden können. Query-Key-Normalisierung wurde in die Transformatorblöcke integriert, um das Training zu stabilisieren und die Weiterentwicklung zu vereinfachen. Diese Technik normalisiert die Aufmerksamkeitswerte in den Transformationsschichten, was das Modell robuster und leichter an neue Datensätze anpassbar macht.
2.2. Vielfalt der Ausgaben#
Stable Diffusion 3.5 (SD3.5) zielt darauf ab, Bilder zu erzeugen, die die Vielfalt der Welt repräsentieren, ohne dass umfangreiche Vorgaben erforderlich sind. Es kann Menschen mit unterschiedlichen Hauttönen, Merkmalen und Ästhetiken darstellen. Dies ist wahrscheinlich darauf zurückzuführen, dass das Modell auf einem großen und vielfältigen Datensatz von Bildern aus dem gesamten Internet trainiert wurde.
2.3. Breite Palette von Stilen#
Die Stable Diffusion 3.5 (SD3.5) Modelle sind in der Lage, Bilder in einer Vielzahl von Stilen zu erzeugen, darunter 3D-Renderings, Fotorealismus, Gemälde, Strichzeichnungen, Anime und mehr. Diese Vielseitigkeit macht sie für viele Anwendungsfälle geeignet. Die Stilvielfalt ergibt sich aus der Fähigkeit des Diffusionsmodells, viele verschiedene visuelle Muster und Ästhetiken in seinem latenten Raum zu erfassen.
2.4. Starke Einhaltung der Vorgaben#
Insbesondere für das Stable Diffusion 3.5 (SD3.5) Large-Modell zeichnet sich SD3.5 bei der Generierung von Bildern aus, die mit der semantischen Bedeutung der Eingabetextvorgaben übereinstimmen. Es schneidet im Vergleich zu anderen Modellen bei Metriken zur Übereinstimmung der Vorgaben hoch ab. Diese Fähigkeit, Text präzise in Bilder zu übersetzen, wird durch die Sprachverständnisfähigkeiten des Transformator-Textkodierers ermöglicht.
3. Einschränkungen und Nachteile der Stable Diffusion 3.5 (SD3.5) Modelle#
3.1. Schwierigkeiten mit Anatomie und Objektinteraktionen#
Wie die meisten Text-zu-Bild-Modelle hat auch Stable Diffusion 3.5 (SD3.5) immer noch Schwierigkeiten, realistische menschliche Anatomie darzustellen, insbesondere Hände, Füße und Gesichter in komplexen Posen. Interaktionen zwischen Objekten und Händen sind oft verzerrt. Dies liegt wahrscheinlich an der Herausforderung, alle Nuancen der 3D-Raumbeziehungen und Physik allein aus 2D-Bildern zu erlernen.
3.2. Begrenzte Auflösung#
Das Stable Diffusion 3.5 (SD3.5) Large-Modell ist ideal für 1-Megapixel-Bilder (1024x1024), während das Medium-Modell bei etwa 2 Megapixeln endet. Die Erzeugung kohärenter Bilder bei höheren Auflösungen ist für SD3.5 eine Herausforderung. Diese Einschränkung ergibt sich aus den Rechen- und Speicherbeschränkungen der Diffusionsarchitektur.
3.3. Gelegentliche Störungen und Halluzinationen#
Aufgrund der breiten Vielfalt an Ausgaben, die die Stable Diffusion 3.5 (SD3.5) Modelle aus derselben Vorgabe mit unterschiedlichen Zufallssamen zulassen, kann es zu Unvorhersehbarkeit kommen. Vorgaben ohne Spezifität können zu fehlerhaften oder unerwarteten Elementen führen. Dies ist eine inhärente Eigenschaft des Diffusionsabtastprozesses, der Zufälligkeit beinhaltet.
3.4. Erreicht nicht den absoluten Spitzenstand#
Laut einigen frühen Tests erreicht Stable Diffusion 3.5 (SD3.5) in Bezug auf Bildqualität und Kohärenz derzeit nicht die Leistung von hochmodernen Text-zu-Bild-Modellen wie Midjourney. Und frühe Vergleiche zwischen Stable Diffusion 3.5 (SD3.5) und FLUX.1 zeigen, dass jedes Modell in verschiedenen Bereichen glänzt. Während FLUX.1 scheinbar einen Vorteil bei der Erstellung fotorealistischer Bilder hat, hat SD3.5 Large eine größere Fähigkeit, Anime-Stil-Kunstwerke zu erzeugen, ohne dass zusätzliche Feinabstimmungen oder Modifikationen erforderlich sind.
4. Stable Diffusion 3.5 in ComfyUI#
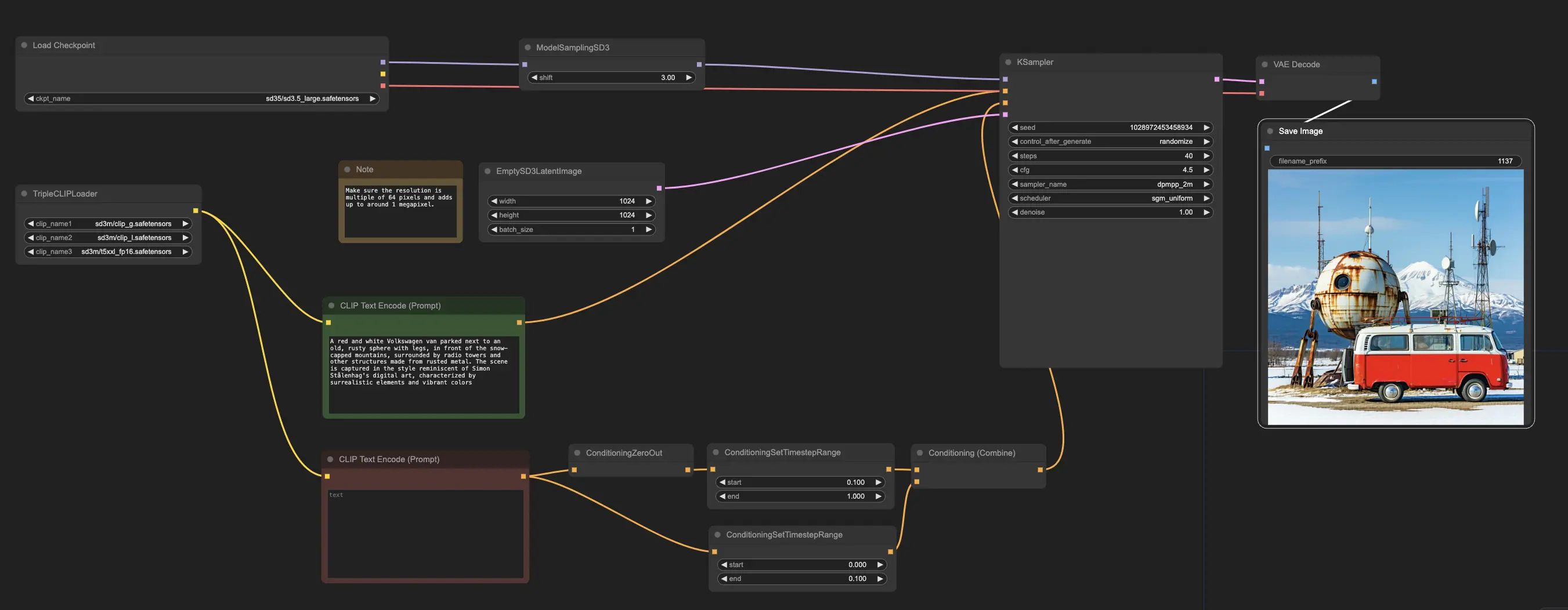
Bei RunComfy haben wir es Ihnen leicht gemacht, die Stable Diffusion 3.5 (SD3.5) Modelle zu nutzen, indem wir sie für Ihre Bequemlichkeit vorinstalliert haben. Sie können direkt loslegen und Inferenzläufe mit dem Beispiel-Workflow durchführen
Der Beispiel-Workflow beginnt mit dem CheckpointLoaderSimple-Knoten, der das vortrainierte Stable Diffusion 3.5 Large-Modell lädt. Und um Ihre Textvorgaben in ein für das Modell verständliches Format zu übersetzen, wird der TripleCLIPLoader-Knoten verwendet, um die entsprechenden Kodierer zu laden. Diese Kodierer sind entscheidend, um den Bilderzeugungsprozess basierend auf dem von Ihnen bereitgestellten Text zu steuern.
Der EmptySD3LatentImage-Knoten erstellt dann eine leere Leinwand mit den angegebenen Abmessungen, typischerweise 1024x1024 Pixel, die als Ausgangspunkt für das Modell zur Bilderzeugung dient. Die CLIPTextEncode-Knoten verarbeiten die von Ihnen bereitgestellten Textvorgaben, indem sie die geladenen Kodierer verwenden, um einen Satz von Anweisungen für das Modell zu erstellen.
Bevor diese Anweisungen an das Modell gesendet werden, durchlaufen sie eine weitere Verfeinerung durch die ConditioningCombine-, ConditioningZeroOut- und ConditioningSetTimestepRange-Knoten. Diese Knoten entfernen den Einfluss negativer Vorgaben, geben an, wann die Vorgaben während des Erzeugungsprozesses angewendet werden sollen, und kombinieren die Anweisungen zu einem einzigen, kohärenten Satz.
Schließlich können Sie den Bilderzeugungsprozess mit dem ModelSamplingSD3-Knoten feinabstimmen, der es Ihnen ermöglicht, verschiedene Einstellungen wie den Abtastmodus, die Anzahl der Schritte und die Modellausgabeskala anzupassen. Schließlich gibt Ihnen der KSampler-Knoten die Kontrolle über die Anzahl der Schritte, die Stärke des Einflusses der Anweisungen (CFG-Skala) und den spezifischen Algorithmus, der für die Erzeugung verwendet wird, sodass Sie die gewünschten Ergebnisse erzielen können.