
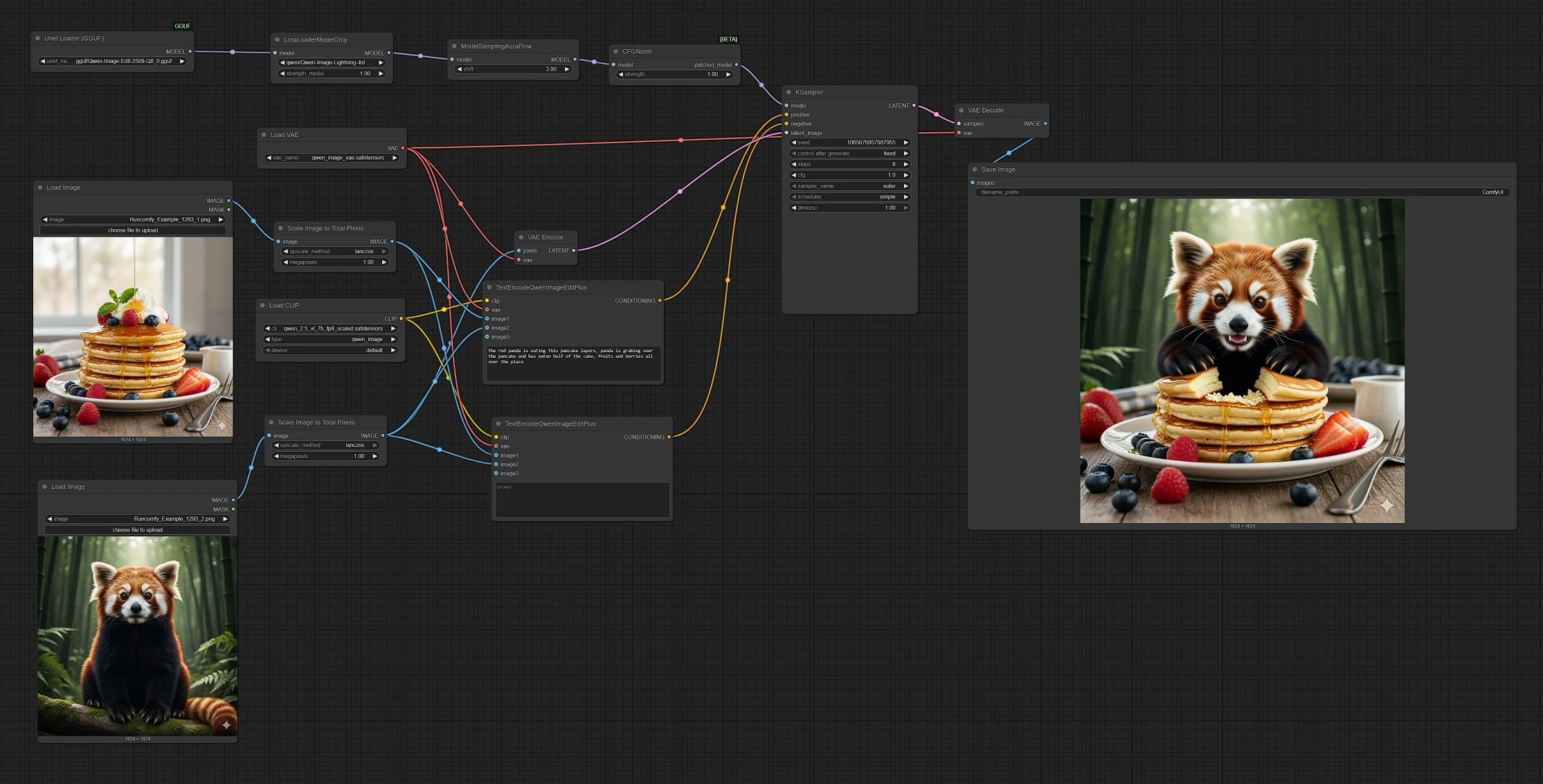






Qwen Image Edit 2509: mehrbildige, promptgesteuerte Bearbeitung und Mischung für ComfyUI#
Qwen Image Edit 2509 ist ein mehrbildiger Bearbeitungs-Workflow für ComfyUI, der 2–3 Eingabebilder unter einem einzigen Prompt kombiniert, um präzise Bearbeitungen und nahtlose Mischungen zu erstellen. Es ist für Schöpfer gedacht, die Objekte zusammensetzen, Szenen umgestalten, Elemente ersetzen oder Referenzen zusammenführen möchten, während die Kontrolle intuitiv und vorhersehbar bleibt.
Dieser ComfyUI-Graph kombiniert das Qwen-Bildmodell mit einem bearbeitungsbewussten Text-Encoder, sodass Sie die Ergebnisse mit natürlicher Sprache und einem oder mehreren visuellen Referenzen steuern können. Out of the box verarbeitet Qwen Image Edit 2509 Stilübertragungen, Objekteinsätze und Szenen-Remixe und erzeugt kohärente Ergebnisse, selbst wenn die Quellen im Aussehen oder in der Qualität variieren.
Schlüsselmodelle im Comfyui Qwen Image Edit 2509 Workflow#
- Qwen Image Edit 2509 (Diffusionsmodell & GGUF, Q8_0). Der primäre Bildbearbeitungs-Checkpoint, der in quantisierter Form geladen wird, um VRAM zu reduzieren und gleichzeitig das Bearbeitungsverhalten beizubehalten. Es bietet das Diffusions-Backbone, das Text und Referenzbilder während des Samplings interpretiert.
- Qwen Image VAE. Ein dedizierter VAE, der auf Qwen Image zugeschnitten ist und die Basisleinwand in den latenten Raum kodiert und die endgültigen Ergebnisse zurück in Pixel dekodiert. Asset-Quelle: Comfy-Org/Qwen-Image_ComfyUI.
- Qwen 2.5 VL 7B Text-Encoder (FP8 skaliert). Ein Vision-Language-Text-Encoder, der für ComfyUI verpackt ist und Ihren Prompt plus Referenzbilder in Bearbeitungsbedingungen umwandelt. Asset-Quelle: Comfy-Org/Qwen-Image_ComfyUI.
- Qwen-Image-Lightning-4steps-V1.0 LoRA. Ein optionales LoRA, das das Modell auf schnelle, wirkungsvolle Aktualisierungen ausrichtet, nützlich für schnelle Iterationen oder niedrige Schrittzahlen. Modellseite: lightx2v/Qwen-Image-Lightning.
Verwendung des Comfyui Qwen Image Edit 2509 Workflows#
Dieser Workflow folgt einem klaren Pfad von Eingaben bis zum Ergebnis: Sie laden 2–3 Bilder, schreiben einen Prompt, der Graph kodiert sowohl Text als auch Referenzen, das Sampling läuft über eine latente Basis, und das Ergebnis wird dekodiert und gespeichert.
Stufe 1 — Laden und Größe Ihrer Quellen
- Verwenden Sie
LoadImage(#103) für Bild 1 undLoadImage(#109) für Bild 2. Bild 2 dient als Basisleinwand, die bearbeitet wird. - Jedes Bild durchläuft
ImageScaleToTotalPixels(#93 und #108), sodass beide Referenzen ein konsistentes Pixelbudget teilen. Dies stabilisiert Komposition und Stilübertragung. - Wenn Sie eine dritte Referenz wünschen, schließen Sie ein weiteres
LoadImagean denimage3-Eingang an den Kodierungs-Knoten an. Qwen Image Edit 2509 akzeptiert bis zu drei Bilder für reichhaltigere Anleitungen.
Stufe 2 — Schreiben Sie den Prompt und setzen Sie die Absicht
- Der positive Encoder
TextEncodeQwenImageEditPlus(#104) kombiniert Ihren Text-Prompt mit Bild 1 und Bild 2, um das Ergebnis zu beschreiben, das Sie möchten. Verwenden Sie natürliche Sprache, um Mischungen, Ersetzungen oder Stilhinweise anzufordern. - Der negative Encoder
TextEncodeQwenImageEditPlus(#106) lässt Sie unerwünschte Details vermeiden. Lassen Sie ihn leer, um neutral zu bleiben, oder fügen Sie Phrasen hinzu, die Artefakte oder Stile unterdrücken, die Sie nicht möchten. - Beide Encoder verwenden den Qwen-Text-Encoder und VAE, sodass das Modell Ihre Referenzen als Teil der Anweisung „sieht“.
Stufe 3 — Bereiten Sie das Modell vor
UnetLoaderGGUF(#102) lädt das Qwen Image Edit 2509-Backbone im GGUF-Format für effiziente Inferenz.LoraLoaderModelOnly(#89) wendet das Qwen-Image-Lightning LoRA an. Erhöhen Sie seinen Einfluss für kräftigere Bearbeitungen oder reduzieren Sie ihn für konservativere Aktualisierungen.- Das Modell wird dann für das Sampling mit einer Konfiguration vorbereitet, die auf Bearbeitungsstabilität abgestimmt ist.
Stufe 4 — Geführte Generierung
- Die Basisleinwand (Bild 2) wird von
VAEEncode(#88) kodiert undKSampler(#3) als startender Latent bereitgestellt. Dies macht den Lauf bild-zu-bild statt rein text-zu-bild. KSampler(#3) fusioniert die positiven und negativen Bedingungen mit der latenten Leinwand, um das bearbeitete Ergebnis zu erzeugen. Sperren Sie den Seed für Reproduzierbarkeit oder variieren Sie ihn, um Alternativen zu erkunden.- Leitlinien und Sampling-Entscheidungen balancieren die Treue zu Ihren Quellen mit der Einhaltung des Prompts und geben Qwen Image Edit 2509 seine Mischung aus Präzision und Flexibilität.
Stufe 5 — Dekodieren und Speichern
VAEDecode(#8) konvertiert den endgültigen Latent in ein Bild, undSaveImage(#60) schreibt es in Ihren Ausgabefolder. Dateinamen spiegeln den Lauf wider, sodass Sie Versionen leicht vergleichen können.
Schlüssel-Knoten im Comfyui Qwen Image Edit 2509 Workflow#
TextEncodeQwenImageEditPlus (#104)#
Dieser Knoten erstellt die positive Bearbeitungsbedingung, indem er Ihren Prompt mit bis zu drei Referenzbildern über den Qwen-Encoder kombiniert. Verwenden Sie ihn, um anzugeben, was erscheinen soll, welchen Stil anzunehmen ist und wie stark Referenzen das Ergebnis beeinflussen sollen. Beginnen Sie mit einem klaren, ein-Satz-Ziel und fügen Sie dann Stilbeschreibungen oder Kamera-Hinweise nach Bedarf hinzu. Assets für den Encoder sind verpackt in Comfy-Org/Qwen-Image_ComfyUI.
TextEncodeQwenImageEditPlus (#106)#
Dieser Knoten bildet die negative Bedingung, um unerwünschte Merkmale zu verhindern. Fügen Sie kurze Phrasen hinzu, die Artefakte, Überglättung oder unpassende Stile blockieren. Halten Sie es minimal, um nicht gegen die positive Absicht zu kämpfen. Es verwendet denselben Qwen-Encoder und VAE-Stack wie der positive Pfad.
UnetLoaderGGUF (#102)#
Lädt den Qwen Image Edit 2509-Checkpoint im GGUF-Format für VRAM-freundliche Inferenz. Höhere Quantisierung spart Speicher, kann jedoch feine Details leicht beeinflussen; wenn Sie Spielraum haben, versuchen Sie eine weniger aggressive Quantisierung, um die Treue zu maximieren. Implementierungsreferenz: city96/ComfyUI-GGUF.
LoraLoaderModelOnly (#89)#
Wendet das Qwen-Image-Lightning LoRA auf das Basismodell an, um die Konvergenz zu beschleunigen und Bearbeitungen zu verstärken. Erhöhen Sie strength_model, um die Wirkung dieses LoRA zu betonen, oder senken Sie es für subtile Anleitungen. Modellseite: lightx2v/Qwen-Image-Lightning. Kernknotenreferenz: comfyanonymous/ComfyUI.
ImageScaleToTotalPixels (#93, #108)#
Skaliert jeden Eingang auf eine konsistente Gesamtpixelanzahl unter Verwendung hochwertiger Neuskalierung. Höhere Megapixel-Ziele liefern schärfere Ergebnisse auf Kosten von Zeit und Speicher; niedrigere beschleunigen die Iteration. Halten Sie beide Referenzen auf ähnlichen Skalen, um Qwen Image Edit 2509 zu helfen, Elemente sauber zu mischen. Kernknotenreferenz: comfyanonymous/ComfyUI.
KSampler (#3)#
Führt die Diffusionsschritte aus, die die latente Leinwand gemäß Ihren Bedingungen transformieren. Passen Sie Schritte und Sampler an, um Geschwindigkeit und Treue auszubalancieren, und variieren Sie den Seed, um mehrere Kompositionen aus demselben Setup zu erkunden. Für enge Bearbeitungen, die die Struktur von Bild 2 bewahren, halten Sie die Schrittzahlen moderat und verlassen Sie sich auf den Prompt und die Referenzen für die Kontrolle. Kernknotenreferenz: comfyanonymous/ComfyUI.
Optionale Extras#
- Behandeln Sie Bild 2 als Leinwand und Bild 1 als Spender; beschreiben Sie im Prompt, welche Elemente übertragen und welche bleiben sollen.
- Verwenden Sie prägnante Negative, um Halos, Texturdrift oder Überstilisierung zu zügeln; lange Negativlisten können Ihrem Ziel widersprechen.
- Wenn die Ergebnisse zu konservativ aussehen, erhöhen Sie die LoRA-Stärke oder die Samplingschritte leicht; wenn sie sich zu weit von der Basis entfernen, reduzieren Sie sie.
- Erhöhen Sie das Megapixel-Ziel beim Finalisieren und verwenden Sie dann denselben Seed, um die genaue Komposition zu skalieren, die Ihnen gefallen hat.
- Halten Sie Prompts konkret: Subjekt, Aktion, Umgebung und Stil. Qwen Image Edit 2509 reagiert am besten auf klare Absichten mit wenigen starken Beschreibungen.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken RobbaW für den Qwen Image Edit 2509 Workflow für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- RobbaW/Qwen Image Edit 2509 Workflow
- Hugging Face: QuantStack/Qwen-Image-Edit-2509-GGUF
- Dokumentation / Release Notes: Qwen Image Edit 2509 Workflow @RobbaW von Reddit r/comfyui
Hinweis: Die Verwendung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.

