
Qwen Image LoRA Inferenz: training-abgestimmte AI Toolkit-Inferenz in ComfyUI#
Qwen Image LoRA Inferenz ist ein produktionsbereiter RunComfy-Workflow zur Anwendung einer AI Toolkit-trainierten LoRA auf Qwen Image in ComfyUI mit training-abgestimmtem Verhalten. Es konzentriert sich auf RC Qwen Image (RCQwenImage)—einen von RunComfy gebauten, quelloffenen benutzerdefinierten Knoten (source), der eine Qwen Image-spezifische Inferenz-Pipeline betreibt (kein generisches Sampler-Diagramm) und Ihren Adapter über lora_path und lora_scale einfügt.
Warum Qwen Image LoRA Inferenz oft in ComfyUI anders aussieht#
AI Toolkit-Vorschauen werden durch eine modellspezifische Inferenz-Pipeline produziert, mit Qwen Image’s eigener Konditionierungs- und Leitimplementierung. Wenn Sie das Qwen Image-Sampling als generisches ComfyUI-Diagramm neu erstellen, ändern Sie oft die Pipeline-Standards (und die genaue Route, wo die LoRA angewendet wird), sodass dieselbe Eingabe/Ausgabe/Seed immer noch abweichen kann. Wenn die Ausgaben nicht übereinstimmen, ist es normalerweise eine Pipeline-Ebene-Mismatch—nicht ein einzelner „falscher Knopf“.
Was der RCQwenImage benutzerdefinierte Knoten macht#
RCQwenImage umhüllt die Qwen Image-Inferenz in einer vorschau-abgestimmten Pipeline und wendet Ihre AI Toolkit LoRA innerhalb dieser Pipeline über lora_path / lora_scale an, sodass das Sampling-Verhalten für diese Modellfamilie konsistent bleibt. Referenzimplementierung: `src/pipelines/qwen_image.py`.
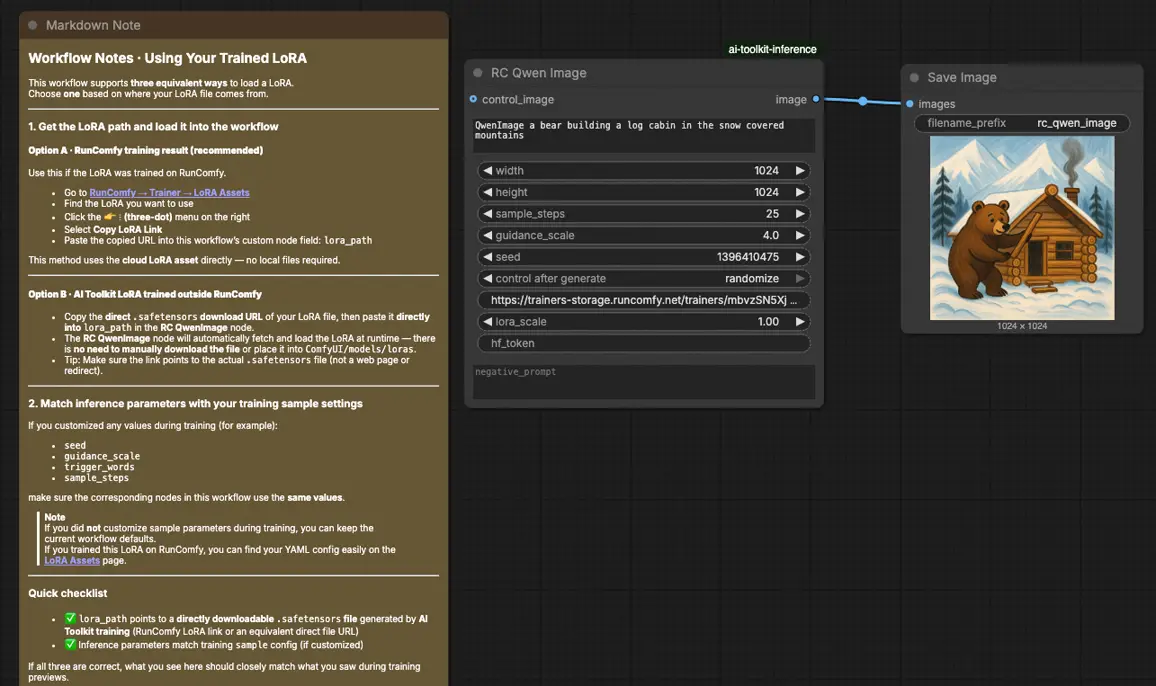
Wie man den Qwen Image LoRA Inferenz-Workflow verwendet#
Schritt 1: Öffnen Sie den Workflow#
Öffnen Sie den cloud-gespeicherten Workflow in ComfyUI
Schritt 2: Importieren Sie Ihre LoRA (2 Optionen)#
- Option A (RunComfy Trainingsergebnis): RunComfy → Trainer → LoRA Assets → finden Sie Ihre LoRA → ⋮ → Kopieren Sie den LoRA-Link

- Option B (AI Toolkit LoRA außerhalb von RunComfy trainiert): Kopieren Sie einen direkten
.safetensorsDownload-Link für Ihre LoRA und fügen Sie diese URL inlora_pathein (es ist nicht notwendig, sie inComfyUI/models/lorasherunterzuladen)
Schritt 3: Konfigurieren Sie den RCQwenImage benutzerdefinierten Knoten für die Qwen Image LoRA Inferenz#
Setzen Sie die restlichen Knotenparameter (diese müssen mit dem übereinstimmen, was Sie für das AI Toolkit-Vorschau-Sampling verwendet haben, wenn Sie Ergebnisse vergleichen):
prompt: Ihre Texteingabe (fügen Sie dieselben Trigger-Tokens hinzu, die Sie während des Trainings verwendet haben, falls vorhanden)negative_prompt: optional; lassen Sie es leer, wenn Sie keine negativen in Ihren Trainingsvorschauen verwendet habenwidth/height: Ausgabeauflösung (Vielfache von 32 werden für Qwen Image empfohlen)sample_steps: Anzahl der Inferenzschritte, die von der Qwen Image-Pipeline verwendet werdenguidance_scale: Leitstärke (Qwen Image verwendet eine „echte CFG“-Skala; beginnen Sie, indem Sie Ihren Vorschauwert spiegeln, bevor Sie Anpassungen vornehmen)seed: fester Seed für Wiederholbarkeit; ändern Sie es nur, nachdem Sie die Basislinie validiert habenlora_scale: LoRA-Stärke (beginnen Sie mit Ihrer Vorschau-Stärke, dann in kleinen Schritten anpassen)
Training-Ausrichtungs-Hinweis: Wenn Sie Ihre Trainingsmuster-Einstellungen angepasst haben, öffnen Sie Ihre AI Toolkit-Trainings-YAML und spiegeln Sie width, height, sample_steps, guidance_scale und seed. Wenn Sie auf RunComfy trainiert haben, verwenden Sie Trainer → LoRA Assets → Config, um dieselben Vorschauwerte in RCQwenImage zu kopieren.

Schritt 4: Führen Sie die Qwen Image LoRA Inferenz aus#
Stellen Sie den Workflow in die Warteschlange, dann führen Sie ihn aus. Der SaveImage-Knoten schreibt das generierte Bild in Ihr Standard-ComfyUI-Ausgabeverzeichnis.
Fehlerbehebung bei der Qwen Image LoRA Inferenz#
Die meisten Probleme, die Menschen nach dem Training einer Qwen Image LoRA im Ostris AI Toolkit und dann versuchen, sie in ComfyUI auszuführen, haben, kommen auf Pipeline + LoRA-Injektions-Mismatch zurück.
Der von RunComfy entwickelte RC Qwen Image (RCQwenImage) benutzerdefinierte Knoten ist darauf ausgelegt, die Inferenz pipeline-aligned mit AI Toolkit-Vorschau-Sampling zu halten, indem er eine Qwen Image-spezifische Inferenz-Pipeline (kein generisches Sampler-Diagramm) betreibt und Ihren Adapter über lora_path / lora_scale innerhalb dieser Pipeline injiziert.
(1)Qwen-Image Loras funktionieren nicht in comfyui#
Warum dies passiert
Dies wird häufig entweder als gemeldet:
- viele
lora key not loadedWarnungen, und/oder - die LoRA „läuft“, aber die Ausgabe ändert sich nicht so, wie sie es beim AI Toolkit-Sampling tat.
In der Praxis haben Benutzer festgestellt, dass dies oft daher kommt, dass ComfyUI nicht auf einem Build ist, der die neueste Qwen LoRA-Schlüsselzuordnung enthält, oder dass die LoRA durch einen generischen Pfad geladen wird, der nicht den von der Workflow verwendeten Qwen Image-Modulnamen entspricht.
Wie man es behebt
- Wechseln Sie ComfyUI auf den „nightly / development“ Kanal und aktualisieren Sie, dann führen Sie denselben Workflow erneut aus. Mehrere Benutzer berichteten, dass dies
lora key not loadedSpam entfernt und Qwen‑Image LoRAs korrekt anwendet. - Verwenden Sie RCQwenImage und übergeben Sie die LoRA nur über
lora_path/lora_scale(vermeiden Sie es, zusätzliche LoRA-Lader-Knoten darüber zu stapeln). RCQwenImage hält den pipeline-level LoRA-Injektionspunkt konsistent mit AI Toolkit-ähnlicher Inferenz. - Beim Vergleich mit AI Toolkit-Vorschauen spiegeln Sie die Vorschau-Sampler-Werte exakt:
width,height,sample_steps,guidance_scale,seed, undlora_scale.
(2)Qwen Bildgenerierung und Qualitätsausgabeproblem mit dem Qwen lighting 8 Schritte Lora#
Warum dies passiert
Leute berichten, dass nach dem Aktualisieren von ComfyUI die Qwen Image-Ausgaben verzerrt oder „seltsam“ werden und die Konsole lora key not loaded für die Lightning 8-Schritt LoRA zeigt—was bedeutet, dass die Geschwindigkeits/Qualitäts-LoRA wahrscheinlich nicht wirklich angewendet wird, obwohl ein Bild immer noch erzeugt wird.
Wie man es behebt (benutzerverifiziert + training-abgestimmt)
- Wechseln Sie zu ComfyUI nightly und aktualisieren Sie. Dies ist die am häufigsten berichtete Lösung für
lora key not loadedmit Qwen‑Image Lightning LoRAs. - Wenn Sie den nativen Comfy Workflow verwenden, berichteten Benutzer über Erfolg, indem sie
LoraLoaderModelOnlyzwischen den Modelllade- und Modellsampling-Knoten auf dem neuesten Nightly einfügten. - Für das Training-Vorschau-Matching (AI Toolkit) validieren Sie zunächst durch RCQwenImage (pipeline-aligned), dann passen Sie nur
lora_scalean, nachdem die Basislinie übereinstimmt.
(3)Qwen Image Charakter LoRA sieht anders aus als Training Samples#
Warum dies passiert
Ein häufiges Bericht ist: AI Toolkit Trainingsbeispiele sehen gut aus, aber in ComfyUI hat die LoRA „wenig bis keinen Einfluss“. Für Qwen Image bedeutet dies normalerweise entweder:
- die LoRA wird nicht wirklich angewendet (oft begleitet von
lora key not loaded/ veraltete Qwen-Unterstützung), oder - die LoRA wird durch einen Graphen/Lader-Pfad geladen, der nicht mit dem übereinstimmt, wie Qwen Image erwartet, dass Module gepatcht werden.
Wie man es behebt (benutzerverifiziert + training-abgestimmt)
- Validieren Sie die LoRA über RCQwenImage (einzelknoten, pipeline-aligned Injektion über
lora_path/lora_scale). Wenn der LoRA-Effekt hier auftaucht, aber nicht in Ihrem manuellen Diagramm, haben Sie ein Pipeline/Lader-Mismatch anstelle eines Trainingsfehlers bestätigt. - Wenn Sie AI Toolkit-Vorschau-Beispiele abgleichen, ändern Sie nicht Auflösung/Schritte/Leitung/Seed während der Diagnose. Passen Sie zuerst die Vorschau-Sampler-Werte an, dann justieren Sie
lora_scalein kleinen Schritten.
Führen Sie jetzt die Qwen Image LoRA Inferenz aus#
Öffnen Sie den RunComfy Workflow, setzen Sie lora_path, und führen Sie RCQwenImage aus, um die Qwen Image LoRA-Inferenz in ComfyUI mit Ihren AI Toolkit-Trainingsvorschauen abzustimmen.
