
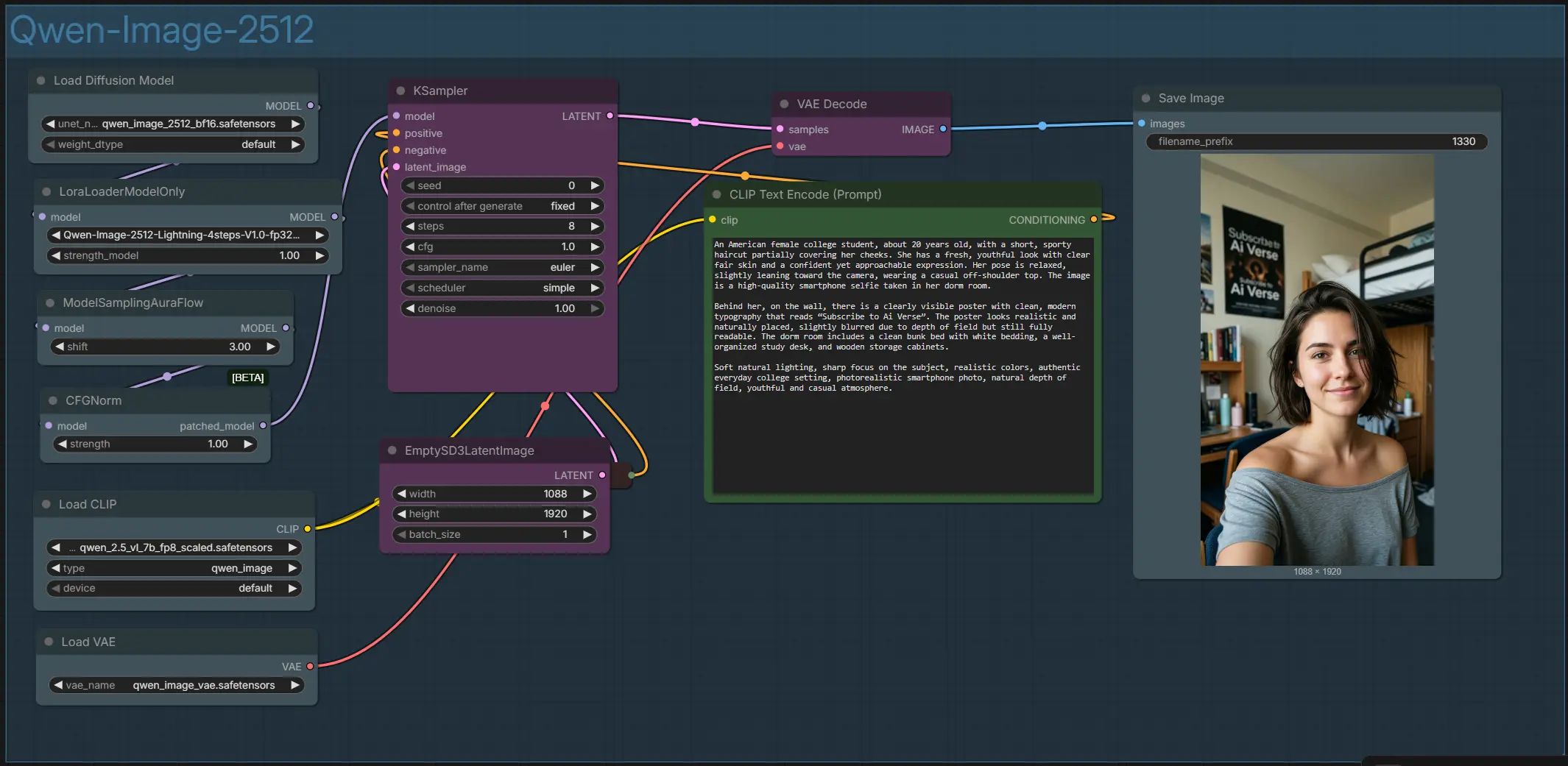






Qwen Image 2512 ComfyUI Workflow für textgenaue Porträts und Szenen#
Dieser Workflow verwandelt Ihr Prompt in ein hochauflösendes Bild mit Qwen Image 2512. Er ist für Kreative konzipiert, die eine starke Text-Bild-Ausrichtung, realistische Menschen und zuverlässige zweisprachige Textrenderings innerhalb der Szene benötigen. Der Graph ist mit Qwens VAE und Textencoder vorverkabelt, plus einer optionalen Lightning LoRA für die Generierung in wenigen Schritten, sodass Sie mit minimalem Setup vom Prompt zum Ergebnis gelangen können.
Verwenden Sie es für Konzeptkunst, Illustration, Beschilderung, Poster und alltägliche Fotostile. Qwen Image 2512 bietet stabile Kompositionen und klare Typografie, was es zu einer soliden Wahl für Prompts macht, die Menschen, Umgebungen und lesbaren Text mischen.
Schlüsselmodelle im Comfyui Qwen Image 2512 Workflow#
- Qwen-Image 2512 Basismodell (bfloat16). Kern-Diffusionsmodell, das das Bild aus der Bedingung synthetisiert. Die Comfy-Org-Paket bereitgestellten Gewichte sind Comfy-bereit. Modelldateien
- Qwen2.5-VL 7B Textencoder. Kodiert Ihr Prompt in Bedingungsvektoren, die das Layout, den Stil und die Textrendering von Qwen Image 2512 steuern. Textencoder-Dateien
- Qwen Image VAE. Dekodiert das vom Sampler erzeugte Latent zurück in ein RGB-Bild mit originalgetreuer Farbe und Detailgenauigkeit. VAE-Datei
- Qwen-Image-2512-Lightning-4steps-V1.0 LoRA (optional). Eine Community-LoRA, die für die Generierung in wenigen Schritten optimiert wurde, um die Wiedergabe mit geringfügigen Qualitätskompromissen zu beschleunigen. LoRA-Karte
- Für Hintergrundinformationen zur Modelfamilie und zum Trainingsansatz siehe den technischen Bericht zu Qwen-Image. Paper
Wie man den Comfyui Qwen Image 2512 Workflow verwendet#
Gesamtfluss: Ihr Prompt wird kodiert, eine latente Leinwand wird in der gewählten Auflösung erstellt, der Modellstapel wendet das Basismodell und die optionale LoRA an, der Sampler iteriert, um das Latent zu verfeinern, und die VAE dekodiert das endgültige Bild zum Speichern.
- Qwen-Image-2512 Gruppenübersicht
- Der gesamte Graph ist in einer einzigen Gruppe namens „Qwen-Image-2512“ organisiert. Er verbindet den Textencoder, Modell- und LoRA-Stapel, Sampler-Helfer und VAE-Dekodierung. Sie steuern das Aussehen mit positiven und negativen Prompts, Leinwandgröße und einigen Sampler-Einstellungen. Das Ergebnis ist ein hochauflösendes Porträt-Stilbild, das in Ihrem ComfyUI-Ausgabeverzeichnis gespeichert wird.
- Prompts mit
CLIPTextEncode(#52) und optionalen NegativenCLIPTextEncode(#32)- Geben Sie Ihre Hauptbeschreibung in
CLIPTextEncode(#52) ein. Schreiben Sie die Szene, die Subjekte und jeden in das Bild einzufügenden Text; Qwen Image 2512 ist besonders stark bei Beschilderungen, Postern, UI-Mockups und zweisprachigen Untertiteln. Verwenden SieCLIPTextEncode(#32) für optionale Negative, um Artefakte oder unerwünschte Stile zu vermeiden. Halten Sie Textschnipsel in Anführungszeichen, wenn Sie präzise Formulierungen benötigen.
- Geben Sie Ihre Hauptbeschreibung in
- Leinwand und Seitenverhältnis mit
EmptySD3LatentImage(#57)- Wählen Sie hier Ihre Zielbreite und -höhe, um die Komposition festzulegen. Porträtformate eignen sich gut für Menschen und Selfies, während quadratische und Landschaftsverhältnisse für Produkt- und Szenenlayouts geeignet sind. Größere Leinwände bieten feinere Details auf Kosten von Speicher und Zeit; beginnen Sie bescheiden und skalieren Sie hoch, sobald Ihnen die Rahmung gefällt. Die Konsistenz verbessert sich, wenn Sie dasselbe Seitenverhältnis über Iterationen beibehalten.
- Modell- und LoRA-Stapel mit
UNETLoader(#100) undLoraLoaderModelOnly(#101)- Der Basisgenerator ist Qwen Image 2512, geladen von
UNETLoader(#100). Wenn Sie schnellere Renderings wünschen, aktivieren Sie das Lightning LoRA inLoraLoaderModelOnly(#101), um zu einem Workflow in wenigen Schritten zu wechseln. Dieser Stapel legt die Fähigkeiten des Modells für Realismus, Layout und Text-Bild-Ausrichtung fest, bevor das Sampling beginnt.
- Der Basisgenerator ist Qwen Image 2512, geladen von
- Sampling-Helfer mit
ModelSamplingAuraFlow(#43) undCFGNorm(#55)- Diese beiden Knoten bereiten das Modell für stabiles, kontrastausgewogenes Sampling vor.
ModelSamplingAuraFlow(#43) passt den Zeitplan an, um Details scharf zu halten, ohne Texturen zu überkochen.CFGNorm(#55) normalisiert die Führung, um konsistente Farben und Belichtung zu gewährleisten, während Ihr Prompt befolgt wird.
- Diese beiden Knoten bereiten das Modell für stabiles, kontrastausgewogenes Sampling vor.
- Denoising und Verfeinerung mit
KSampler(#54)- Dies ist die Arbeitspferd-Phase, die das Latent iterativ von Rauschen zu einem kohärenten Bild verbessert. Sie legen den Seed für Wiederholbarkeit fest, wählen den Sampler und Planer aus und entscheiden, wie viele Schritte ausgeführt werden sollen. Mit aktiviertem Lightning können Sie auf wenige Schritte abzielen; mit dem Basismodell allein verwenden Sie mehr Schritte für maximale Treue.
- Dekodieren und Speichern mit
VAEDecode(#45) undSaveImage(#117)- Nach dem Sampling rekonstruiert die VAE sauber RGB aus dem Latent und
SaveImageschreibt das endgültige PNG. Wenn Farben oder Kontrast nicht stimmen, überarbeiten Sie die Führung oder die Prompt-Formulierung anstatt der Nachbearbeitung; Qwen Image 2512 reagiert gut auf beschreibende Beleuchtungs- und Materialhinweise.
- Nach dem Sampling rekonstruiert die VAE sauber RGB aus dem Latent und
Schlüssel-Knoten im Comfyui Qwen Image 2512 Workflow#
UNETLoader(#100)- Lädt das Qwen-Image-2512 Basismodell, das die Gesamtfähigkeit und den Stilraum bestimmt. Verwenden Sie den bf16-Build für maximale Qualität, wenn Ihr GPU dies zulässt. Wechseln Sie nur dann zu einer fp8- oder komprimierten Variante, wenn Sie Speicher passen oder den Durchsatz erhöhen müssen.
LoraLoaderModelOnly(#101)- Wendet die Qwen-Image-2512-Lightning-4steps-V1.0 LoRA über dem Basismodell an. Erhöhen oder verringern Sie
strength_model, um die Geschwindigkeitsoptimierung mit der Basisqualität zu mischen, oder setzen Sie es auf 0, um es zu deaktivieren. Wenn diese LoRA aktiv ist, reduzieren Sie diestepsinKSamplerauf wenige Iterationen, um die Beschleunigung zu realisieren.
- Wendet die Qwen-Image-2512-Lightning-4steps-V1.0 LoRA über dem Basismodell an. Erhöhen oder verringern Sie
ModelSamplingAuraFlow(#43)- Patcht das Sampling-Verhalten des Modells für einen flow-artigen Zeitplan, der oft schärfere Kanten und weniger Verschmierungen ergibt. Wenn die Ergebnisse übergeschärft oder unterdetailliert aussehen, passen Sie den
shift-Parameter leicht an und resampeln Sie. Halten Sie andere Variablen stabil, während Sie testen, um den Effekt zu isolieren.
- Patcht das Sampling-Verhalten des Modells für einen flow-artigen Zeitplan, der oft schärfere Kanten und weniger Verschmierungen ergibt. Wenn die Ergebnisse übergeschärft oder unterdetailliert aussehen, passen Sie den
CFGNorm(#55)- Normalisiert die classifier-freie Führung, um ausgewaschene oder übermäßig gesättigte Ausgaben zu verhindern. Verwenden Sie
strength, um zu entscheiden, wie durchsetzungsstark die Normalisierung wirken soll. Wenn die Textgenauigkeit sinkt, wenn Sie die CFG erhöhen, erhöhen Sie die Normalisierungsstärke anstatt die CFG weiter zu erhöhen.
- Normalisiert die classifier-freie Führung, um ausgewaschene oder übermäßig gesättigte Ausgaben zu verhindern. Verwenden Sie
EmptySD3LatentImage(#57)- Legt die Größe der latenten Leinwand fest, die Rahmung und Seitenverhältnis definiert. Für Menschen reduzieren Porträtverhältnisse Verzerrungen und helfen bei Körperproportionen; für Poster betonen quadratische oder Landschaftsverhältnisse Layout und Textblöcke. Erhöhen Sie die Auflösung erst, nachdem Sie mit der Komposition zufrieden sind.
CLIPTextEncode(#52) undCLIPTextEncode(#32)- Der positive Encoder (#52) verwandelt Ihre Beschreibung in eine Bedingung, einschließlich expliziter Textstrings, die in der Szene gerendert werden sollen. Der negative Encoder (#32) unterdrückt unerwünschte Eigenschaften wie Artefakte, zusätzliche Finger oder störende Hintergründe. Halten Sie Prompts prägnant und sachlich für die beste Ausrichtung.
KSampler(#54)- Steuert Seed, Sampler, Planer, Schritte, CFG und Denoise-Stärke. Mit Qwen Image 2512 bewahren moderate CFG-Werte typischerweise die starke Textausrichtung des Modells; wenn Buchstaben verzerren, senken Sie die CFG, bevor Sie den Sampler ändern. Für schnelle Entwürfe aktivieren Sie Lightning und versuchen Sie sehr wenige Schritte, dann erhöhen Sie die Schritte für endgültige Renderings, wenn nötig.
VAELoader(#34) undVAEDecode(#45)- Laden und anwenden von Qwens VAE, um originalgetreue Farben und feine Details zu rekonstruieren. Halten Sie die VAE mit dem Basismodell gepaart, um Farbverschiebungen zu vermeiden. Wenn Sie Basisgewichte wechseln, wechseln Sie auch zum passenden VAE-Build.
Optionale Extras#
- Prompting für in-Bild-Text
- Setzen Sie genaue Worte in gerade Anführungszeichen und fügen Sie kurze Typografiehinweise wie „saubere moderne Typografie“ oder „fette serifenlose Schrift“ hinzu. Inkludieren Sie Platzierungshinweise wie „Wandposter“ oder „Schaufensterschild“, um zu verankern, wo der Text erscheinen soll.
- Schnellere Iteration mit Lightning
- Aktivieren Sie das Lightning LoRA und verwenden Sie wenige Schritte für Vorschauen. Sobald Rahmung und Formulierung korrekt sind, deaktivieren oder reduzieren Sie die LoRA-Stärke und erhöhen Sie die Schritte, um maximale Treue wiederherzustellen.
- Seitenwahloptionen
- Halten Sie sich an konsistente Verhältnisse über Varianten hinweg. Verwenden Sie Porträt für Menschen, Quadrat für Produkt- oder Logostudien und Landschaft für Umgebungen oder Folien. Wenn Sie später hochskalieren, behalten Sie das gleiche Verhältnis bei, um die Komposition zu erhalten.
- Disziplin bei der Führung
- Qwen Image 2512 bevorzugt normalerweise eine moderate CFG. Wenn die Texttreue nachlässt, senken Sie die CFG oder erhöhen Sie die
CFGNorm-Stärke, anstatt mehr Führung hinzuzufügen.
- Qwen Image 2512 bevorzugt normalerweise eine moderate CFG. Wenn die Texttreue nachlässt, senken Sie die CFG oder erhöhen Sie die
- Reproduzierbarkeit
- Sperren Sie einen Seed, wenn Ihnen ein Ergebnis gefällt, damit Sie sicher iterieren können. Ändern Sie eine Steuerung nach der anderen, um ihren Einfluss zu verstehen, bevor Sie weitergehen.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Comfy-Org für die Qwen Image 2512 Model Files für ihre Beiträge und Pflege. Für autoritative Details verweisen wir auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- Comfy-Org/Qwen Image 2512 Model Files
- Hugging Face: Comfy-Org/Qwen-Image_ComfyUI
- Dokumentation / Versionshinweise: Qwen Image 2512 Model Files
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Wartungspersonen bereitgestellt werden.